
How to Use HyDE for Better LLM RAG Retrieval
Building an advanced local LLM RAG pipeline with hypothetical document embeddings

Large Language Models (LLMs) can be improved by giving them access to external knowledge through documents.
The basic Retrieval Augmented Generation (RAG) pipeline consists of a user query, an embedding model that converts text into embeddings (high-dimensional numerical vectors), a retrieval step that searches for documents similar to the user query in the embedding space, and a generator LLM that uses the retrieved documents to generate an answer [1].
In practice, the RAG retrieval part is crucial. If the retriever does not find the correct document in the document corpus, the LLM has no chance to generate a solid answer.
A problem in the retrieval step can be that the user query is a very short question — with imperfect grammar, spelling, and punctuation — and the corresponding document is a long passage of well-written text that contains the information we want.

HyDE is a proposed technique to improve the RAG retrieval step by converting the user question into a hypothetical document.
In this article, you will learn about the HyDE technique and how and when to use it to improve your own RAG pipeline.
Table Of Contents
· HyDE Retrieval
∘ Contriever
∘ When to Use HyDE
· Implementing HyDE
· Is Implementing HyDE Worth It?
· Conclusion
· References
HyDE Retrieval
Hypothetical Document Embeddings (HyDE) were first proposed in the paper “Precise Zero-Shot Dense Retrieval without Relevance Label” in 2022 [2].
The goal of HyDE is to transform the user query into a “document” so that the retriever has an easier task.
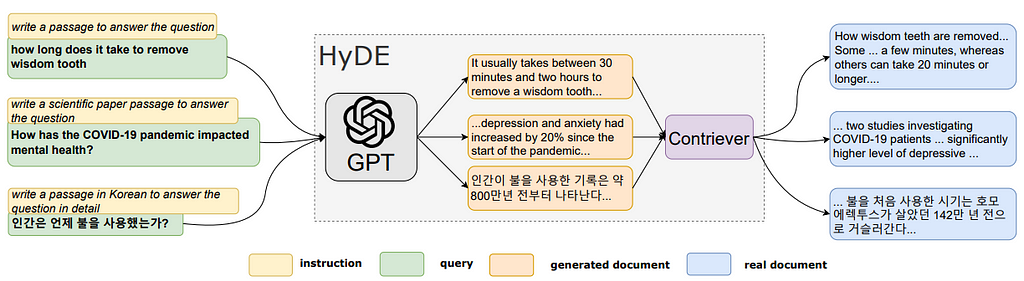
HyDE uses an off-the-shelf LLM (e.g. ChatGPT, Llama, etc.) with a simple instruction — like ”write a document that answers the question” — to convert the user query into a generated fake document. This transformation of a short user question into a longer hypothetical text passage is the central idea of HyDE.
This generated fake document will most likely contain hallucinated numbers and false statements.
However, this does not matter because the fake document is encoded into an embedding vector by the encoder model and used for semantic similarity search.
According to the HyDE paper, the encoding model acts as a lossy compressor that filters out the hallucinated details of the generated fake document. This leaves us with a vector embedding that should be very similar to the embeddings of our corpus of real documents.
Finally, the contriever uses the generated fake documents to search for the closest real documents in the document embedding space. This is usually done via dot product or cosine similarity.
In summary, instead of performing a similarity search in the query — document embedding space, HyDE performs a similarity search in the (hypothetical) document — (real) document embedding space.
Contriever
What is a contriever and why does HyDE use one?
The HyDE paper is strongly motivated by the fact that there is not always a large enough dataset available to train a retriever for query-document similarity search.
A contriever is a retriever (embedding model) trained with contrastive learning. Contrastive learning is a form of self-supervised learning where no labels are required for the training dataset [3].
This is particularly useful when large amounts of labeled data are not available, such as when trying to train a retriever in a language other than English.
An embedding model trained with contrastive learning tries to distinguish between semantically similar text (high score) and semantically dissimilar text (low score).
During the contrastive training process, text pairs are selected either from the same document (positive pair) or from different documents (negative pair). The retriever is then trained to distinguish between positive and negative document pairs.
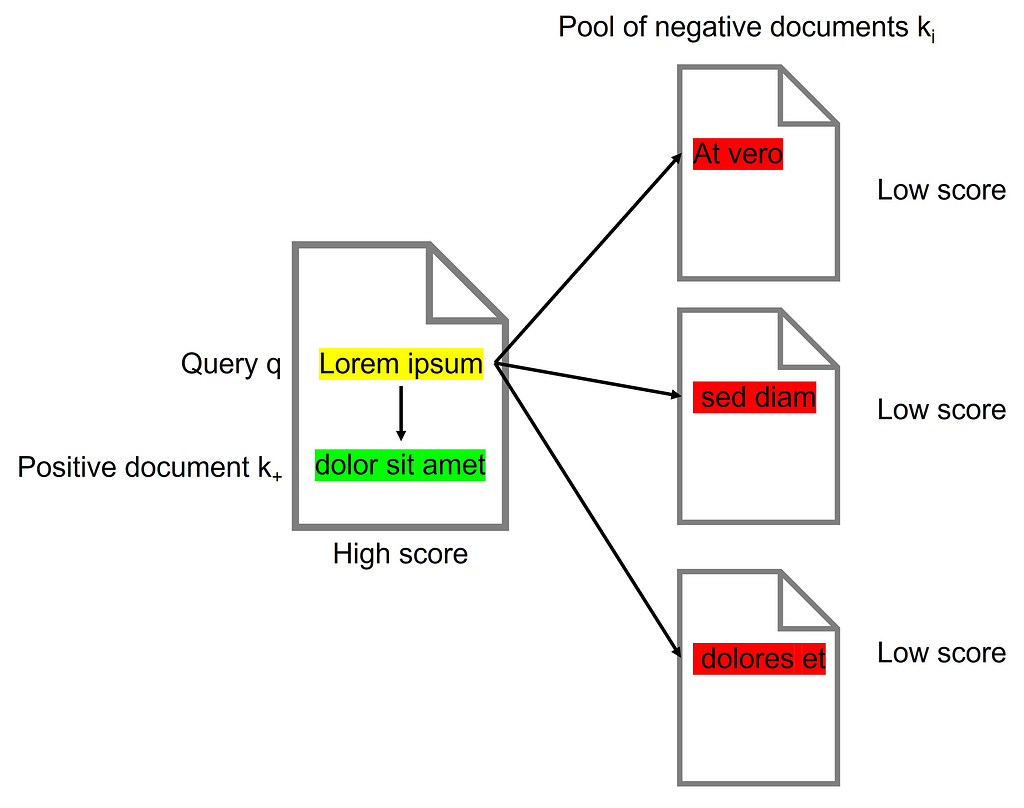
The trained contriever can then be used as is or it can be used as a pre-trained model for further fine-tuning with labeled data.
The contriever is trained in a self-supervised manner by searching for similarities between documents, i.e. no labeled data is required. And the HyDE instruction transforms user questions into this document space by creating fake documents.
When to Use HyDE
Your choice of the embedding model is critical to understanding when to use HyDE to improve RAG retrieval.
A popular general-purpose and free-to-use encoder model is the all-MiniLM-L12-v2 model from the sentence-transformers package, hosted on Hugging Face.
On the model’s Hugging Face model card, we can read the following about the model’s background:
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised contrastive learning objective. We used the pretrained microsoft/MiniLM-L12-H384-uncased model and fine-tuned in on a 1B sentence pairs dataset.
This means that this encoder model is exactly what HyDE was made for: it was trained without labels using self-supervised contrastive learning on document-document data pairs.
So, HyDE should be able to improve retrieval performance for this embedding model!
On the other hand, you do not need to use HyDE if your encoder model has been specifically trained in a supervised manner for semantic search — especially asymmetric semantic search.
Asymmetric semantic search means that you have a short question and you are looking for a longer paragraph to answer that question — exactly what RAG is typically used for.
A popular training dataset for this type of encoder model is the MS MARCO dataset, which was originally a question-answering dataset containing real Bing questions and human-generated answers.
Encoder models from the Sentence Transformers library, such as the “msmarco-*” models and the “multi-qa-*” models, are already trained on labeled question-document data and therefore should (in theory) not benefit from using HyDE.
For most commercial embedding models, such as the text-embeddingmodels from OpenAI, we don’t know how they were trained, so HyDE may or may not improve retrieval performance.
Implementing HyDE
Let’s implement a basic version of HyDE in Python.
We start with a simple LLM class that initializes a local Qwen2.5–0.5B-Instruct model. The model is small enough that it can also run on the CPU if no GPU is available on your local machine.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
class LLM:
def __init__(
self,
model_name="Qwen/Qwen2.5-0.5B-Instruct",
):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
).to(self.device)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def generate(self, prompt, temperature=0.7, max_new_tokens=256):
messages = [{"role": "user", "content": prompt}]
text = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = self.tokenizer([text], return_tensors="pt").to(self.device)
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=temperature,
)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
return self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Next, we need an encoder model to compute sentence embeddings. To get a local all-MiniLM-L12-v2 contriever model, we only need a few lines of code using the sentence_transformers library:
from sentence_transformers import SentenceTransformer
encoder_model = SentenceTransformer("all-MiniLM-L12-v2", device="cpu")
With these two ingredients, we can already compute hypothetical document encodings:
qwen = LLM()
question = "was ronald reagon a democrat?"
hypothetical_document = qwen.generate(
f"Write a paragraph that answers the question. Question: {question}"
)
>> print(hypothetical_document)
Printing our hypothetical document gives us the following paragraph:
Ronald Reagan, born on November 6, 1924, in Grand Prairie, Texas, was a renowned American politician who served as the 36th President of the United States from 1981 to 1989. As the first Republican candidate for president and the first sitting president since Richard Nixon’s resignation, Reagan faced significant challenges during his tenure.
Reagan’s political career began with a successful run for office against the Democratic nominee Hubert Humphrey in the 1968 presidential election. However, he quickly became disillusioned with the Democratic Party’s stance on civil rights and social justice
At first glance, this looks like maybe something from Wikipedia. However, there are many hallucinated facts in it. But since this is not a real document, it is okay to have errors.
Next, we can get a real passage of text from Wikipedia and compute the embeddings of the question, the Wikipedia document, and the hypothetical document.
wikipedia = """Ronald Wilson Reagan[a] (February 6, 1911 – June 5, 2004) was an American politician and actor who served as the 40th president of the United States from 1981 to 1989.
A member of the Republican Party, he became an important figure in the American conservative movement, and his presidency is known as the Reagan era. """
hypothetical_document_embedding = encoder_model.encode(hypothetical_document)
question_embedding = encoder_model.encode(question)
wikipedia_embedding = encoder_model.encode(wikipedia)
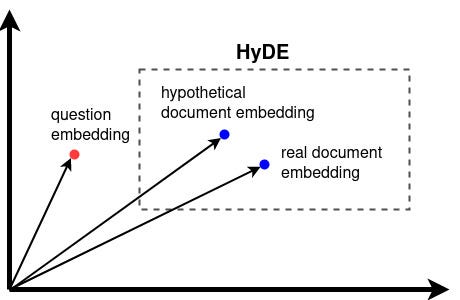
Now, we can check if the hypothetical document embedding is actually closer to the real document embedding than the question embedding.
We can use the similarity function from the encoder model, which uses the cosine similarity measure under the hood.
The cosine similarity measure goes from -1 to +1, where -1 means that the embedding vectors point in opposite directions, 0 means that they are exactly perpendicular, and +1 means that they point in the same direction.
>> print(encoder_model.similarity(hypothetical_document_embedding, wikipedia_embedding))
>> tensor([[0.8039]])
>> print(encoder_model.similarity(question_embedding, wikipedia_embedding))
>> tensor([[0.4566]])
As we can see, the hypothetical document embedding is much closer to the real document embedding in our embedding space. Thus, HyDE has successfully reduced the domain gap between question and document.
However, it also took some additional computation to generate the hypothetical document using our LLM. This is the disadvantage of using HyDE.
Is Implementing HyDE Worth It?
A recent study called “Searching for Best Practices in Retrieval-Augmented Generation” [4] looked at different retrieval methods for RAG. The study found that HyDE improved the retrieval performance compared to the baseline embedding model.
Furthermore, the combination of hybrid search with HyDE produced the best overall results.
Interestingly, they also found that concatenating the original query with the hypothetical document produced even better results.
On the other hand, HyDE increases latency and cost by requiring additional LLM calls to transform each query into a fake document.
Considering the best performance and tolerated latency, we recommend Hybrid Search with HyDE as the default retrieval method. Taking efficiency into consideration, Hybrid Search combines sparse retrieval (BM25) and dense retrieval (Original embedding) and achieves notable performance with relatively low latency [4]
Conclusion
HyDE is an advanced technique for improving the retrieval part of a RAG pipeline.
By creating hypothetical fake documents from a query, we can perform similarity search in the document-document embedding space, instead of the question-document embedding space.
HyDE has been proposed for a use case where the embedding model is not already fine-tuned for semantic search with labeled question-document data.
Since HyDE requires only a few additional LLM calls, it is very easy to implement.
So give it a try and see if HyDE can improve your RAG retrieval.
HyDE is a building block in your toolkit that can be combined with other advanced RAG techniques, such as hybrid search and using a reranker after the retrieval part.
References
[2] P. Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2021), arXiv:2005.11401
[2] L. Gao, X. Ma, J. Lin, J. Callan, Precise Zero-Shot Dense Retrieval without Relevance Labels (2022), arXiv:2212.10496
[3] G. Izacard et al., Unsupervised Dense Information Retrieval with Contrastive Learning (2022), Transactions on Machine Learning Research (08/2022)
[4] X. Wang et al., Searching for Best Practices in Retrieval-Augmented Generation (2024), arXiv:2407.01219
Read more articles in my series on how to improve RAG retrieval performance
- How to Use Re-Ranking for Better LLM RAG Retrieval
- How to Use Hybrid Search for Better LLM RAG Retrieval
How to Use HyDE for Better LLM RAG Retrieval was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/Tufv6g0
via IFTTT


