
OpenAI embeddings and clustering for survey analysis — a How-To Guide
OpenAI Embeddings and Clustering for Survey Analysis — A How-To Guide
How to gain insights from survey data and extract topics using embeddings and Large Language Models

It has been exactly 4 months since I changed jobs and have had the time to settle in and continue my little side projects.
The latest one was a survey analyser tool, requested by one of the product owners at my company. He had to go through thousands of company wide survey responses on a quarterly basis, trying to extract actionable improvements for the business
Now that the tool is being used and (hopefully) saving many hours of work to product owners and analysts, I have crafted this how-to guide to help you create a similar tool.
Project flow
We use as input a dataframe with the survey responses (using pandas). The key columns are the comments left by each user. Other fields like department, job title and date submitted could also be analysed but for the minimum viable product, I decided to keep the variables few and simple.
The data for this study was collected through an online survey, and it will remain confidential. For the purpose of this article, the actual data is not shown; the images depict the analysis of a smaller dummy dataset. A similar public dataset be found here.
Once the data is loaded, I used two OpenAI API endpoints: embeddings and chat completions.

Splitting comments into component parts
As shown above, some comments contain multiple pieces of feedback, each touching on different topics. Our hypothesis was that splitting these comments into individual components would make the embeddings more focused, capturing specific topics more accurately. This would result in tighter, more precise clusters, as each embedding would represent a single, distinct idea rather than a mix of topics.
By isolating these distinct parts, clustering algorithms could identify clearer patterns and group similar feedback more effectively. The code used can be found below:
response = client.chat.completion.create(
model = "gpt-4",
messages=[
{
"role":"system",
"content":"""Your task is to dissect a given sentence into its primary
components, identifying the main topics within. Ensure that you do not
introduce additional words into the original comment. If the comment
is empty return ' '. For instance, a comment like 'The vegetables were
good but the fish made me sick' should be split into
['The vegetables were good'], '[but the fish made me sick'].
If the comment only contains a single topic, retain its original form."
},
{
"role": review,
"content": prompt
}
]
)
The resulting comments look like this:

Embedding space
The split-comments were transformed into embeddings, which represent text as vectors in a continuous space. Each dimension captures a specific aspect of the word’s meaning or context. This numerical representation allows us to apply mathematical techniques, such as clustering, to group similar comments.
By converting text into vectors, we can identify underlying trends and patterns in the data that might not be obvious from the raw text, helping us group comments by related topics more accurately.
import pandas as pd
form openai import OpenAI
client = OpenAI(api_key='YOUR-API-KEY')
df = pd.read_csv('your_data.csv')
def get_embedding_openai(comment, model=text-embedding-ada-002):
result = client.embeddings.create(model=model, input=comment)
return result.data[0].embedding
def get_embedding(row):
embedding = get_embedding_openai(row['comment'])
return embedding
df['embedding']= df.apply(get_embedding, axis=1)
Using df.apply, a new column called ‘embedding’ is created which contains the vector form of the comment left in the survey. Working with dataframes is incredible, and very powerful, but for the purpose of topic modelling and extraction, I converted the ‘embedding’ column into a single multidimensional matrix.
from ast import literal_eval
matrix = np.array(df['embedding'].apply(literal_eval).to_list
Visualisation of the embedding space in 2D
Visualizing the embedding space can often reveal hidden patterns in the data. For instance, I noticed a cluster of data points at the exact same location, which turned out to be NaN values. It’s important to clean these up before making additional API calls to avoid wasting tokens.
In order to visualise the embeddings space, we used the TNSE package for dimension reduction. For each comment, the embedding created had 1536 dimensions. This needed to be reduced to 2D or 3D for plotting. We were able to generate a very pretty scatter graph with clear clusters.
tsne = TSNE(n_components=2, perplexity=15, random_state=52, init='random', learning_rate=200)
vis_dims=tsne.fit_transform(matrix)
The plotting was simply done using matplotlib :
import matplotlib.pyplot as plt
x = [x for x, y in vis_dims]
y = [y for x, y in vis_dims]
plt.scatter(x, y, alpha=0.4)
Clustering and labelling
While we visualised the embedding space in 2D and 3D, the topic modelling and clustering is done with all 1536 dimensions taken into account.
OpenAI embeddings return 1536 dimensions because that is the fixed size of the vector representation produced by the specific embedding model being used.
Plotting in 1536 dimensions is impossible because humans can only perceive 3 dimensions (height, width, depth). Visualizing higher-dimensional data requires reducing it to 2D or 3D. While 1536 dimensions capture intricate relationships in the data, visualizing it in fewer dimensions inevitably loses some information, but tools like TSNE help preserving key patterns during the reduction.
We employed the kMeans method for clustering, which divides the data into a specified number of clusters by minimizing the sum of squared distances between data points and their respective centroids. In the future I would compare this clustering technique with other ones and see what the resulting clusters tell us about the data.
For our survey dataset, we chose to create 7 clusters, aiming to assign each review to a specific cluster based on its content.
def cluster_data(n_clusters, matrix):
kmeans = KMeans(n_clusters=n_clusters, init='k-means++', random_state=42)
kmean.fit(matrix)
labels=kmeans.labels_
df['Cluster'] = labels
cluster_data(7)
While visualizing in 2D offers only a simplified view of data originally represented in 1536 dimensions, it still provides valuable insights into the overall structure and distribution of the clusters. The 2D plot allows us to observe the relationships between different clusters and can highlight how closely related or distinct they are from one another.
Personally, I believe plotting in 2D was an oversimplification and did not provide any value added. The plot is attached below, feel free to share your thoughts.
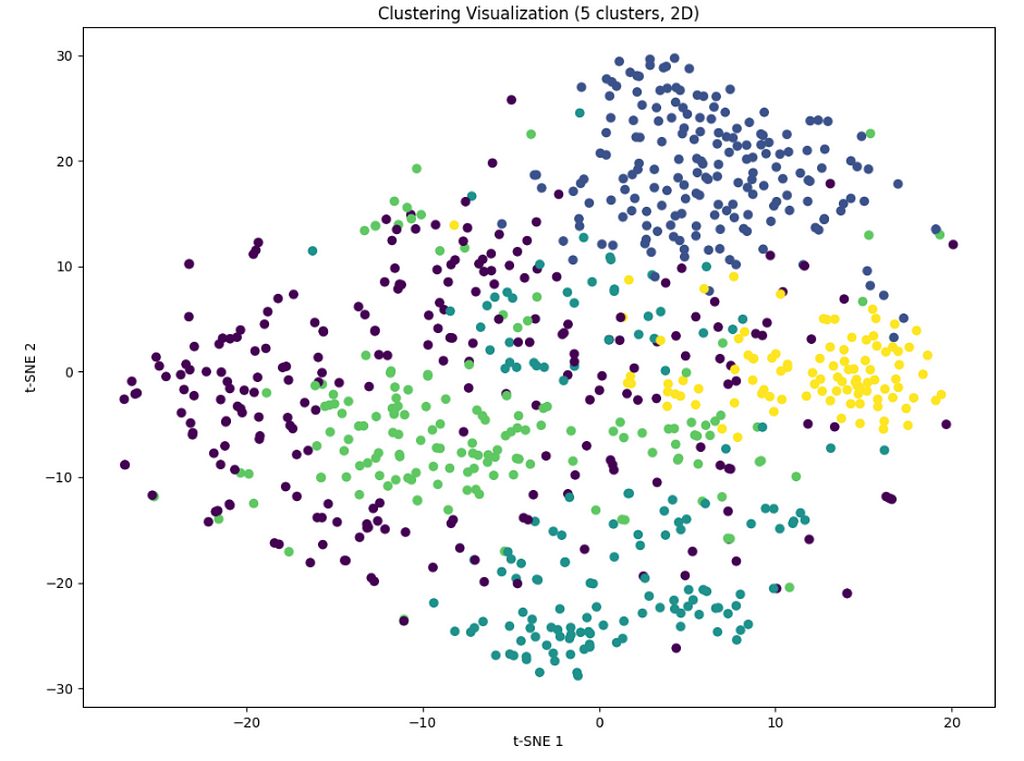
Cluster summarisation
After identifying the clusters, I aimed to summarize the common topics within each one. To do this, I built a function that collects the rows from each cluster and uses the chat completions endpoint to generate concise summaries of the cluster’s key themes.
def get_cluster_themes(
client,
df,
cluster,
max_tokens=4096,
):
reviews = "\n".join(df[df["Cluster"] == cluster].comment)
prompt = [
{
"role": "system",
"content": f''' PROMPT FOR SUMMARISING '''
},
{
"role": "user",
"content": f'''These are the reviews: {reviews}.'''
},
]
response = client.chat.completions.create(
messages=prompt, model="gpt-4", max_tokens=max_tokens
)
return response.choices[0].message.content
A lot of work can be done for the prompt writting, it might one of the more crucial aspects of the project which I dont discuss in detail because it deserves its own post.
The summaries created helped the business quickly understand the main areas of concern or praise from large sets of feedback. By focusing on key topics, companies can prioritize actionable insights and address recurring issues more effectively.
Final cluster results and summary
- [52 comments] Staff are very friendly
- [31 comments] Food is not very varied and feels repetitive
- [29 comments] No strong positive or negative opinion was perceived
- [17 comments] Prices are too high for the portion size
- [8 comments] The queues are too long and inneficient
- [8 comments] There should be ealthy desert options
- [2 comments] There should be no ban on eating at the trading desks
Reflection and improvements
While the project has added value to the business, I believe the comment splitting and clustering still have a long way to go. Deciding on the ideal number of clusters (n=7) was an arbitrary decision made by the stakeholders. More clustering techniques should be compared and a clearer sense of “what a good cluster looks like” should be defined.
While the summarisation is an easy task for an LLM, I think more powerful insights can be drawn. For example identifying low-hanging fruit improvements or flagging users that have a strong sentiments.
An enhancement I’d recommend for the project is outputting the final cluster summaries in JSON format. This would streamline the process of integrating the results into downstream tasks, such as embedding them directly into a PowerPoint presentation or other reporting tools.
Thanks a lot for reading!
For more articles like this, find me on Medium here.
If you have any questions, suggestions or ideas on how to improve, please leave a comment below or get in touch through LinkedIn here.
OpenAI embeddings and clustering for survey analysis — a How-To Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/UrNy3wA
via IFTTT


