
Data Leakage in Preprocessing, Explained: A Visual Guide with Code Examples
DATA PREPROCESSING
10 sneaky ways your preprocessing pipeline leaks
In my experience teaching machine learning, students often come to me with this same problem: “My model was performing great — over 90% accuracy! But when I submitted it for testing on the hidden dataset, it is not as good now. What went wrong?” This situation almost always points to data leakage.
Data leakage happens when information from test data sneaks (or leaks) into your training data during data preparation steps. This often happens during routine data processing tasks without you noticing it. When this happens, the model learns from test data it wasn’t supposed to see, making the test results misleading.
Let’s look at common preprocessing steps and see exactly what happens when data leaks— hopefully, you can avoid these “pipeline issues” in your own projects.

Definition
Data leakage is a common problem in machine learning that occurs when data that’s not supposed to be seen by a model (like test data or future data) is accidentally used to train the model. This can lead to the model overfitting and not performing well on new, unseen data.
Now, let’s focus on data leakage during the following data preprocessing steps. Further, we’ll also see these steps with specific scikit-learn preprocessing method names and we will see the code examples at the very end of this article.
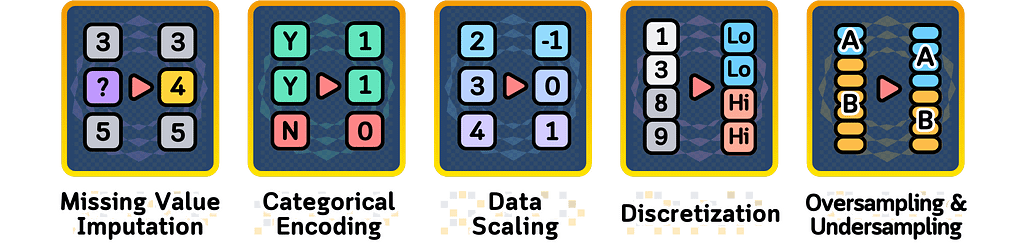
Missing Value Imputation
When working with real data, you often run into missing values. Rather than removing these incomplete data points, we can fill them in with reasonable estimates. This helps us keep more data for analysis.
Simple ways to fill missing values include:
- Using SimpleImputer(strategy='mean') or SimpleImputer(strategy='median') to fill with the average or middle value from that column
- Using KNNImputer() to look at similar data points and use their values
- Using SimpleImputer(strategy='ffill') or SimpleImputer(strategy='bfill') to fill with the value that comes before or after in the data
- Using SimpleImputer(strategy='constant', fill_value=value) to replace all missing spots with the same number or text
This process is called imputation, and while it’s useful, we need to be careful about how we calculate these replacement values to avoid data leakage.
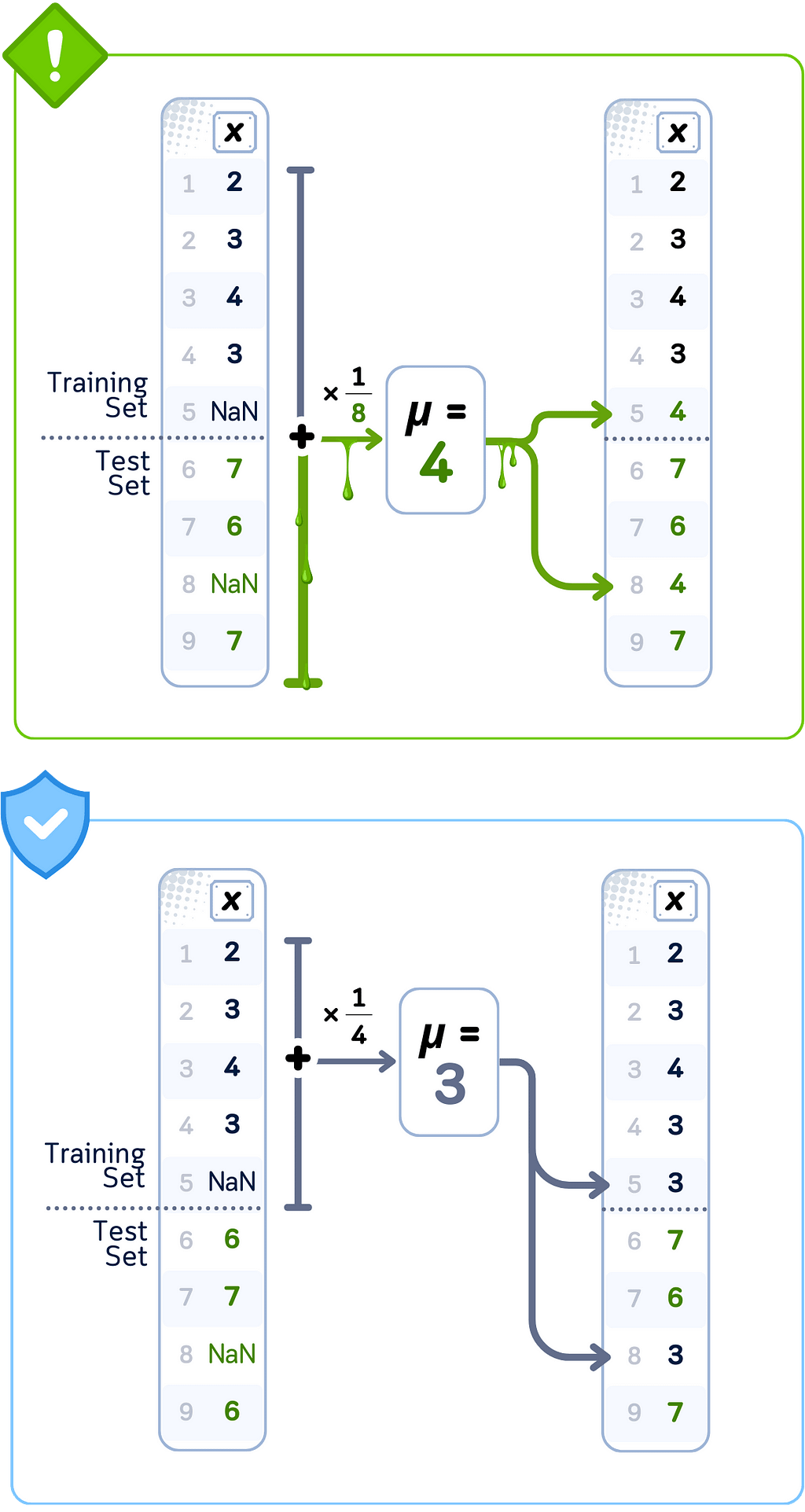
Data Leakage Case: Simple Imputation (Mean)
🚨 THE ISSUE
Computing mean values using complete dataset
❌ What We’re Doing Wrong
Calculating fill values using both training and test set statistics
💥 The Consequence
Training data contains averaged values influenced by test data
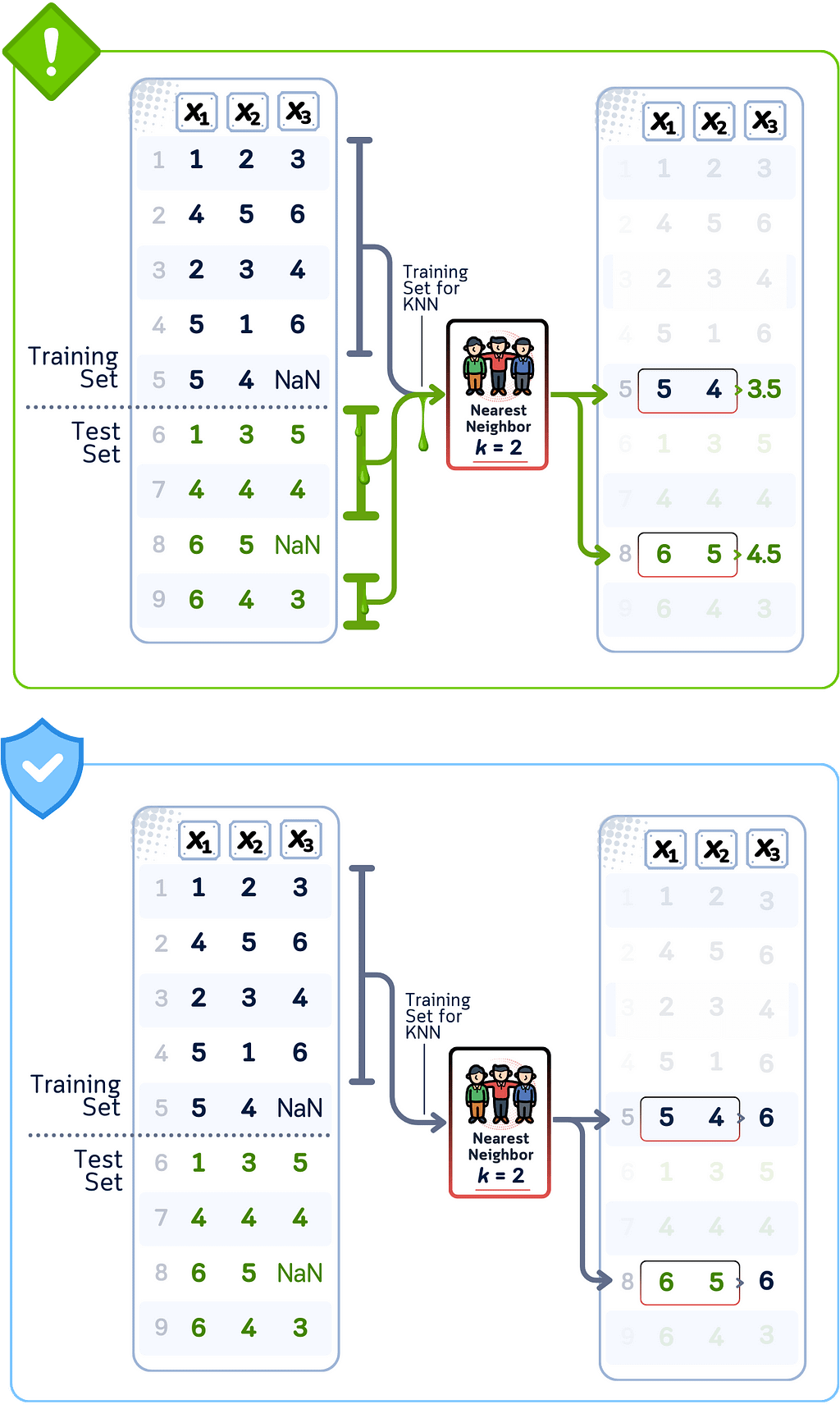
Data Leakage Case: KNN Imputation
🚨 THE ISSUE
Finding neighbors across complete dataset
❌ What We’re Doing Wrong
Using test set samples as potential neighbors for imputation
💥 The Consequence
Missing values filled using direct test set information
Categorical Encoding
Some data comes as categories instead of numbers — like colors, names, or types. Since models can only work with numbers, we need to convert these categories into numerical values.
Common ways to convert categories include:
- Using OneHotEncoder() to create separate columns of 1s and 0s for each category (also known as dummy variables)
- Using OrdinalEncoder() or LabelEncoder() to assign each category a number (like 1, 2, 3)
- Using OrdinalEncoder(categories=[ordered_list]) with custom category orders to reflect natural hierarchy (like small=1, medium=2, large=3)
- Using TargetEncoder() to convert categories to numbers based on their relationship with the target variable we're trying to predict
The way we convert these categories can affect how well our model learns, and we need to be careful about using information from test data during this process.
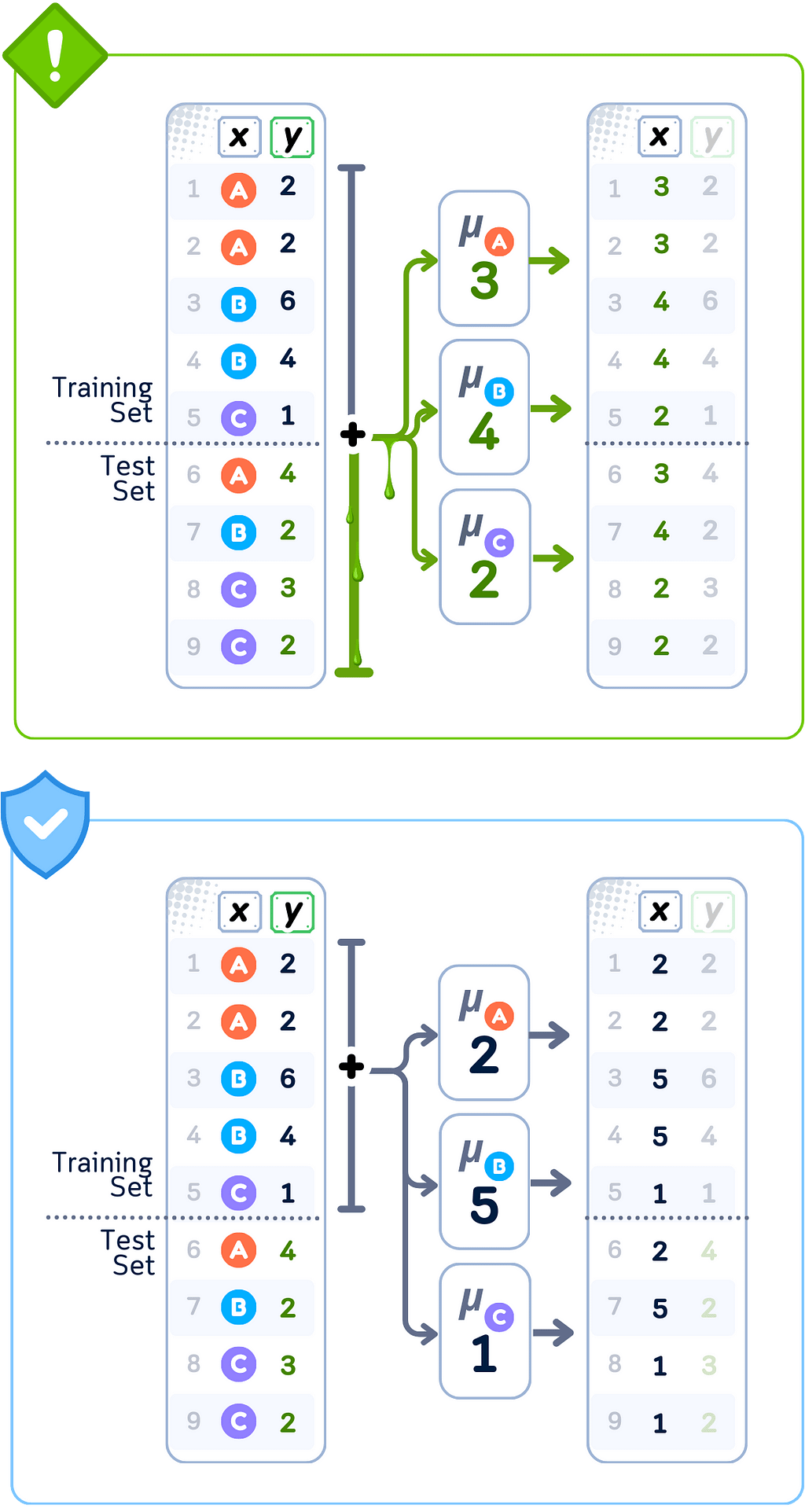
Data Leakage Case: Target Encoding
🚨 THE ISSUE
Computing category means using complete dataset
❌ What We’re Doing Wrong
Calculating category replacements using all target values
💥 The Consequence
Training features contain future target information
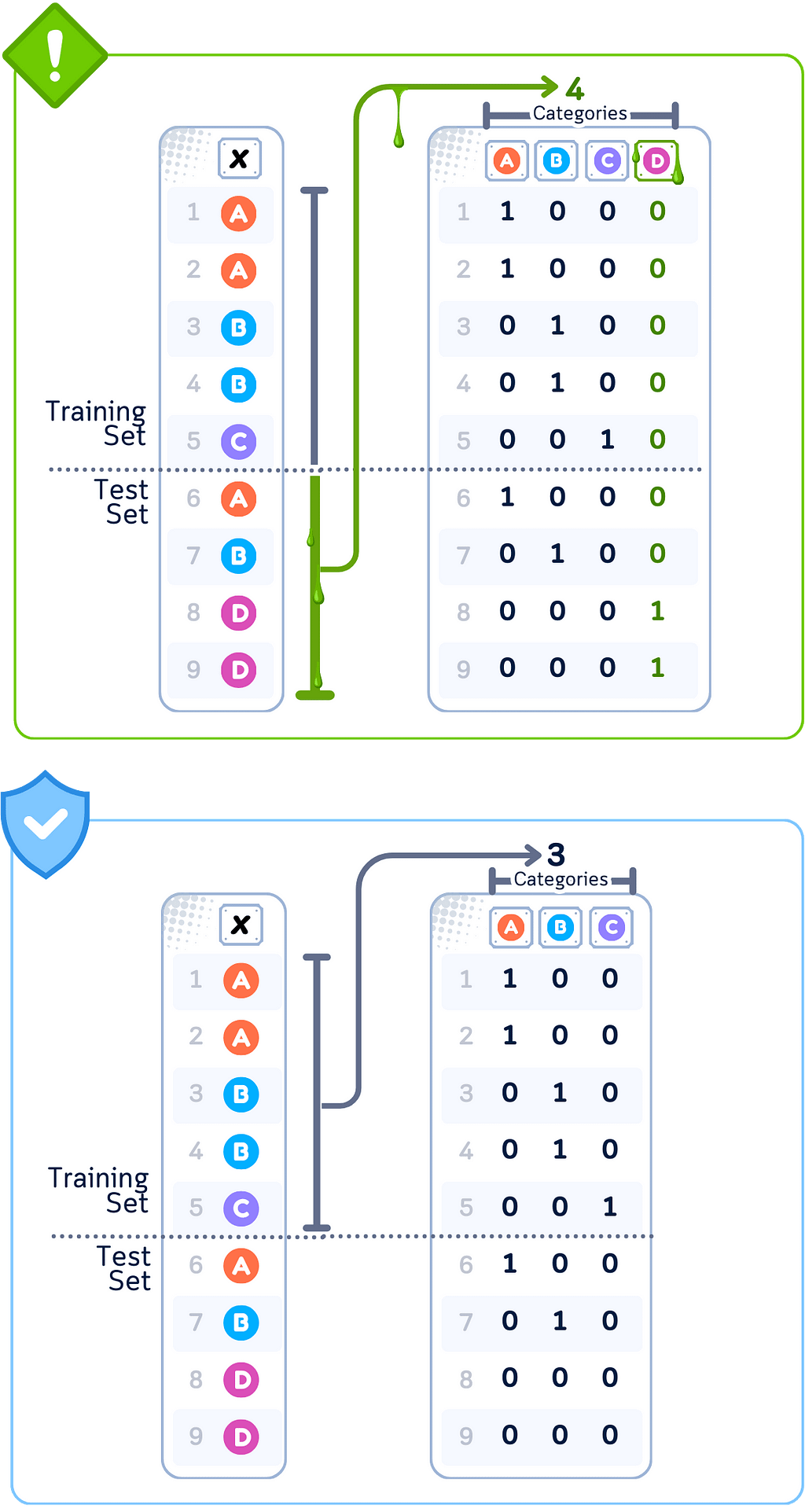
Data Leakage Case: One-Hot Encoding
🚨 THE ISSUE
Determining categories from complete dataset
❌ What We’re Doing Wrong
Creating binary columns based on all unique values
💥 The Consequence
Feature selection influenced by test set patterns
Data Scaling
Different features in your data often have very different ranges — some might be in thousands while others are tiny decimals. We adjust these ranges so all features have similar scales, which helps models work better.
Common ways to adjust scales include:
- Using StandardScaler() to make values center around 0 with most falling between -1 and 1 (mean=0, variance=1)
- Using MinMaxScaler() to squeeze all values between 0 and 1, or MinMaxScaler(feature_range=(min, max)) for a custom range
- Using FunctionTransformer(np.log1p) or PowerTransformer(method='box-cox') to handle very large numbers and make distributions more normal
- Using RobustScaler() to adjust scales using statistics that aren't affected by outliers (using quartiles instead of mean/variance)
While scaling helps models compare different features fairly, we need to calculate these adjustments using only training data to avoid leakage.
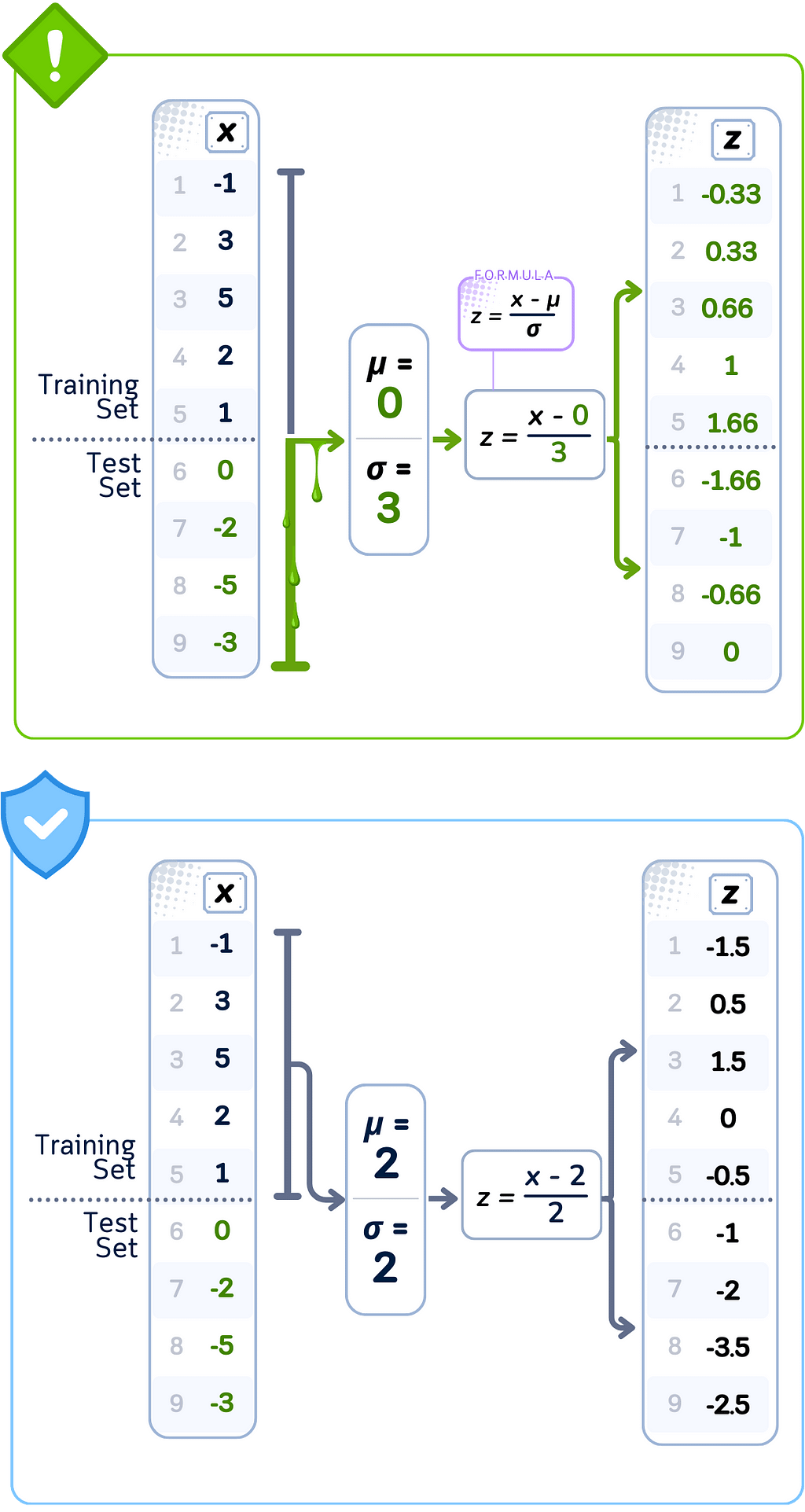
Data Leakage Case: Standard Scaling
🚨 THE ISSUE
Computing statistics using complete dataset
❌ What We’re Doing Wrong
Calculating mean and standard deviation using all values
💥 The Consequence
Training features scaled using test set distribution
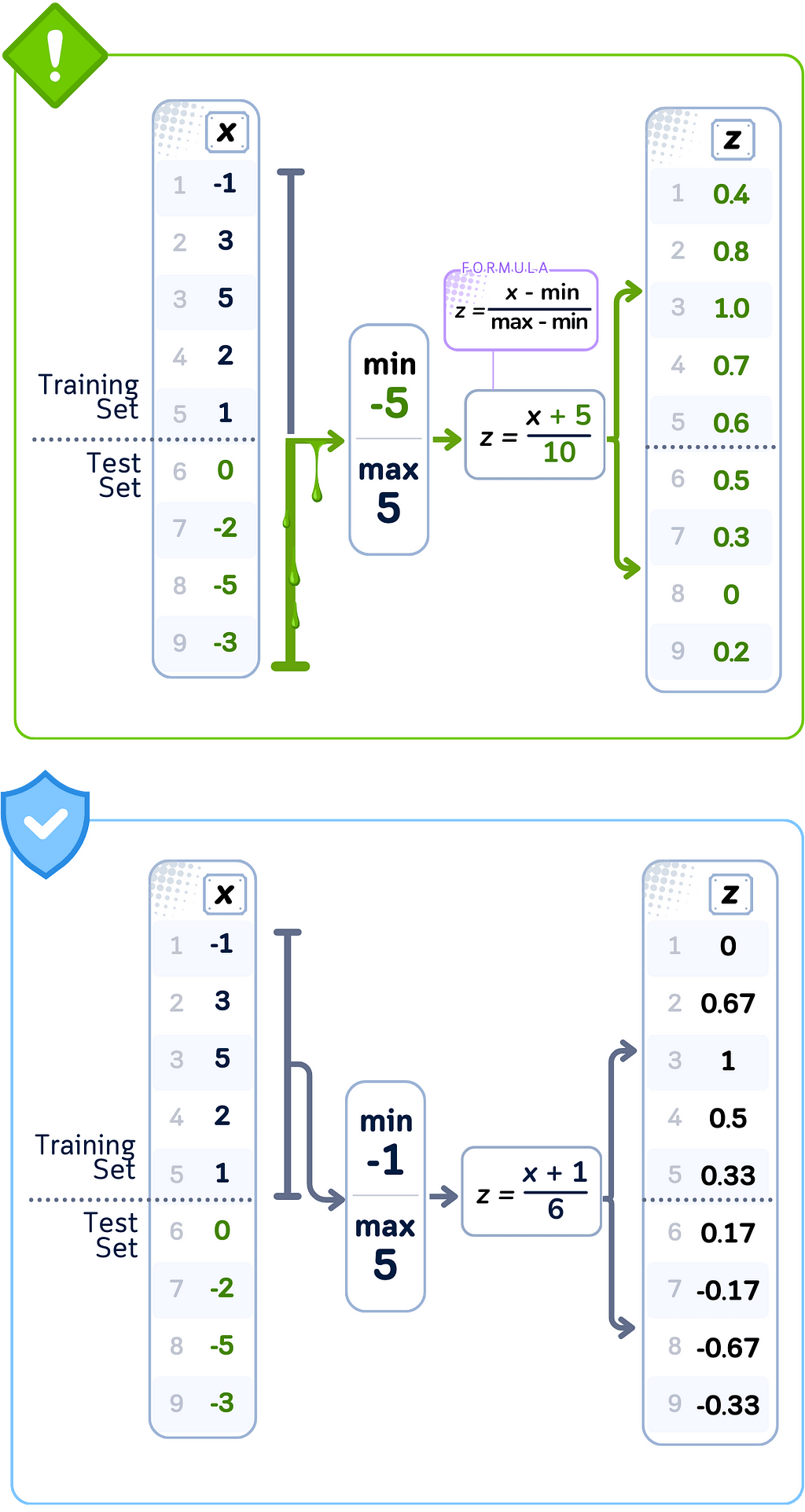
Data Leakage Case: Min-Max Scaling
🚨 THE ISSUE
Finding bounds using complete dataset
❌ What We’re Doing Wrong
Determining min/max values from all data points
💥 The Consequence
Training features normalized using test set ranges
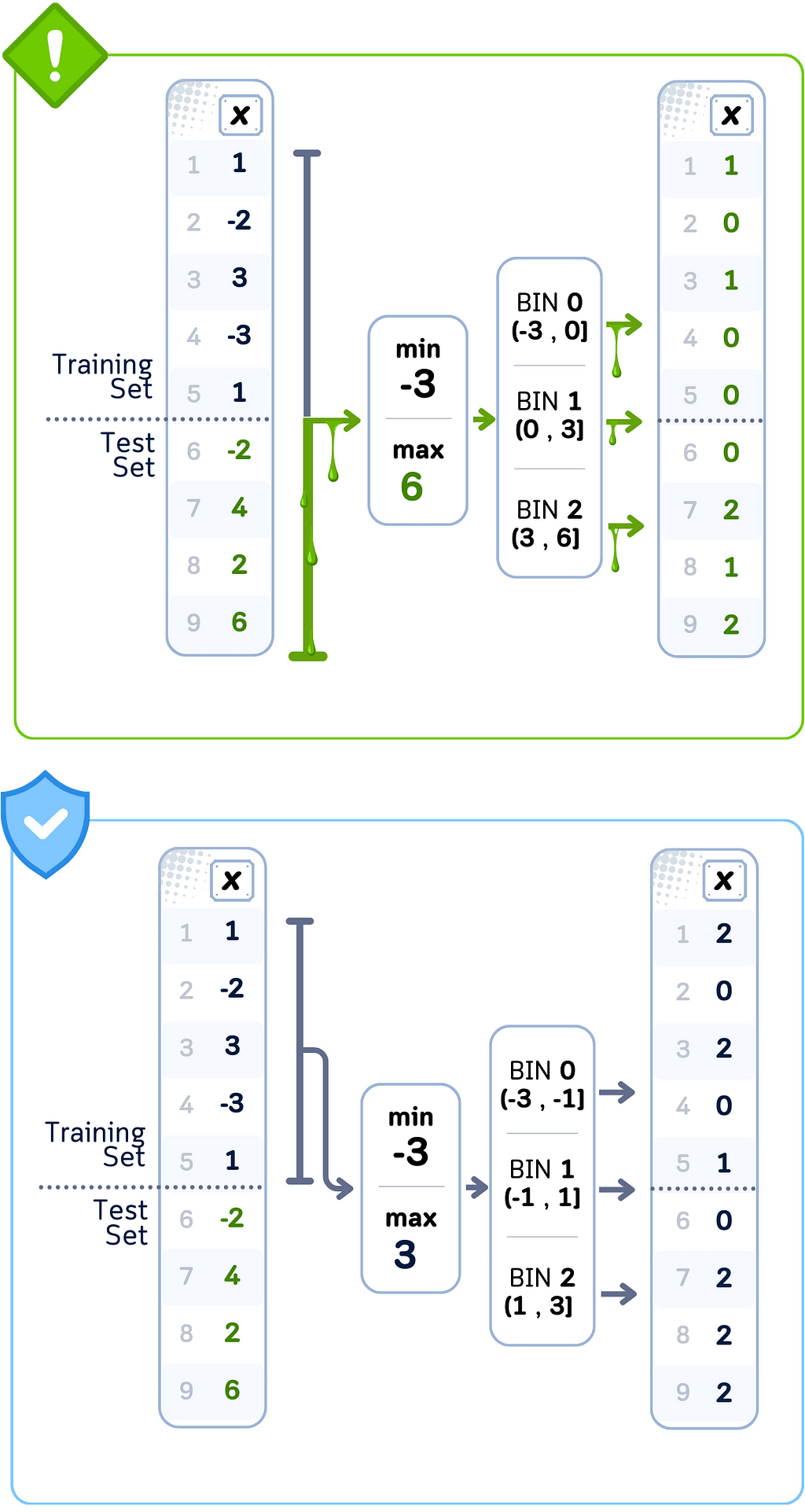
Discretization
Sometimes it’s better to group numbers into categories rather than use exact values. This helps machine learning models to process and analyze the data more easily.
Common ways to create these groups include:
- Using KBinsDiscretizer(strategy='uniform') to make each group cover the same size range of values
- Using KBinsDiscretizer(strategy='quantile') to make each group contain the same number of data points
- Using KBinsDiscretizer(strategy='kmeans') to find natural groupings in the data using clustering
- Using QuantileTransformer(n_quantiles=n, output_distribution='uniform') to create groups based on percentiles in your data
While grouping values can help models find patterns better, the way we decide group boundaries needs to use only training data to avoid leakage.
Data Leakage Case: Equal Frequency Binning
🚨 THE ISSUE
Setting thresholds using complete dataset
❌ What We’re Doing Wrong
Determining bin boundaries using all data points
💥 The Consequence
Training data binned using test set distributions
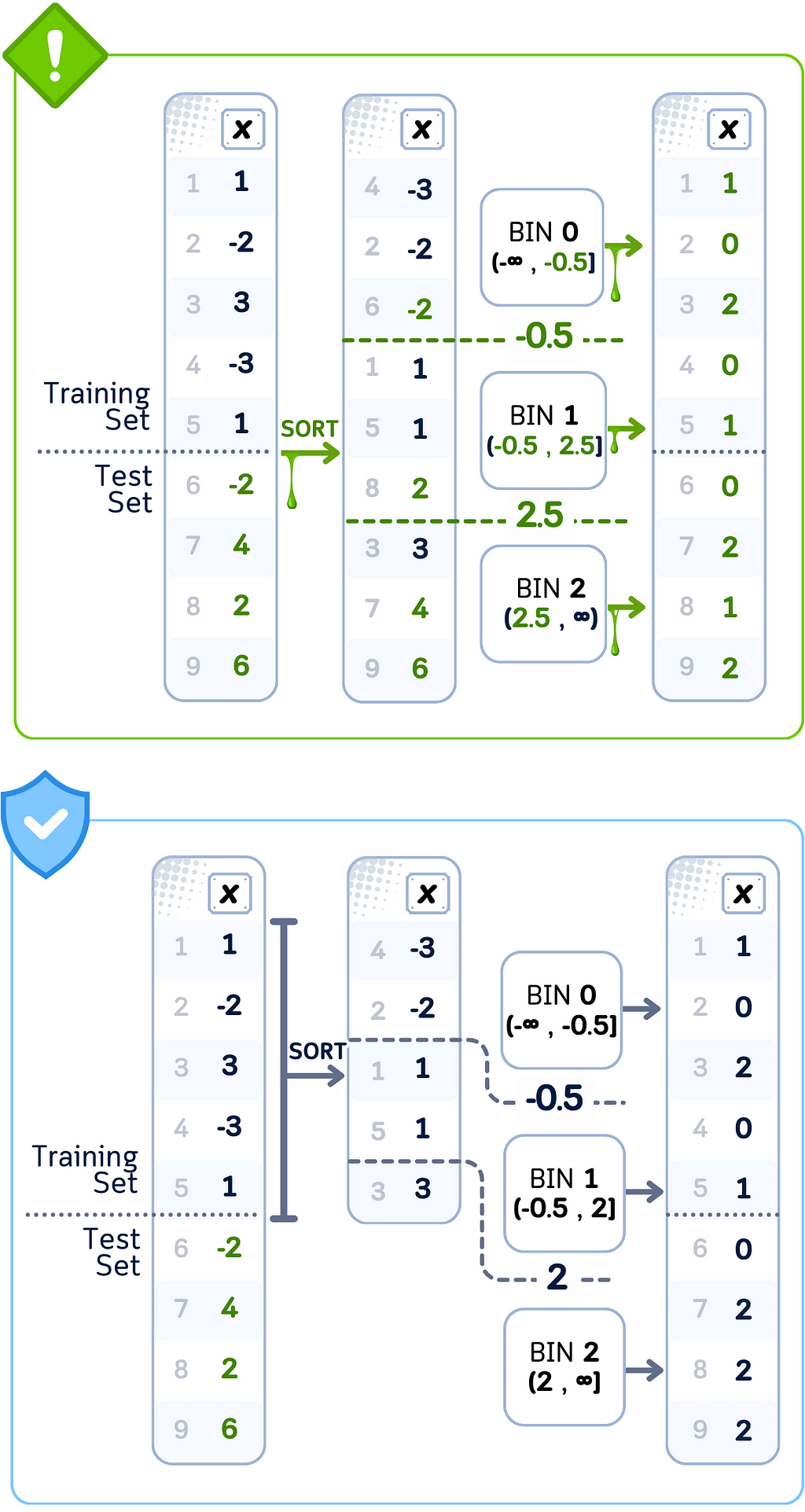
Data Leakage Case: Equal Width Binning
🚨 THE ISSUE
Calculating ranges using complete dataset
❌ What We’re Doing Wrong
Setting bin widths based on full data spread
💥 The Consequence
Training data binned using test set boundaries
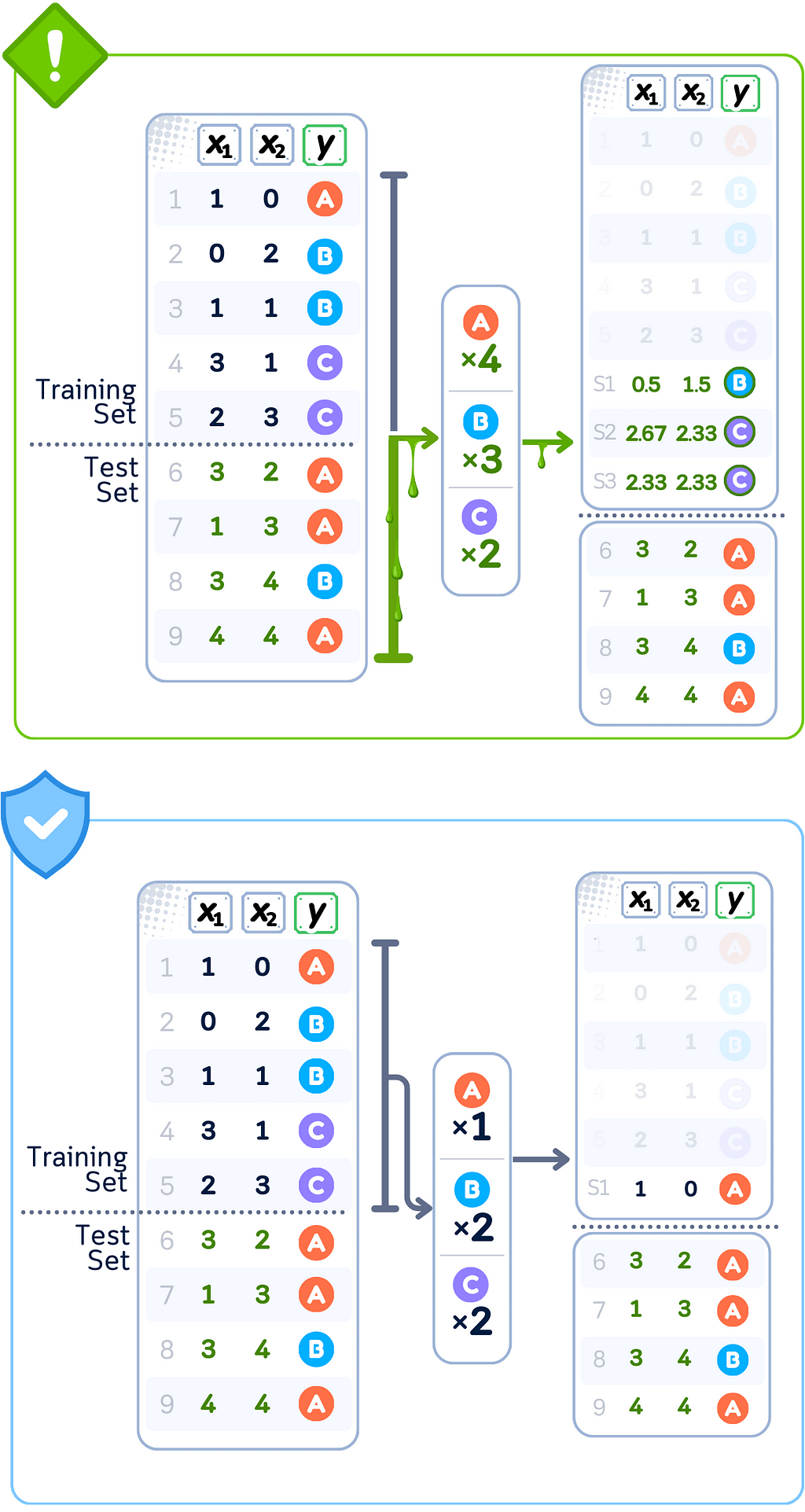
Resampling
When some categories in your data have many more examples than others, we can balance them using resampling techniques from imblearn by either creating new samples or removing existing ones. This helps models learn all categories fairly.
Common ways to add samples (Oversampling):
- Using RandomOverSampler() to make copies of existing examples from smaller categories
- Using SMOTE() to create new, synthetic examples for smaller categories using interpolation
- Using ADASYN() to create more examples in areas where the model struggles most, focusing on decision boundaries
Common ways to remove samples (Undersampling):
- Using RandomUnderSampler() to randomly remove examples from larger categories
- Using NearMiss(version=1) or NearMiss(version=2) to remove examples from larger categories based on their distance to smaller categories
- Using TomekLinks() or EditedNearestNeighbours() to carefully select which examples to remove based on their similarity to other categories
While balancing your data helps models learn better, the process of creating or removing samples should only use information from training data to avoid leakage.
Data Leakage Case: Oversampling (SMOTE)
🚨 THE ISSUE
Generating samples using complete dataset
❌ What We’re Doing Wrong
Creating synthetic points using test set neighbors
💥 The Consequence
Training augmented with test-influenced samples
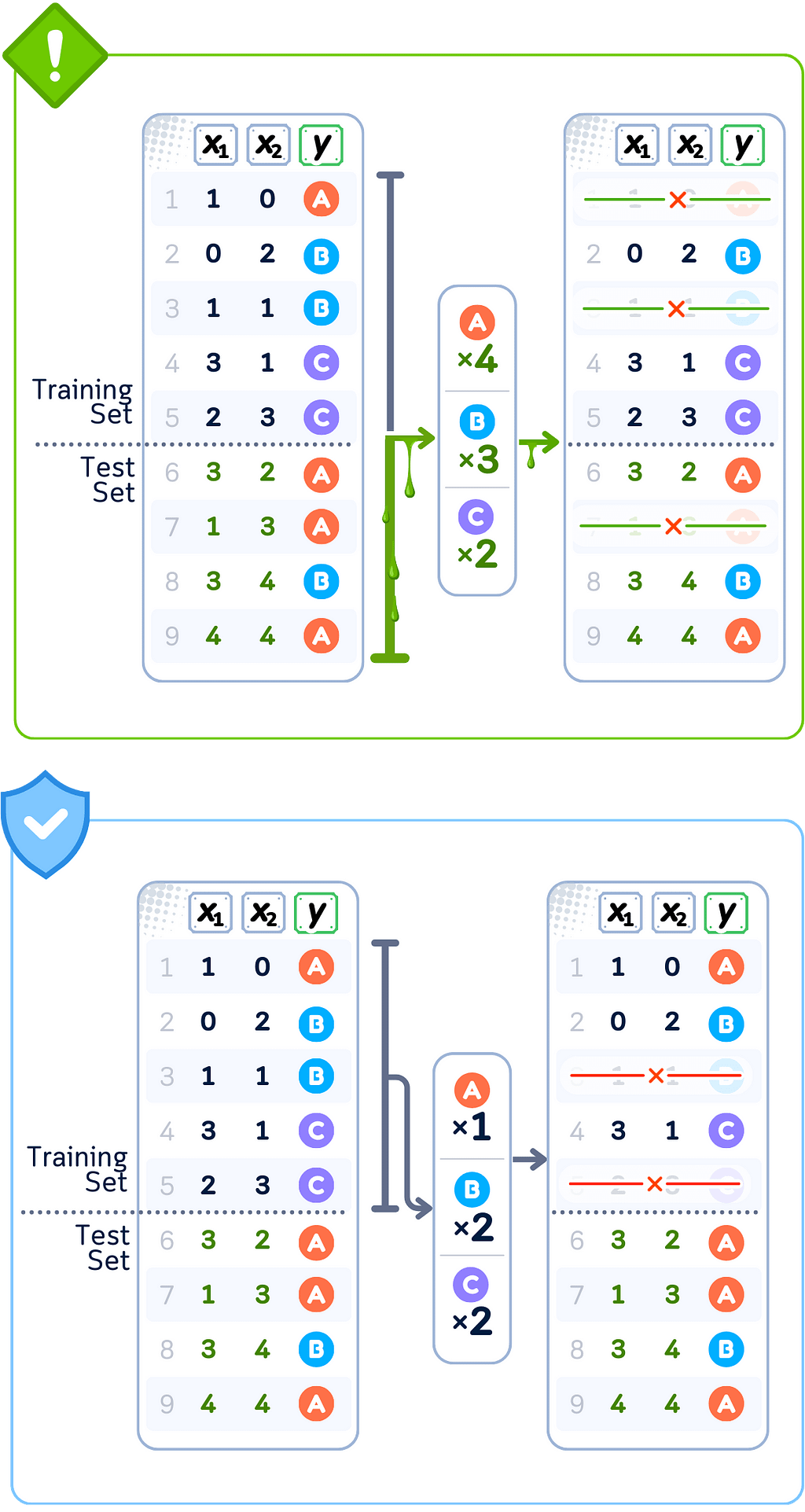
Data Leakage Case: Undersampling (Tomek Links)
🚨 THE ISSUE
Removing samples using complete dataset
❌ What We’re Doing Wrong
Identifying pairs using test set relationships
💥 The Consequence
Training reduced based on test set patterns
Final Remarks
When preprocessing data, you need to keep training and test data completely separate. Any time you use information from all your data to transform values — whether you’re filling missing values, converting categories to numbers, scaling features, creating bins, or balancing classes — you risk mixing test data information into your training data. This makes your model’s test results unreliable because the model already learned from patterns it wasn’t supposed to see.
The solution is simple: always transform your training data first, save those calculations, and then apply them to your test data.
🌟 Data Preprocessing + Classification (with Leakage) Code Summary
Let us see how leakage could happen in predicting a simple golf play dataset. This is the bad example and should not be followed. Just for demonstration and education purposes.
import pandas as pd
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder, KBinsDiscretizer
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
# Create dataset
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
X, y = df.drop('Play', axis=1), df['Play']
# Preprocess AND apply SMOTE to ALL data first (causing leakage)
preprocessor = ColumnTransformer(transformers=[
('temp_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Temperature']),
('humid_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Humidity']),
('outlook_transform', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1),
['Outlook']),
('wind_transform', Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value=False)),
('scaler', StandardScaler())
]), ['Wind'])
])
# Transform all data and apply SMOTE before splitting (leakage!)
X_transformed = preprocessor.fit_transform(X)
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_transformed, y)
# Split the already transformed and resampled data
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.5, shuffle=False)
# Train a classifier
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
print(f"Testing Accuracy (with leakage): {accuracy_score(y_test, clf.predict(X_test)):.2%}")
The code above is using ColumnTransformer, which is a utility in scikit-learn that allows us to apply different preprocessing steps to different columns in a dataset.
Here’s a breakdown of the preprocessing strategy for each column in the dataset:
Temperature:
- Mean imputation to handle any missing values
- Standard scaling to normalize the values (mean=0, std=1)
- Equal-width discretization into 4 bins, meaning continuous values are categorized into 4 equal-width intervals
Humidity:
- Same strategy as Temperature: Mean imputation → Standard scaling → Equal-width discretization (4 bins)
Outlook(categorical):
- Ordinal encoding: converts categorical values into numerical ones
- Unknown values are handled by setting them to -1
Wind (binary):
- Constant imputation with False for missing values
- Standard scaling to normalize the 0/1 values
Play (target):
- Label encoding to convert Yes/No to 1/0
- SMOTE applied after preprocessing to balance classes by creating synthetic examples of the minority class
- A simple decision tree is used to predict the target
The entire pipeline demonstrates data leakage because all transformations see the entire dataset during fitting, which would be inappropriate in a real machine learning scenario where we need to keep test data completely separate from the training process.
This approach will also likely show artificially higher test accuracy because the test data characteristics were used in the preprocessing steps!
🌟 Data Preprocessing + Classification (without leakage) Code Summary
Here’s the version without data leakage:
import pandas as pd
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder, KBinsDiscretizer
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
# Create dataset
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
X, y = df.drop('Play', axis=1), df['Play']
# Split first (before any processing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
# Create pipeline with preprocessing, SMOTE, and classifier
pipeline = Pipeline([
('preprocessor', ColumnTransformer(transformers=[
('temp_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Temperature']),
('humid_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Humidity']),
('outlook_transform', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1),
['Outlook']),
('wind_transform', Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value=False)),
('scaler', StandardScaler())
]), ['Wind'])
])),
('smote', SMOTE(random_state=42)),
('classifier', DecisionTreeClassifier(random_state=42))
])
# Fit pipeline on training data only
pipeline.fit(X_train, y_train)
print(f"Training Accuracy: {accuracy_score(y_train, pipeline.predict(X_train)):.2%}")
print(f"Testing Accuracy: {accuracy_score(y_test, pipeline.predict(X_test)):.2%}")
Key differences from the leakage version
- Split data first, before any processing
- All transformations (preprocessing, SMOTE) are inside the pipeline
- Pipeline ensures:
- Preprocessing parameters learned only from training data
- SMOTE applies only to training data
- Test data remains completely unseen until prediction
This approach gives more realistic performance estimates as it maintains proper separation between training and test data.
Technical Environment
This article uses Python 3.7 , scikit-learn 1.5, and imblearn 0.12. While the concepts discussed are generally applicable, specific code implementations may vary slightly with different versions
About the Illustrations
Unless otherwise noted, all images are created by the author, incorporating licensed design elements from Canva Pro.
Data Leakage in Preprocessing, Explained: A Visual Guide with Code Examples was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/aYZ7lTH
via IFTTT





