
How to Get Pull Request Data Using GitHub API
Getting the diff between any two commits

GitHub is the Wikipedia of code. Not everything in GitHub can be taken for granted but it contains the essence and history of how some of the best software tools are created.
It’d be a shame not to have an API for accessing such a valuable resource. Thankfully, we do have one and it’s called, surprisingly, GitHub API.
Let me first mention what this article is not about. We won’t be talking about git comments or how to use git in software development.
This article is more about using GitHub API for analytical purposes. The first and foremost requirement for analytics is data and GitHub has lots of it.
The amount and variety of information we can get from GitHub API is simply amazing. Also, it’s a well maintained and documented API so we won’t have a hard time getting the information we need.
We can get lots of data from GitHub API such as:
- Commits per pull request
- Folder and file structure of a repository
- Average number of files edited per commit
- Developer-based data such as who pushed the most commits in the last month
- File-based data such as average length of files in a repo
There are lots of cool things we can do once we get the data. Let’s start with how to get access.
We need to obtain an access token first. Go to settings -> developer settings -> personal access tokens and click on generate new token.
Once you generate the token, make sure to copy and save it. You can use it however you’d like but the proper way is to save it as an environment variable and access it from there. It’s not recommended to have access keys written in your code.
Diff between different pull requests
Data we can obtain using the GitHub API is simply a lot. Thus, instead of listing all types of data provided by the API, I’ll try to build a use case and explain how we can get the required data for it.
When you push a commit, you can see the changes introduced in that commit. But, there might be cases where you’re interested in the changes in a longer time span. Given the sha values, GitHub API allows for getting the code changes between two pull requests. The sha value can be considered as an ID for the commit.
We’ll use the pandas library for the examples because it’s a highly popular open-source library and everyone has access to it.
On GitHub ui, you can copy the sha of a commit in the commits tab of a pull request (red box in the screenshot below):
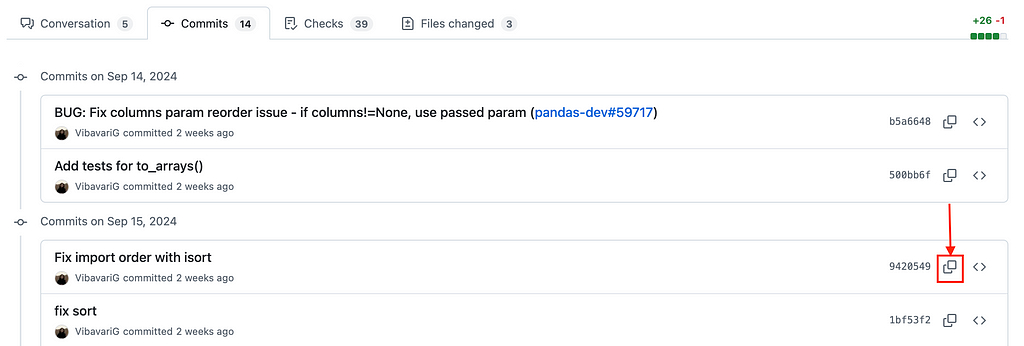
If you click on the “<>” (next to the red box in the screenshot above), GitHub will take you to the version of the repository in that commit. You can see the commit sha in the url of opened page:

Getting the commit sha using GitHub API
We’ve seen how to get the commit sha from the ui but we need to do it programmatically, which requires us to use the GitHub API.
We can use the commits endpoint to get the commit data of a pull request. Let’s do it for pull request #59809 in the pandas library.
# import libraries
import os
import requests
from dotenv import load_dotenv, find_dotenv
# load access token from env variables and create headers
_ = load_dotenv(find_dotenv())
access_token = os.getenv("GITHUB_PERSONAL_TOKEN")
HEADERS = {
'Authorization': f'token {access_token}',
'Accept': 'application/vnd.github.v3+json'
}
# repo and pull request data
owner = "pandas-dev"
repo = "pandas"
pull = 59809
# api url for commits endpoint
api_url = f"https://api.github.com/repos/{owner}/{repo}/pulls/{pull}/commits"
# request
response = requests.get(api_url, headers=HEADERS)
response_data = response.json()
The response_data is a list of json objects where each json contains the data for a commit. The sha key contains the commit sha so we can use the following list comprehension to create a list of commit sha values.
commit_sha_list = [commit.get("sha") for commit in response_data]
commit_sha_list
# output
['b5a6648cb928fee5fbac0580b6fe509e1251328b',
'500bb6f88f4066797a617a5a64ee47c1299e33ab',
'9420549449e6dbdad03054818122255678f9a250',
'1bf53f29a6de29f87170f07317b6bf55b7800ddb',
'7a054fbb0df03f4426132540829355d744488933',
'4b47b394d26f66368fdf4118d3d6b95c815aa818',
'b9e7af2a67fedc26692a57cf6122092c93380a88',
'a3d353f2bb63a3a56290b141713cf4f2ff78093e',
'35261c0f18cd933d2b19c1eb8f8d2c76de55f915',
'566ca76e3e31828544cdd58feddef6c0e9fe91d1',
'7c82e5b70a68b19c00d68b40b6c9d8c1262a7c27',
'0ccc362da1910b1b655952d10d3270a75a55fead',
'3eddd981c29916d953ce9d895402c2b0f109b0e4',
'f9d6b8ca22ef8acc62b984badb2ed00a08a34a86']
You can validate this from GitHub ui and see that pull request #59809 has 14 commits and sha values match the list above.
Getting the diff
Let’s say we want to get the diff between the third and last commit of this pull request.
third_commit = commit_sha_list[2]
last_commit = commit_sha_list[-1]
By the way, this approach can be extended to different pull requests (i.e. we can get the diff between commits in different pull requests). We just need the commit sha values.
We’ll use different endpoint and headers for this task.
DIFF_HEADERS = {
'Authorization': f'token {access_token}',
'Accept': 'application/vnd.github.v3.diff'
}
# api url for getting the diff
basehead = f"{third_commit}...{last_commit}"
diff_api_url = f"https://api.github.com/repos/{owner}/{repo}/compare/{basehead}"
# request
diff_response = requests.get(diff_api_url, headers=DIFF_HEADERS)
diff_data = diff_response.text
The diff response contains the changes in all the files in the following format:
diff --git a/doc/source/conf.py b/doc/source/conf.py
index 77dd5d03d311c..ddbda0aa3bf65 100644
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -254,7 +254,9 @@
"json_url": "https://pandas.pydata.org/versions.json",
"version_match": switcher_version,
},
- "show_version_warning_banner": True,
+ # This shows a warning for patch releases since the
+ # patch version doesn't compare as equal (e.g. 2.2.1 != 2.2.0 but it should be)
+ "show_version_warning_banner": False,
"icon_links": [
{
"name": "Mastodon",
This shows the changes in the doc/source/conf.py file.
We can do a lot of things with this data. It’s not in the most usable format but we can reformat it using some string operations. Let’s say I just need the diff associated with the doc/source/conf.py file. I can extract it from the diff response text as follows:
file_name = "doc/source/conf.py"
# split raw diff response where each split represents a file
diffs = diff_data.split("diff --git ")[1:]
# get the diff for the required file
file_diff = [diff for diff in diffs if file_name in diff]
print(file_diff[0])
# output
"""
a/doc/source/conf.py b/doc/source/conf.py
index 77dd5d03d311c..ddbda0aa3bf65 100644
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -254,7 +254,9 @@
"json_url": "https://pandas.pydata.org/versions.json",
"version_match": switcher_version,
},
- "show_version_warning_banner": True,
+ # This shows a warning for patch releases since the
+ # patch version doesn't compare as equal (e.g. 2.2.1 != 2.2.0 but it should be)
+ "show_version_warning_banner": False,
"icon_links": [
{
"name": "Mastodon",
"""
Final words
There are so many things we can do with data from a repository. It can be used for analytical purposes, debugging, or creating new software development practices.
In this article, we learned how to get the diff between two commits (not only commits in the same pull request but also between commits in different pull requests).
I’ll be writing more on using GitHub API and how to make use of the data. Thank you for reading and stay tuned for more to come.
How to Get Pull Request Data Using GitHub API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/bn9c8OQ
via IFTTT
