
Load testing Self-Hosted LLMs
Do you need more GPUs or a modern GPU? How do you make infrastructure decisions?

How does it feel when a group of users suddenly start using an app that only you and your dev team have used before?
That’s the million-dollar question of moving from prototype to production.
As far as LLMs are concerned, you can do a few dozen tweaks to run your app within the budget and acceptable qualities. For instance, you can choose a quantized model for lower memory usage. Or you can fine-tune a tiny model and beat the performance of giant LLMs.
I Fine-Tuned the Tiny Llama 3.2 1B to Replace GPT-4o
You can even tweak your infrastructure to achieve better outcomes. For example, you may want to double the number of GPUs you use or choose the latest-generation GPU.
But how could you say Option A performs better than Option B and C?
This is an important question to ask ourselves at the earliest stages of going into production. All these options have their costs — infrastructure cost or the lost end-user experience.
The solution to this crucial question isn’t new. Load testing has been practiced for all software releases.
In this post, I’ll discuss how to quickly perform a load test with the free Postman app. We’ll also try to pick the best infrastructure between a single A40 GPU, 2X of the same, or upgrading to an L40S GPU.
The Plan: How do we decide on the infrastructure
Here’s our goal.
We host Llama 3.1 8B for our inference and use Ollama to serve our models. However, we don’t know if the hardware that hosts this model is sufficient.
We currently have an A40 GPU with 48 GB of VRAM, 50GB of RAM, and a 9vCPU deployed to serve the inference engine. We rented this infrastructure for US$280.8/month.
Before we go live, we need to ensure that this is sufficient to serve at least 100 users.
Let's assume the other options are to have another instance of the same GPU (the cost doubles) and to rent an L40S GPU with 48 GB VRAM, 62 GB RAM, and 16 vCPUs. The latter costs US$741.6/month.
If you’ve decided to rent a GPU, you have many more options than these two. But let’s consider only these two for now.
We’re going to test these options by giving them the same task. We’re also going to simulate 50 virtual users and increase the number to 100 to see how it affects the response time and error rates.
Let’s begin.
Setting up Postman for LLM Load testing
You can download the Postman app for free from their website. I am not going into the installation instructions.
Let’s assume our LLM exposes an endpoint, api/generatewhich we’ll use to generate output for our prompts. Here’s an example cURL.
curl --location 'https://<api-host>/api/generate' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3.1:8b",
"prompt": "Write a 100 word essay about a random public figure",
"stream": false
}'
The above example asks the Llama3.1:8b in our server to create a random essay for 100 words. Let’s get this done on Postman.
Open the Postman app, create a new collection, and give it a name.
Then click the import button above the newly created collection—and past the example cURL to communicate with your LLM server. Make sure that you’ve selected the correct collection. Then click on import into the collection.
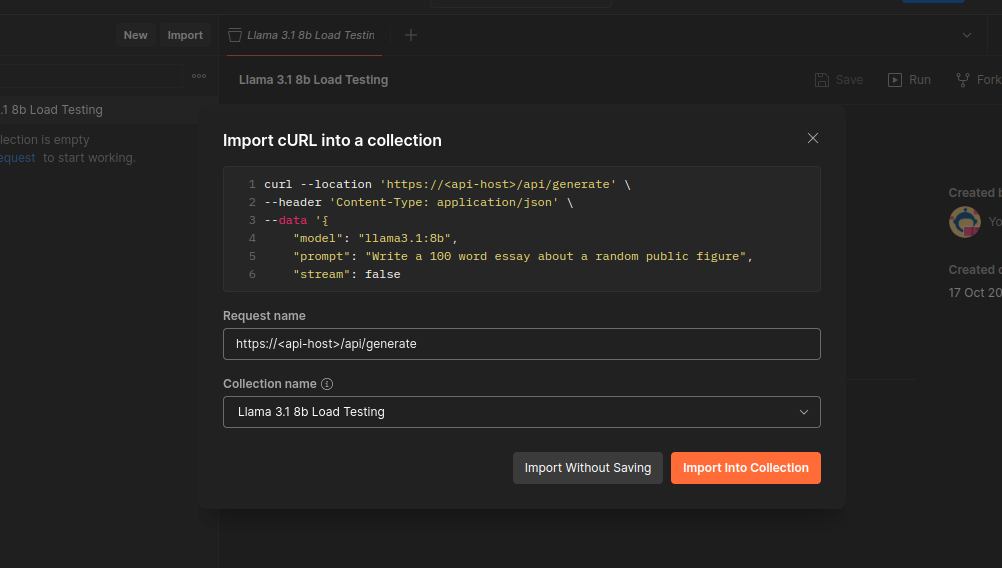
If your API endpoint is gated and needs a token, you can configure it in the newly appearing window. We can also edit the body of the request if needed.
Let’s send a request and see if it works as expected:
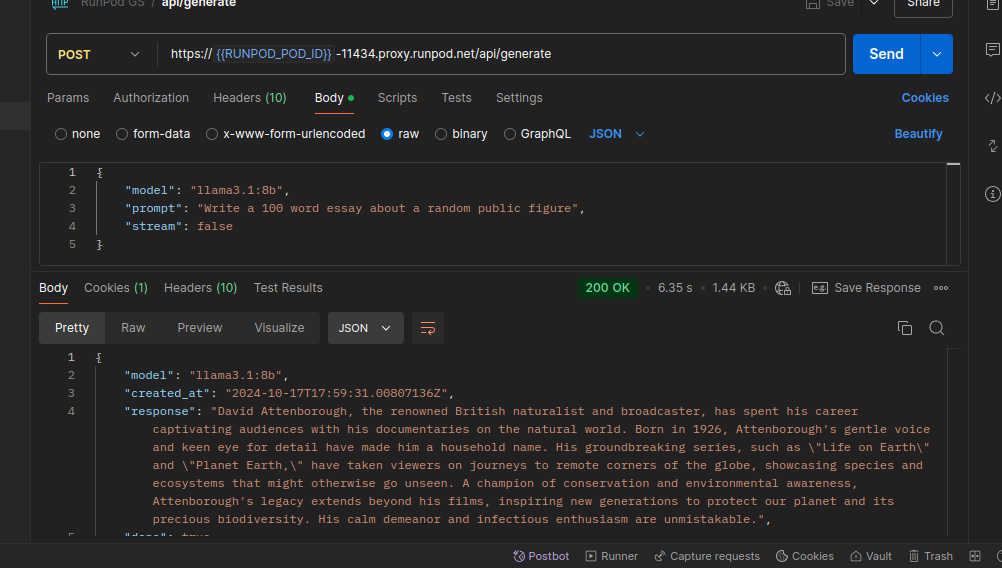
It works fine. We’re ready to start our first load test against this server.
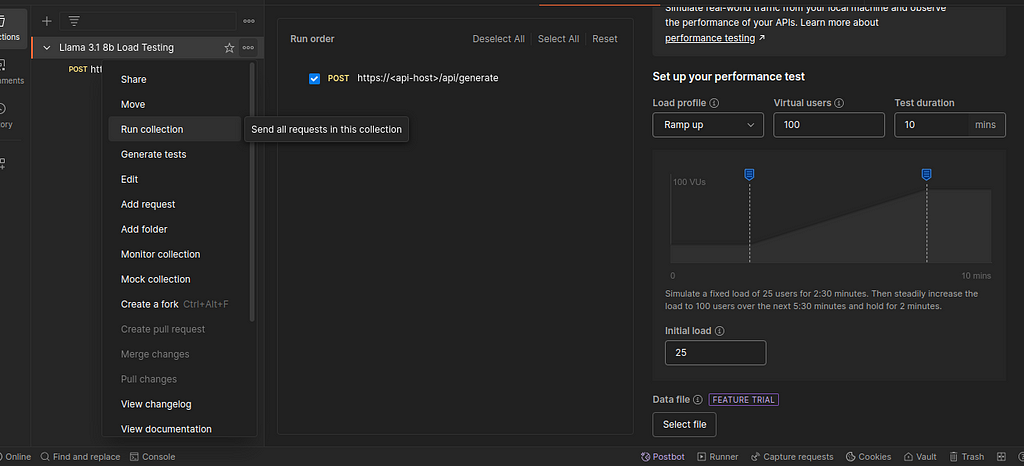
Start by clicking the three dots next to the collection name and click on Run collection it, as shown in the screenshot. Now, we have a few load profiles from which to select. I often use the fixed load profile and the ramp-up profile.
Fixed Load Profile: As its name suggests, this test simulates the configured number of virtual users and starts firing requests. It keeps the same level of users throughout the test.
Ramp-Up Profile: This technique gradually increases the number of virtual users throughout the test and collects request processing time and error rates.
For my test here, I’ll use the Ramp Up profile with 50 initial users and increase it to 100. That’s it; now click run to do a load test.
Load test runs and results — A single A10 GPU.
Postman will now start firing requests with virtual users. You can monitor the process. Here’s what the result would look like.
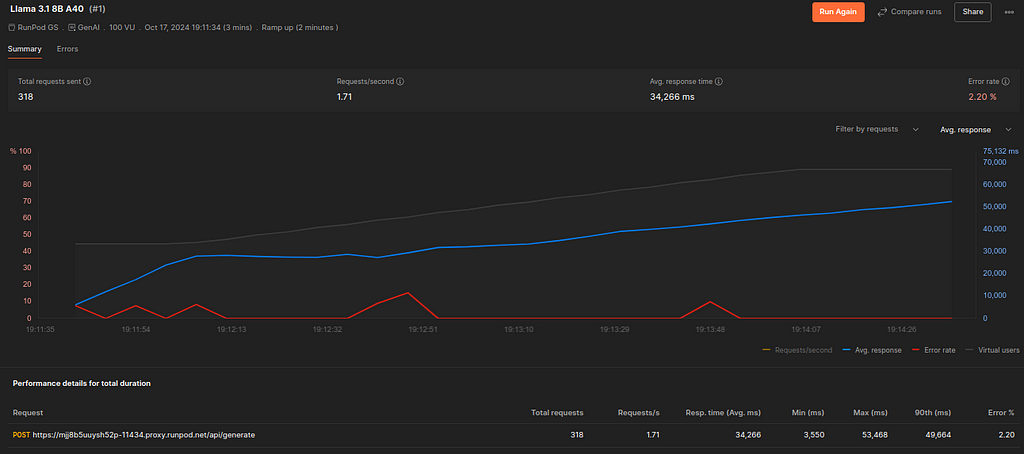
This is our baseline infrastructure: an A10 GPU. The screenshot suggests that Postman sent 318 requests in a 3-minute timeframe. That is, our server responded to roughly 1.71 requests every second. Yet, requests took 34 seconds on average. This means the users will have to wait for half a minute to get a response from our server. Moreover, 2.2% of those requests didn’t get a response.
The chart also shows that response time was initially shorter but worsened as the server received more requests.
Depending on our case, we may live with this performance or try to improve it. But let’s also try the other infrastructures to see how much improvement we can achieve.
Load testing with more GPUs — 2X A10 GPUs
We now switch to a different server with two of those same A10 GPUs. We also continue to use the same load test task.
Here’s what the results look like.
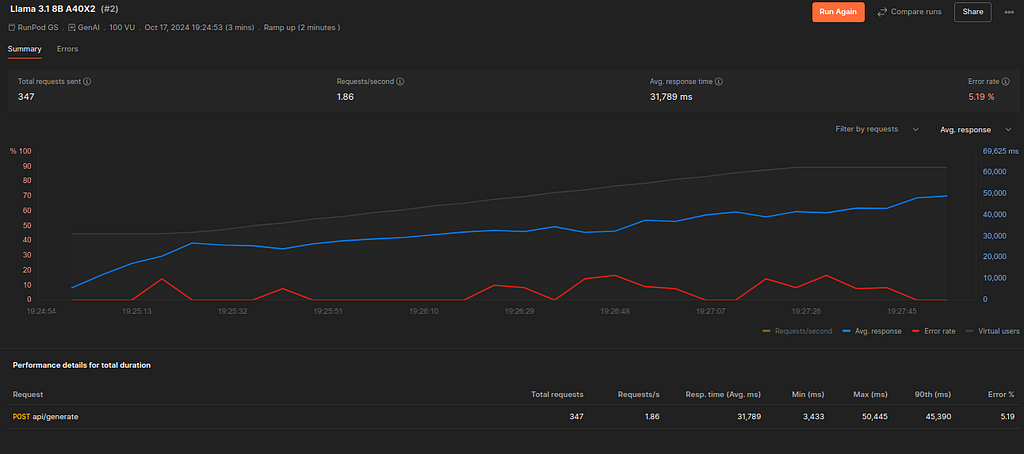
The results show marginal improvements to our baseline infrastructure. The response time has come down from 34 seconds to 31 seconds—minuscule. Yet, the error rate has shot up to 5.19%.
By the looks of it, spending double the cost is not worth the improvement.
Load testing with a better GPU — L40S
L40S is one of NVIDIA's latest-generation GPUs. It has about the same VRAM as A10, though. Let's see how it performs under similar circumstances.
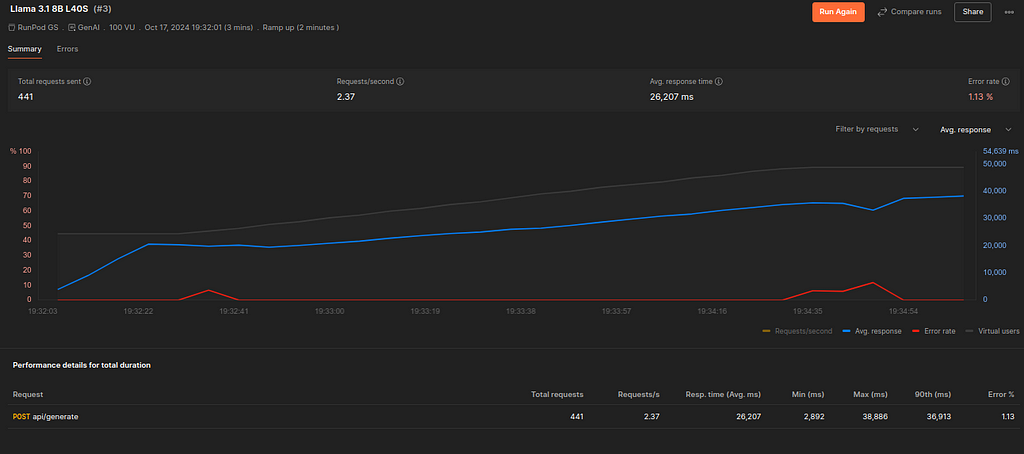
The results are profound.
The average processing time has fallen to 26 seconds—still too long. The error rate has also fallen to 1.11%.
The biggest downside is that L40S costs much more than 2X A10. It may be necessary for mission-critical inference requirements. However, I prefer to stick with a single A10 based on the results for general use.
The Most Valuable LLM Dev Skill is Easy to Learn, But Costly to Practice.
Final Thoughts
Load testing helps us understand how the server would behave at different incoming traffic levels. This is critical for developing LLM-powered applications. We should precisely know the processing time of each request sent to the server.
The easiest way to do a load test is to use Postman. It’s free and straightforward. Of course, it lacks.
In this post, I’ve used Postman to load tests and decide between three infrastructure options. I concluded that a single A10 GPU is better for my task than having more GPUs or upgrading to the latest-generation GPU.
In real applications, we must decide between several choices—infrastructural and design. Load testing them would give us an accurate picture of how the server would behave in situations similar to real life.
Thanks for reading, friend! Besides Medium, I’m on LinkedIn and X, too!
Load testing Self-Hosted LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/GqwoDPL
via IFTTT


