
Data Science Meets Politics
Unraveling congressional dynamics With networks

Who Understands Politicians?
Few groups of people can be as challenging to understand as members of a National Congress. In almost any country in the world, the figure of the hypocritical politician is infamous among the population. Backroom dealings and beige envelopes are ever-present in political drama series. At the same time, they are one of the most crucial groups to comprehend, as their actions directly impact the country’s future.
To understand Congress, I will base myself on the popular saying — judge people by their actions, not words. Therefore, I will compare and group members of Congress based on their voting history. In this way, we can uncover obscure patterns and understand the true dynamic of a National Congress.
For this project, I will focus on my home country’s National Congress — Brazil’s Camara dos Deputados — but the method can be applied to any country.
Gathering Data
First of all, we need data.
I downloaded data on all the laws voted on and how each member of Congress voted from 2023 to 2024 up to May 18th. All the data is available at the Brazilian Congress’s open data portal. I then created two different pandas dataframes, one with all the laws voted on and another with how each congress member voted in each vote.
votacoes = pd.concat([pd.read_csv('votacoes-2023.csv', header=0, sep=';'), pd.read_csv('votacoes-2024.csv', header=0, sep=';')])
votacoes_votos_dep = pd.concat([pd.read_csv('votacoesVotos-2023.csv', sep=';', quoting=1) , pd.read_csv('votacoesVotos-2024.csv', sep=';', on_bad_lines='warn', quoting=1, encoding='utf-8')])
To the votacoes dataframe, I selected only the entries with idOrgao of 180, which means they were voted in the main chamber of Congress. So, we have the data for the votes of most congress members. Then I used this the list of the votacoes_Ids to filter the votacoes_votos_dep dataframe.
plen = votacoes[votacoes['idOrgao'] == 180]
votacoes_ids = plen['id'].unique()
votacoes_votos_dep = votacoes_votos_dep[votacoes_votos_dep['idVotacao'].isin(votacoes_ids)]
Now, in the votacoes_votos_dep, each vote is a row with the congress member’s name and the voting session ID to identify who and what the vote refers to. Therefore, I created a pivot table so that each row represents a congress member and each column refers to a vote, encoding Yes as 1 and No as 0 and dropping any vote where more than 280 deputies didn’t vote.
votacoes_votos_dep['voto_numerico'] = votacoes_votos_dep['voto'].map({'Sim': 1, 'Não':0})
votes_pivot = votacoes_votos_dep.pivot_table(index='deputado_nome', columns='idVotacao', values='voto_numerico').dropna(axis=1, thresh=280)
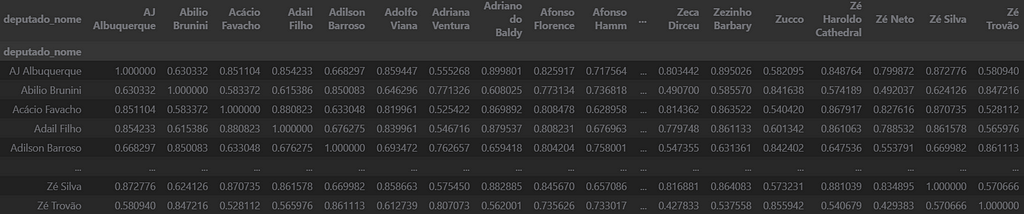
Before computing the similarity matrix, I filled all remaining NAs with 0.5 so as not to interfere with the positioning of the congress member. Finally, we compute the similarity between the vectors of each deputy using cosine similarity and store it in a dataframe.
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(votes_pivot)
similarity_df = pd.DataFrame(similarity_matrix, index=votes_pivot.index, columns=votes_pivot.index)
Constructing the Congress Network Graph
Now, use the information about the voting similarities between congressmen to build a network using Networkx. A node will represent each member.
import networkx as nx
names = similarity_df.columns
# Create the graph as before
G = nx.Graph()
for i, name in enumerate(names):
G.add_node(name)
Then, the edges connecting two nodes represent a similarity of at least 75% of the two congressmen’s voting behavior. Also, to address the fact that some congress members have dozens of peers with high degrees of similarity, I only selected the first 25 congressmen with the highest similarity to be given an edge.
threshold = 0.75
for i in range(len(similarity_matrix)):
for j in range(i + 1, len(similarity_matrix)):
if similarity_matrix[i][j] > threshold:
# G.add_edge(names[i], names[j], weight=similarity_matrix[i][j])
counter[names[i]].append((names[j], similarity_matrix[i][j]))
for source, target in counter.items():
selected_targets = sorted(target, key=lambda x: x[1], reverse=True)[:26]
for target, weight in selected_targets:
G.add_edge(source, target, weight=weight)
To visualize the network, you need to decide the position of each node in the plane. I decided to use the spring layout, which uses the edges as springs holding nodes close while trying to separate. Adding a seed allows for reproducibility since it is a random process.
pos = nx.spring_layout(G, k=0.1, iterations=50, seed=29)
Finally, we plot the network using a Go figure and individually add the edges and nodes based on their position.
# Create Edges
edge_x = []
edge_y = []
for edge in G.edges():
x0, y0 = pos[edge[0]]
x1, y1 = pos[edge[1]]
edge_x.extend([x0, x1, None])
edge_y.extend([y0, y1, None])
# Add edges as a scatter plot
edge_trace = go.Scatter(x=edge_x, y=edge_y, line=dict(width=0.5, color='#888'), hoverinfo='none', mode='lines')
# Create Nodes
node_x = []
node_y = []
for node in G.nodes():
x, y = pos[node]
node_x.append(x)
node_y.append(y)
# Add nodes as a scatter plot
node_trace = go.Scatter(x=node_x, y=node_y, mode='markers+text', hoverinfo='text', marker=dict(showscale=True, colorscale='YlGnBu', size=10, color=[], line_width=2))
# Add text to the nodes
node_trace.text = list(G.nodes())
# Create a figure
fig = go.Figure(data=[edge_trace, node_trace],
layout=go.Layout(showlegend=False, hovermode='closest', margin=dict(b=0,l=0,r=0,t=0), xaxis=dict(showgrid=False, zeroline=False, showticklabels=False), yaxis=dict(showgrid=False, zeroline=False, showticklabels=False)))
fig.show()
Result:
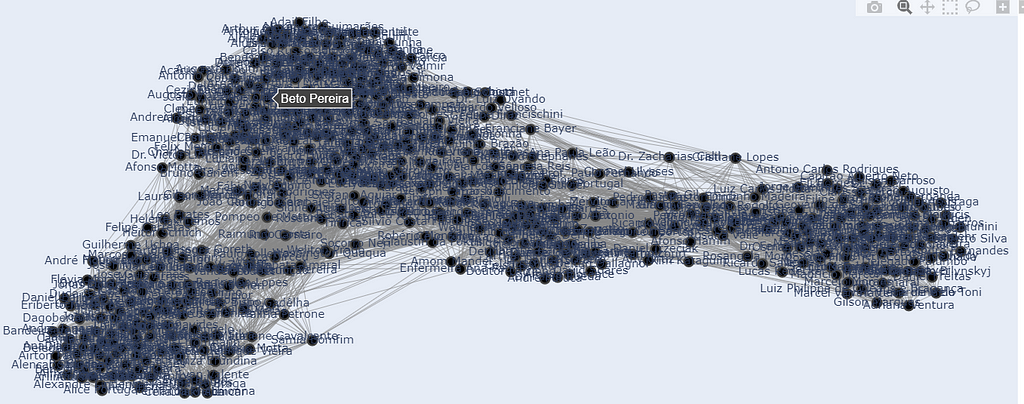
Well, it’s a good start. Different clusters of congressmen can be seen, which suggests that it accurately captures the political alignment and alliances in Congress. But it is a mess, and it is impossible to really discern what’s going on.
To improve the visualization, I made the name appear only when you hover over the node. Also, I colored the nodes according to the political parties and coalitions available on Congress’s site and sized them based on how many edges they are connected to.
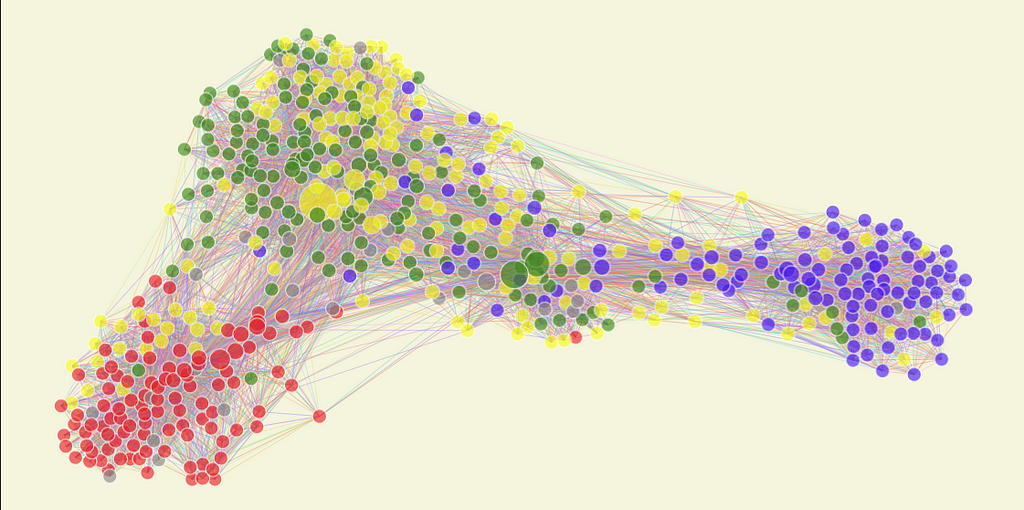
It’s a lot better. We have three clusters, with some nodes between them and a few bigger ones in each. Also, in each cluster, there is a majority of a particular color. Well, let’s dissect it.
Interpreting the Results
First of all, let me explain the colors. Red represents the base of the current left-wing government, so the congressmen of the party of the president or public allies, PT, PSOL, PCdoB, and others. Blue is the opposition led by PL, the party of the ex-president, and another right-wing party, NOVO.
Green and Yellow represent a phenomenon in Brazil’s politics called “Centrao” or “big center.” Centrao is compromised by non-aligned political parties that are always allied with the current government and trade their support for appointments to positions in government or public companies. The Yellow represents the group centered around UNIAO, Brazil’s biggest political party. Green is centered around MDB, a historical party that used to be in charge of most of the “Centrao.”
So, back to the graph:
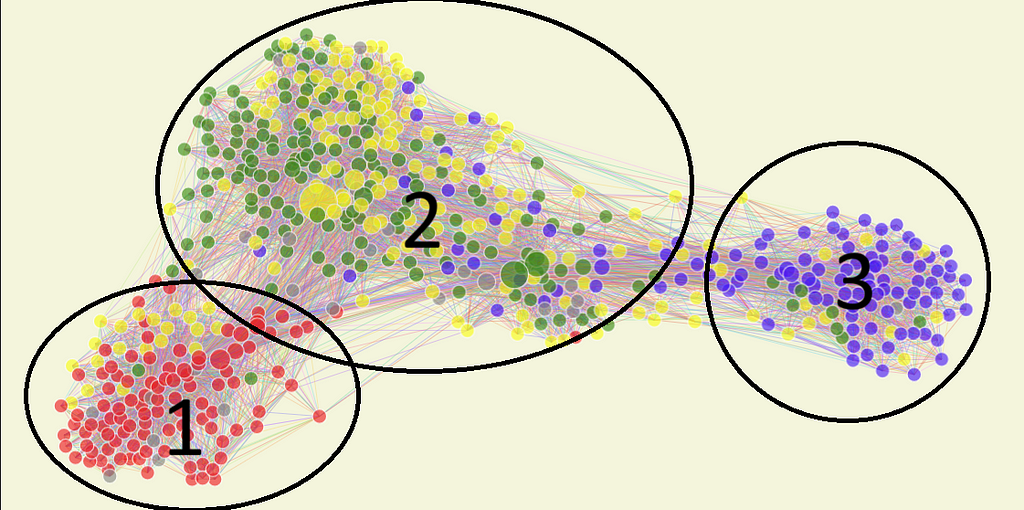
Group 1 seems to be mostly composed of red, the current government, and its closest allies. The yellow dots inside are mostly from AVNATE, which, despite publicly being in the same alliance as UNIAO, seems to be more politically aligned with the left.
Another interesting dynamic the network model captures is the grouping of specific parties and ideologies inside each more extensive community. In group 1, right below the base of the number 1, seven nodes are very close to each other. They represent the congress members from PSOL, a radical left party. It’s interesting to see that even inside the left-wing block, they are represented in a sort of sub-group in the network.
Group 2 seems to be mostly compromised from what we can call “Centrao,” as explained before. As always, they are part of the government’s base; they are closer to group 1 than 3, and we can see a mix of Green and yellow, as expected, and some Blue dots. That means many members of Congress who should be in the opposition vote similarly to the government. Why? Well, PL, the current “opposition” party, used to be an average “Centrao” party. Hence, historical members still behave like the average “Centrao”.
Notably, we have the biggest nodes in group 2. One is yellow and represents Waldemar Oliveira, the leader of the government in the house. He is relevant in Congress, as a big part of it votes according to his directives. The other two biggest nodes are also in group 2, but in what I call group 2.5.
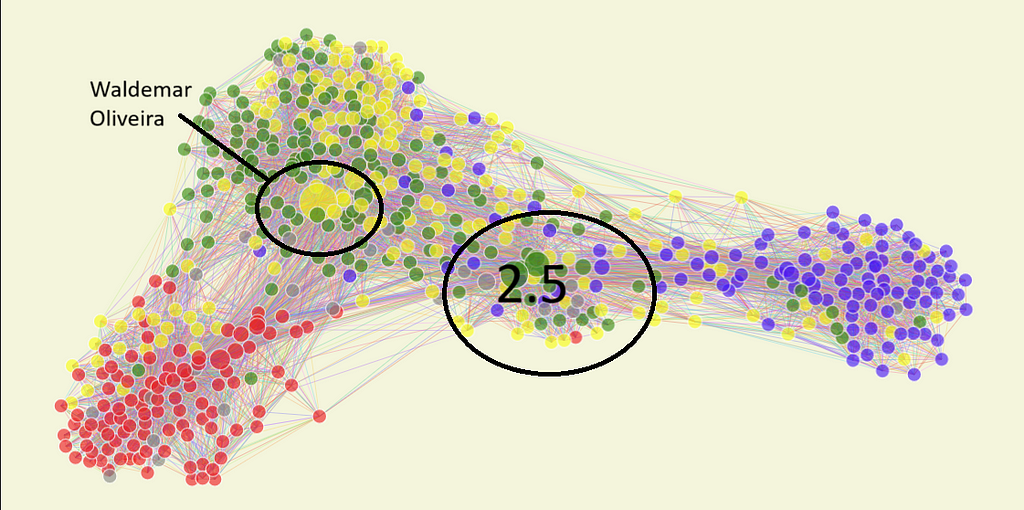
The reason behind Group 2.5’s behavior is beyond the article; to summarize, it is a group of congressmen who were elected identifying as “right-wing” but still behave more like “Centrao.” Only occasionally do they vote with the right, hence their proximity to Group 3, but whenever votes that interest Group 2 come up, they break away to vote with Group 2.
Finally, group 3 has a different distribution than the other two. It is the smallest one in Congress and is compromised overwhelmingly by PL deputies. It is more “spread out” as there are a lot of members between them and group 2, showing that they do not always vote together. At the same time, there are no oversized nodes, so no clear leader exerts influence on the whole block. This pattern makes sense and aligns with reality since the opposition hasn’t been able to achieve much success in the current Congress.
Conclusion
In conclusion, using networks to analyze the Brazilian Congress yielded valuable insights into political alignments and voting behaviors. Our visualization of voting patterns has revealed three distinct groups: the government’s base, the “Centrao,” and the opposition. The graph effectively illustrates the nuanced relationships between parties, exposing deviations from public stances and highlighting influential figures.
This data-driven approach enhances our understanding of political dynamics, providing a clear visual representation of the complex interplay within the legislative body. By utilizing such analytical tools, we can promote greater transparency in the political process and facilitate more informed discussions about a country’s political situation.
Now that the graph is ready, we can use it to answer questions like:
- When does the Centrao vote with the government or the opposition?
- Is there a connection between the importance of the network and spending on employees?
- Is there a correlation between alignment in the network and geographival location?
If you liked the article and want to read other insights about politics analyzed with data science, follow me here, and don’t miss out. Thank you for reading.
Let me know in the comments what you think of this methodology to analyze political dynamics and if I did anything wrong.
Data Science Meets Politics was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/oCdWEHD
via IFTTT


