
How to Make Better Decisions with Diversity
Data Science in real life

Introduction
Decisions fuel business; without them, progress grinds to a halt. The difference between success and failure often boils down to the choices we make. In the realm of data science, decision-making takes centre stage, as algorithms sift through data to provide insights that drive action.
Interestingly, the everyday challenges faced by data scientists — such as bias in algorithms or the need for varied perspectives — mirror those encountered by businesses, governments, and organizations at large. Given how crucial decision-making is to business success, it’s surprising how little is borrowed from the field of data science.
In this article we are going to explore how we can use learnings from data science to improve decision making through diversity.
Data shows that organisations with greater gender diversity and ethnic diversity are likely to financially outperform other companies by 21% and 33% respectively [1].
However, how can we use diversity to improve our decision making? Can we demonstrate that a diverse team is able to make more effective decisions than a less diverse one?
In this article we will explore this in more detail, using algorithms from data science to explore how best to optimise decision-making in the real world.
Decision making in real life
To illustrate this point, let’s compare two decision-making ‘models’: one driven by an overconfident individual, our friend, Captain Certainty. The other is represented by the collective wisdom of a diverse ensemble: the interns.
Picture this:
Your screen flickers, and you’re plunged into the familiar world of the virtual office. Everyone is on mute, except for one person…
Captain Certainty is holding court. His bookshelf looms behind him, filled with books — titles like “How to Synergize Synergies”, “Leveraging Low-Hanging Fruit”, and “The Art of Pretending You’ve Read This” are perfectly aligned for maximum visibility. He’s sitting in front of a minimalist desk that looks like it belongs in a productivity blog, despite the fact that no one has ever actually seen him take notes.
The only breaks in his monologue are for occasional sips of coffee from a mug that reads ‘#1 thought leader’.

Naturally, everyone defers to his decisions. After all, he’s the ‘complex algorithm’ in this situation. But is that really the best approach..?
Also on the call we have the interns, each brilliant in their own area but all lacking experience:
- Lucy typically speaks for the group via Chatterbox, the office’s internal IM system. She’s constantly polling the team for opinions.
- Then there’s Sam, the tech enthusiast who’s always the first to suggest automation — though two weeks ago she accidentally set up an automatic email rule that wished everyone a “Happy Tuesday!” every morning and appears to be unaware that this is happening.
- Then there’s Intern #3… . Their camera has never worked, they’re always on mute, and their profile picture is a default grey silhouette. For all anyone knows, they could be a bot, occasionally typing “Great point!” in the chat just to maintain the illusion of participation. Maybe one day we’ll meet them — or maybe they’ve figured out remote work better than anyone else.
Halfway through the call we reach a key decision point. Captain Certainty quips (only individuals like Captain Certainty can ‘quip’):
“Been there, done that and I have the t-shirt, we clearly need to go in the same direction as before”.
But Lucy is not so sure, to her shock she sees three dots appear against Intern #3’s profile on Chatterbox.

Lucy is also not in agreement with Captain Certainty. So who is right? Who would you side with?
Framing the example as a machine learning problem
To a Data Scientist, it is easy to make parallels with the example above. Captain Certainty represents a complex algorithm, one which has access to a large amount of data (experience) and will apply these learnings when making new decisions.
The interns represent weak learners: individually they do not have the same level of experience as the Captain. However, they are diverse. Each has differing experiences and therefore opinions when it comes to decision making.
This is where things get really interesting: an ensemble of weak learners can outperform a more complex algorithm.
How can less be more?
How can this be the case? In our example Captain Certainty has more experience than all of the interns put together.
It turns out that Captain Certainty’s advantage is also his downfall. His wealth of experience and overconfidence also bring with it bias and overfitting. But what does this mean?
Let’s start with bias. Captain Certainty has a lot of experience, but that also means he’s developed strong opinions — or “biases” — about how things should work. This makes him blind to new information that doesn’t fit his worldview. For example, he’s still convinced fax machines are the future of communication, no matter how many emails you send.
Now, overfitting is a little sneakier. Captain Certainty’s deep knowledge means he can remember every little detail of the past — but sometimes that’s not helpful. For example, he may spent time memorizing the exact food orders at the last 50 team lunches and coming up with a way of predicting whether wraps or sandwiches will be served based on the time of day and number of attendees:
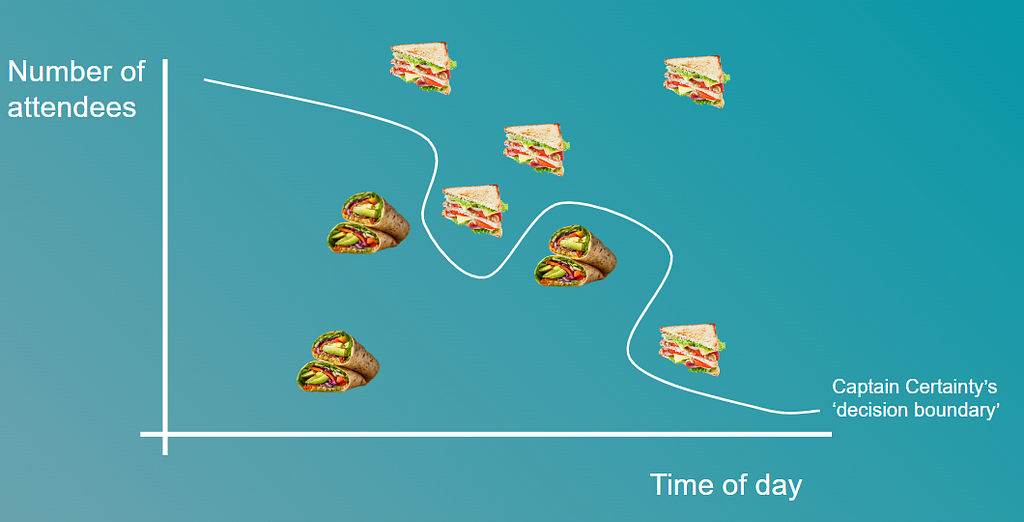
In data science, this is overfitting: when you get so good at remembering past patterns that you start seeing them even if they’re not relevant.
The interns, on the other hand, may not have his depth of experience, but they’re not bogged down by these assumptions. They can see the bigger picture and adapt more easily when things aren’t as predictable as Captain Certainty remembers.
A worked example
This is interesting, but how can we prove that this is the case?
Lets create a simple machine learning example in Python to demonstrate the power of the ensemble.
This is where things get a bit technical so if you are not particularly interested in the details, feel free to skip ahead — but be sure to re-join for the conclusion, where we’ll wrap everything up in plain English.
We use a real life dataset that provides demographic and financial information. We will use this to predict whether an individual would receive credit or not.
It is no accident that we have chosen this dataset for our example. Real-life decisions, like extending credit to individuals, carry significant weight. These choices can have a lasting, even life-changing impact on someone’s financial future. Whether approving a loan or denying credit, it’s essential that these decisions are made as effectively and fairly as possible, avoiding biases.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
# Load the Adult dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
columns = ['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation',
'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']
df = pd.read_csv(url, names=columns, na_values=' ?', skipinitialspace=True)
df.dropna(inplace=True)
# Encode categorical features
le = LabelEncoder()
for col in df.columns:
if df[col].dtype == 'object':
df[col] = le.fit_transform(df[col])
# Split the data
X = df.drop('income', axis=1)
y = df['income']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=42)
# Captain Certainty: A single, overconfident tree in the Random Forest
cpt_c = RandomForestClassifier(n_estimators=1, max_features=None, max_depth=100, random_state=42,bootstrap=False)
cpt_c.fit(X_train, y_train)
y_pred_cpt_c = cpt_c.predict(X_test)
print(f"Captain Certainty's Accuracy: {accuracy_score(y_test, y_pred_cpt_c):.2f}")
# The diverse team: A Random Forest with 3 trees
diverse_team = RandomForestClassifier(n_estimators=3, max_depth=10, random_state=42)
diverse_team.fit(X_train, y_train)
y_pred_team = diverse_team.predict(X_test)
print(f"Intern Team's Accuracy: {accuracy_score(y_test, y_pred_team):.2f}")
Captain Certainty’s Accuracy: 80%
Intern Team’s Accuracy: 85%
Here we have simulated Captain Certainty as a single, complex decision tree. We then have the three interns simulated as a random forest with 3 trees, one representing each of the interns. However these trees have been severely limited by the ‘max_depth’ parameter to reflect their limited experience.
Despite this, the three interns outperform the Captain in our example.
In fact, you could add more interns and see further performance gains, as long as they remain effective weak learners.
The definition of this is simple; any model that performs greater than random guessing.
Conclusion and real life take-aways
In this article we have learned:
- The sum of the parts can be greater than the whole when it comes to decision making.
- Experience brings with it potential problems with bias and overfitting.
- Diverse teams make better decisions.
However there are important points to consider when looking to apply this in real-life:
- Decision making needs to take account of everyone in the team. If opinions are ignored then the ensemble of ideas is no longer effective.
- Everyone in the group needs to be a weak learner. They should have enough knowledge and experience to be able to contribute to a decision in a way that is better than random guessing.
- Everyone in the group needs to be diverse. A collection of individuals with the same background and opinions will perform no better than a single person.
Further reading
If you do not like the idea of being a weak learner then why not jump to the article below to exercise your problem solving skills?
https://towardsdatascience.com/data-science-skills-101-how-to-solve-any-problem-2cb69e2e8aa1
References
[1] Diversity wins: How inclusion matters, Mckinsey 2020
How to Make Better Decisions with Diversity was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/0Kh2ZSC
via IFTTT


