
A Mixed-Methods Approach to Offline Evaluation of News Recommender Systems
Combining reader feedback from surveys with behavioral click data to optimize content personalization.

In digital news, the decision to click on an article is influenced by various factors. From headlines and trending topics to article placement and even a reader’s mood, the complexity behind news consumption is both fascinating and challenging. Considering these different influences leads us to a critical question: how much does a reader’s past behavior shape their current choices?
At DER SPIEGEL, we’re addressing this question as we develop a News Recommender System. Our goal is to deliver relevant content to readers at the right time. However, this objective comes with a challenge — how can we effectively evaluate and optimize our system before it goes live? Our solution is a mixed-methods approach to offline evaluation. By combining historical click data with news item preferences gathered through surveys, we’ve developed a methodology that aims to improve how we understand and predict reader behavior. Before we describe the details of this approach, it’s important to understand why traditional offline evaluation methods for news recommender systems can fall short.
The Challenge of Evaluating News Recommender Systems
Offline evaluation is a critical step in developing recommender systems. They help select the most promising algorithms and parameters before going live. By using historic click data of users, we can assess how well our recommender predicts the items that readers actually choose.[1] But evaluating news recommendation systems is challenging. Most news articles have a short shelf life and user preferences change rapidly based on current events. It’s also difficult to balance user interests, editorial priorities, and ethical considerations.
Conventional offline evaluations, which typically rely solely on historical click data, can fall short in capturing these factors. They can’t tell us if users actually liked the articles they clicked on, or if they might have preferred an article they didn’t click because they probably never saw it.[1] Moreover, classical approaches are often biased towards non-personalized, popularity-based algorithms.[2]
Nevertheless, offline experiments seem to be particularly appealing in the research and development phase. Academic research often relies solely on offline experiments, primarily because researchers rarely have access to productive systems for online testing.[3] Offline methods allow to compare a wide range of algorithms cost-effectively, without the need for real-time user interactions.[4] But it is also widely recognized, that online experiments offer the strongest evidence of a system’s performance, as they involve real users performing real tasks. Our approach aims to address this gap, providing robust offline insights that can guide subsequent online testing.
Our Approach: Combining User Surveys with Behavioral Data
To overcome the limitations of traditional offline evaluations, we’ve developed a mixed-methods approach that combines user surveys with behavioral data analysis. As seen in the paper Topical Preference Trumps Other Features in News Recommendation [5], researchers collected user responses about their topical preferences through surveys to understand their engagement with certain news articles. Inspired by this approach, we are using click histories merged with survey responses, instead of directly asking users for their preferences. Here’s how it works:
- Article Selection: We developed a method for selecting articles for a survey based on both publish date and recent traffic. This approach ensures a mix of new and still-relevant older articles.
- User Survey: We conducted a survey with approximately 1,500 SPIEGEL.de readers. Each participant rated 15 article teasers on a scale from 0 (low interest) to 1000 (high interest), with the option to indicate previously read articles.
- Behavioral Data Analysis: For each participant, we analyzed their historic click data prior to the survey. We converted articles into numeric embeddings to calculate an average user embedding, representing the reader’s global taste. We then calculated the cosine distance between the user preference vector and the embeddings of the articles rated in the survey.[6]
Throughout the process, we identified several parameters that significantly impact the model’s effectiveness. These include: the types of articles to include in the click history (with or without paywall), minimum reading time threshold per article, look-back period for user click history, choice of embedding model, what/how content gets embedded, and the use of overall visits per article for re-ranking. To assess our approach and optimize these parameters, we used two primary metrics: the Spearman Correlation Coefficient, which measures the relationship between article ratings and distances to the user preference vector; and Precision@K, which measures how well our models can place the highest-rated articles in the top K recommendations.
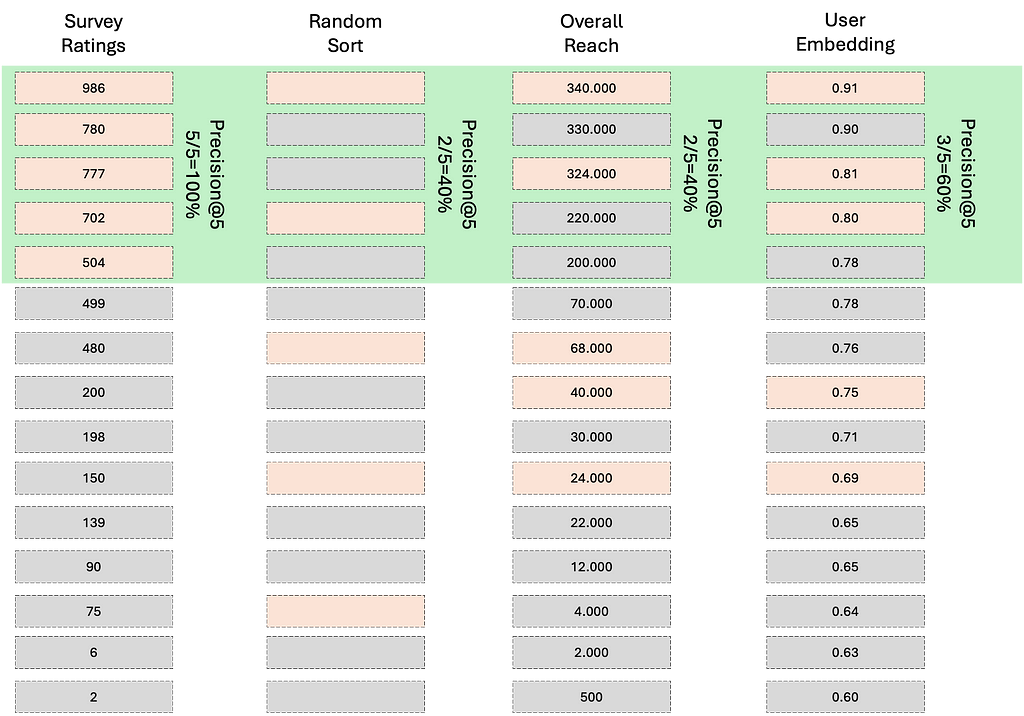
To explain our evaluation approach, we can think of four lists of the same articles for each user, each sorted differently:
- Survey Ratings: This list represents our ground truth, showing the actual ratings given by a user in our survey. Our modeling approach aims to predict this list as good as possible.
- Random Sort: This acts as our baseline, simulating a scenario where we have no information about the user and would guess their news item preferences randomly.
- Overall Reach: This list is sorted based on the overall popularity of each article across all users.
- User Embedding: This list is sorted based on the cosine distance between each rated article and the user’s average embedding. The parameters for this approach are optimized through grid search to achieve the best performance.
By comparing these lists, we can evaluate how well our user embedding approach performs compared to both the ground truth and simpler methods like random selection or popularity-based sorting. This comparison allows us to quantify the effectiveness of our personalized recommendation approach and identify the best set of parameters.
Results and Key Findings
Our mixed-methods approach to offline evaluation shows promising results, demonstrating the effectiveness of our recommendation system. The random baseline, as expected, showed the lowest performance with a precision@1 of 0.086. The reach-based method, which sorts articles based on overall popularity, showed a modest improvement with a precision@1 of 0.091. Our personalized model, however, demonstrated significant improvements over both the random baseline and the reach-based method. The model achieved a precision@1 of 0.147, a 70.7% uplift over the random baseline. The performance improvements persist across different k values.
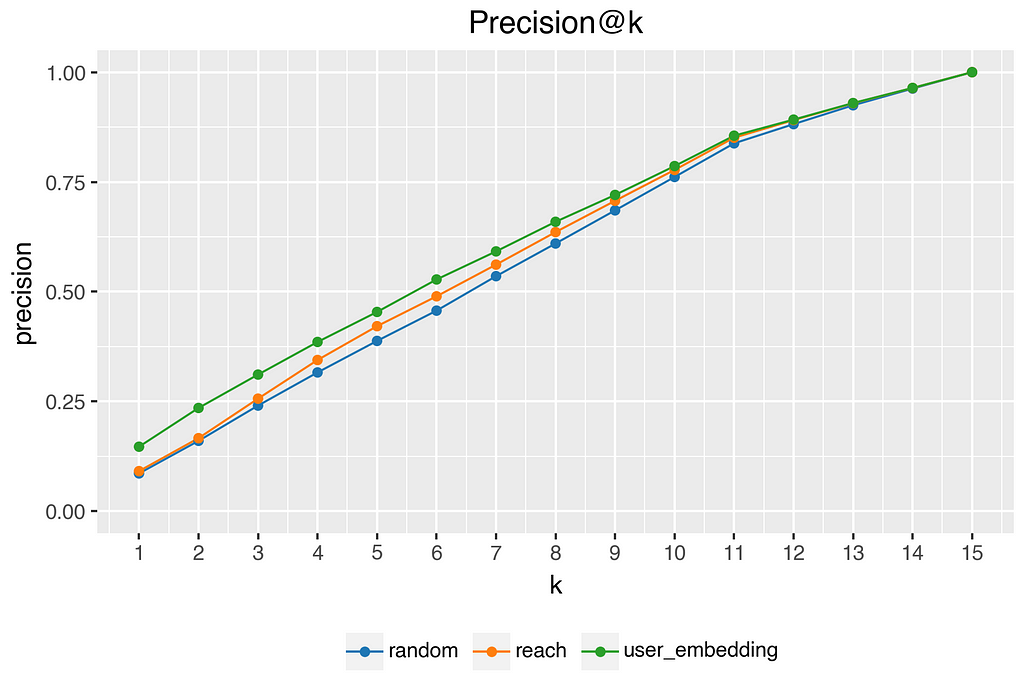
Another example: if we randomly select 5 from the 15 article teasers shown and compare these with the 5 best-rated articles of a user, we have an average precision of 5/15 = 33%. Since not every user actually rated 15 articles (some marked items as already read), the actual Precision@5 in our data is 38% (see upper chart). The average Precision@5 for the personalized model is 45%. Compared to the random model, this is an uplift of 17% (see lower chart). Note: As K increases, the probability that randomly relevant elements are included in the recommendation set also increases. Convergence to perfect precision: If K reaches or exceeds 15 (the total number of relevant elements), every method (including the random one) will include all relevant elements and achieve a precision of 1.0.
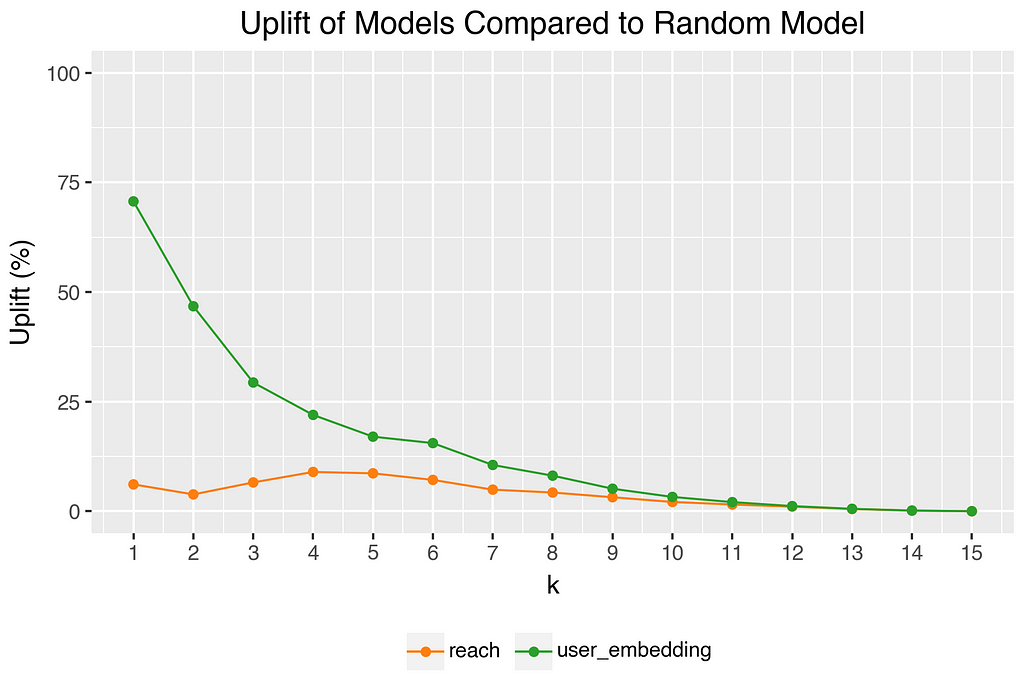
Besides Precision@K, the Spearman correlation coefficients also highlight the strength of our personalized approach. Our model achieved a correlation of 0.17 with a p-value less than 0.05. This indicates an alignment between our model’s predictions and the actual user preferences.
The described results suggest that there is a correlation between the item ratings and distances to the user preference vector. Although the precision is at a fairly low level for all models, the uplift is quite high, especially at low K. Since we will have significantly more than 15 articles per user in our candidate pool in productive operation, the uplift at low K is of high importance.
Conclusion
While our mixed-methods offline evaluation provides a strong foundation, we recognize that the true test comes when we go live. We use the insights and optimized parameters from our offline evaluation as a starting point for online A/B testing. This approach allows us to bridge the gap between offline evaluation and online performance, setting us up for a more effective transition to live testing and iteration.
As we continue to refine our approach, we remain committed to balancing technological innovation with journalistic integrity. Our goal is to develop a news recommender system where personalized recommendations are not only accurate but also ranked for diversity. This ensures that while we are optimizing for individual preferences, we also maintain a broad spectrum of perspectives and topics, upholding the standards of comprehensive and unbiased journalism that DER SPIEGEL is known for.
Thanks for reading 🙏
I hope you liked it, if so, just make it clap. Please don't hesitate to connect with me on LinkedIn for further discussion or questions.
As a data scientist at DER SPIEGEL, I have authorized access to proprietary user data and click histories, which form the basis of this study. This data is not publicly available. All presented results are aggregated and anonymized to protect user privacy while showcasing our methodological approach to news recommendation.
References
[1] Garcin, Florent & Faltings, Boi & Donatsch, Olivier & Alazzawi, Ayar & Bruttin, Christophe & Huber, Amr. (2014). Offline and online evaluation of news recommender systems at swissinfo.ch. RecSys 2014 — Proceedings of the 8th ACM Conference on Recommender Systems.
[2] Cremonesi, Paolo & Koren, Yehuda & Turrin, Roberto. (2010). Performance of recommender algorithms on top-N recommendation tasks. RecSys’10 — Proceedings of the 4th ACM Conference on Recommender Systems.
[3] Castells, Pablo & Moffat, Alistair. (2022). Offline recommender system evaluation: Challenges and new directions. AI Magazine.
[4] Janzen, Noah & Gedikli, Fatih. (2023). NewsRecs: A Mobile App Framework for Conducting and Evaluating Online Experiments for News Recommender Systems.
[5] Knudsen, Starke, Trattner. (2023). Topical Preference Trumps Other Features in News Recommendation: A Conjoint Analysis on a Representative Sample from Norway Conference. Association for Computing Machinery (ACM) RecSys ’23.
[6] Rosnes, Daniel & Starke, Alain & Trattner, Christoph. (2024). Shaping the Future of Content-based News Recommenders: Insights from Evaluating Feature-Specific Similarity Metrics.
A Mixed-Methods Approach to Offline Evaluation of News Recommender Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/4Q7nJzA
via IFTTT


