
P-Companion: Amazon’s Principled Framework for Diversified Complementary Product Recommendation
A Deep Dive into Amazon’s Complementary Product Recommendation Framework
Introduction
Complementary Product Recommendation (CPR) has become increasingly important for the success of e-commerce platforms. CPR aims to provide the most relevant products that are often purchased and bought together. Phones and phone cases are frequently bought together. Tennis balls are often bought while purchasing tennis rackets. A Mouse is bought after the purchase of a laptop. In this article, we will discuss how Amazon solved CPR as a product-to-product recommendation problem:
Given a “query” product, the goal is to recommend relevant and diverse products that are complementary to the “query” product such that they can be bought together to serve a joint intention.

Predicting such complementary products is a non-trivial task. Let’s understand the challenges faced while solving this problem using a simple example. Given a tennis racket as a “query product”, the platform displays three lists of relevant products.
- List 1 includes three other similar tennis rackets.
- List 2 consists of three tennis balls.
- List 3 features a tennis ball, a racket cover, and a headband.
Typically, List 1 offers similar products, which are less likely to be bought together. List 2 and List 3 provide complementary items. However, List 3 is the more optimal choice as it offers a variety of products that collectively cater to the user’s broader needs for tennis equipment. This example highlights that a good complementary recommendation system should consider relevance and diversity to match the user's expectations.
The paper tries to solve the following three challenges —
- Complementary relationships are asymmetric, and they are not based on similarity measurement. Phone cases can be complementary products bought together with a phone. It's not true the other way around. Solving the problem simply using similarity-based techniques is not the correct approach.
- Complementary recommendations need to consider diversity. It makes much more sense to recommend to users a diverse set of products such as a tennis ball, a headband, and a racket cover instead of recommending three different types of tennis balls.
- Complementary recommendations suffer in cold-start items. Cold-start items are those items that are new to the platform and have very few interactions.
Literature Review
Existing recommender system methods largely focus on user-item relationships using matrix factorization, collaborative filtering, or neural networks, but only some target item-item relationships. These are mostly limited to substitutable (or similar) product relationships but not complementary recommendations. While recent methods based on behavior-based product graphs have attempted to enhance complementary recommendations, they mainly distinguish substitutes and complements without addressing the key challenges we discussed. These techniques use the user’s co-purchase and co-view behavioral interaction data for training.
What is Co-purchase data?
Co-purchase items refer to a pair of items users bought together on the platform. Co-view items refer to a pair of items that were viewed together within a browsing session. Purchase-after-view refers to a pair of items where the user viewed the first item and later purchased the second item. These behaviors provide valuable insights into complementary and substitutable product relationships. Co-purchase data is typically leveraged to recommend complementary products, encouraging users to add related items to their cart. We will discuss how to clean co-purchase data to identify and learn complementary product relationships in the following sections.
Busting Common Assumptions
In the paper, the authors highlight issues with the traditional use of co-purchase and co-view data for modeling complementary and substitutable product relationships. They argue that the common assumption that co-purchase and co-view records represent distinct product relationships (complementary and substitutable, respectively) is inaccurate. Co-purchase patterns, which represent complementary relationships, are more complex and overlap across various categories.
The paper provides two key observations:
- Overlap Between Co-purchase and Co-view Data: The authors analyzed two years of data and observed that there is over 20% overlap between co-purchase and co-view records. This implies that products frequently co-viewed are also co-purchased, blurring the distinction between complementary and substitutable products. This contamination of multi-class signals makes it harder for models to differentiate between these relationships. For example, customers viewed and bought two jackets in the same transaction. This doesn’t mean that the pair of items are complementary.
- Variation Across Product Categories: The overlap between co-purchase and co-view data varies significantly by product category. For example, customers are more likely to co-purchase products they have viewed together (e.g., two different shirts) in categories like apparel. In contrast, the overlap is lower in categories like electronics, where customers are less likely to buy multiple similar items (e.g., two different TVs).
Problem Formulation
Given product catalog features C (details like product title, description, item type, etc.) and customer behavior data B, the goal is to build a recommendation model M. The model M takes a query product i with its product type w_i and a specified diversity degree K, and performs two tasks:
- Predict complementary product types: M first predicts K distinct complementary product types based on the query product type, w_i.
- Generate complementary items: M generates K sets of items, S_{wk}from each predicted complementary product type.
The model's objective is to maximize the probability that the generated complementary items will be jointly co-purchased with the query item, effectively optimizing the recommendations based on co-purchase behavior.
Data Preparation
The authors construct a Behavior-based Product Graph (BPG) to model product relationships based on customer behaviors. The BPG is built using three types of behavioral relationships: co-purchase (B_{cp}), co-view (B_{cv}), and purchase-after-view (B_{pv}). These behaviors are represented as edges between products represented by nodes in the graph and help capture how customers interact with various products.
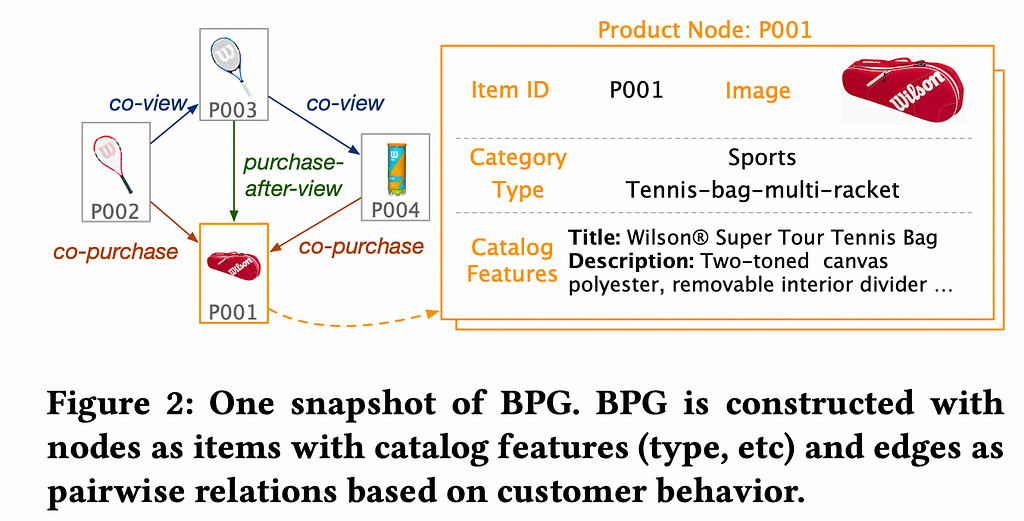
The goal is to prepare a robust dataset containing complementary item pairs from the co-purchase data. To refine the co-purchase data, the authors conducted annotation experiments using Amazon Mechanical Turk (MTurk) to identify the best labeling schema among co-view, co-purchase, and purchase-after-view data. Annotators were asked to classify item pairs as substitutable, complementary, or irrelevant. They found that the following subgraph B_{cp} -(B_{cv} U B_{pv}) which contains co-purchase pairs that were neither co-viewed nor were a part of the purchase-after-view dataset gave the most accurate complementary signals.
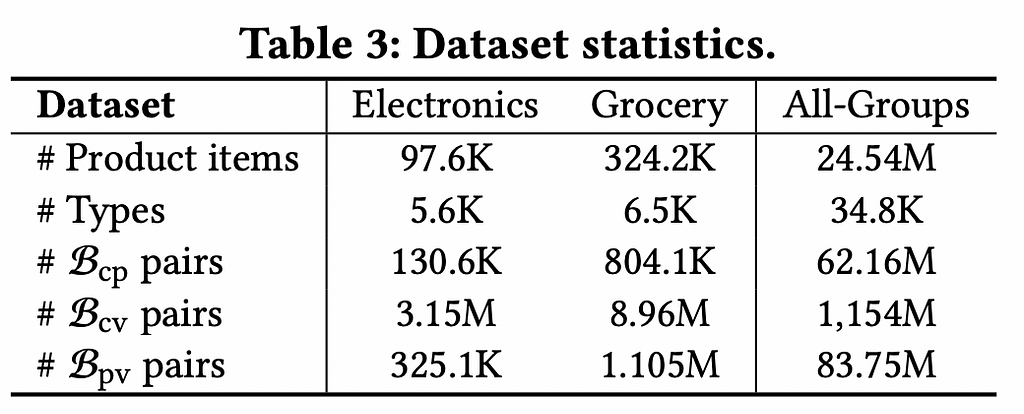
Additionally, they observed that complementary relationships often span multiple product categories (e.g., a tennis racket may have complements like tennis shirts or shoes). To address this, they removed category restrictions used in previous studies and built a general dataset, B_{cp} -(B_{cv} U B_{pv}) across all product types. They prepared a dataset containing 24.54M items spanning 34.8K product types across all product groups. The BPG they constructed had 62.16M co-purchase item pairs, 83.75M purchase-after-view item pairs, and over a billion co-view pairs. Additionally, they prepared two datasets belonging to the Electronics and Grocery categories. Details are shown in the table above.
Model Architecture
P-Companion is a multi-task learning framework, that jointly learns the complementary product types and complementary items associated with each predicted product type. The model has three major components. Let’s discuss all three in detail.
Product2Vec
Product2Vec is a Graph Attention Network-based representation learning model. It uses the item description, historical interaction data, and the graph structure in the BPG to learn product embeddings. The assumption is that the learned embeddings of highly similar products will be close to each other and vice versa for complementary products. The products connected in the subgraph (B_{cv} ∩ B_{pv}) — B_{cp} from the BPG are highly likely to be similar and are used as positive pairs for training the model. These are the products that were both co-viewed and purchased-after-viewed but not co-purchased. Likewise, B_{cp} -(B_{cv} U B_{pv}) (subgraphs containing complementary and hence dissimilar products) are considered negative pairs. The initial embeddings are passed through feedforward layers FFN and transformed into a p-dimensional embedding θ.
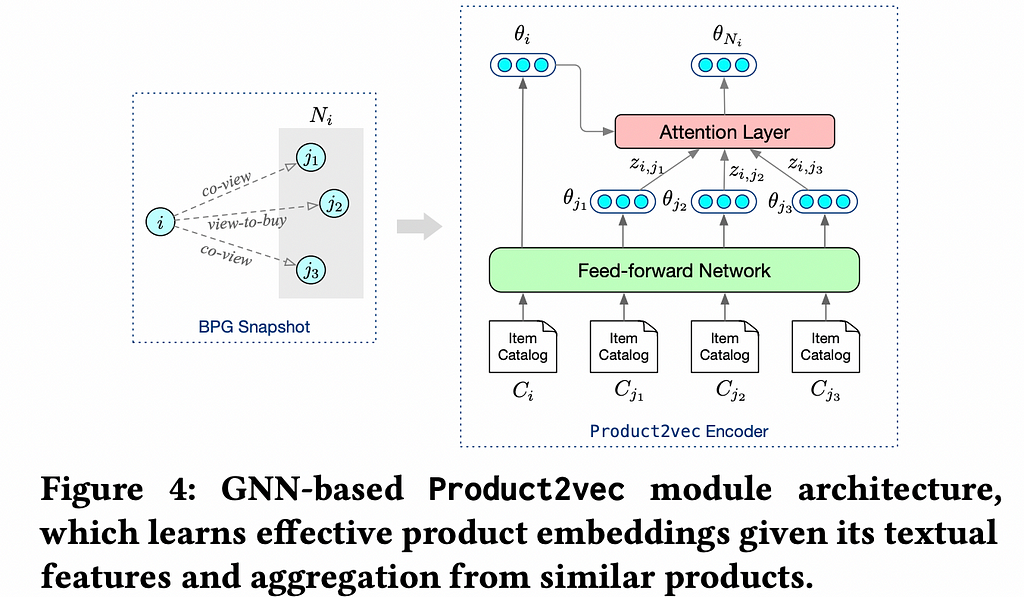
For each item i and embedding θ_i , using the similarity subgraph (B_{cv} ∩ B_{pv}) — B_{cp} in BPG, we fetch the local neighborhood N_i containing {j} items. The labels y_{i,N_i} = 1 denote that they are positive pairs. {θ_j} are the embeddings of the neighboring items. An attention vector z_{ij} is computed using a softmax activation to obtain a weighted neighborhood aggregated embedding θ_{N_i}.
z_{ij} = softmax((θ_i)^T θ_j)
θ_{N_i} = ∑z_{ij} θ_j
Similarly, we fetch the local neighborhood Nˆ_i from the complementary subgraph B_{cp} -(B_{cv} U B_{pv}). Here, y_{i, Nˆ_i} = 0. Using the graph attention layer, we obtain a weighted neighborhood aggregated embedding θ_{Nˆ_i}.
The objective of the model is to learn embeddings θ such that θ_i and θ_{N_i} are projected close to each other and θ_i and θ_{Nˆ_i} are projected away from each other in the embedding space. We can optimize the hinge loss to learn the model weights, FNN.
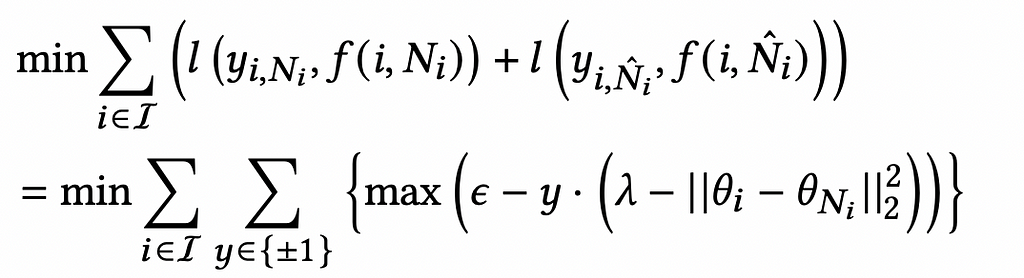
This equation tries to keep the distance between θ_i and θ_{N_i} lesser than λ-ε and the distance between θ_i and θ_{Nˆ_i} greater than λ+ε .
The learned embeddings can be used as pre-trained representations for items. This solves the problem of cold-start items to a great extent. We can obtain an embedding for a new item with only its textual description.
Complementary Type Transition
As discussed earlier, we have pairs of items, (i, j). w_i and w_j are the product types respectively. y_{ij}=±1 are the labels depending on whether they are complementary or not. The Complementary Type Transition component of the P-Companion is a model that performs the complementary type prediction task given a query product type. This component models the asymmetric relationship between the query product type and the complementary product type. For a product type w, we assign two learnable embeddings φ_w and φ^c_w to it, depending on its context position as a query or complementary type. For a pair of product types w_i and w_j , an encoder-decoder architecture is used to transform the query type embedding φ_{w_i} to its complementary base vector γ_{w_i}. γ_{w_i} is used to predict complementary product types.
A hinge loss function is used to optimize the relationship between the predicted complementary product type γ_{w_i} and ground truth predicted complementary product type φ^c_{w_j}.
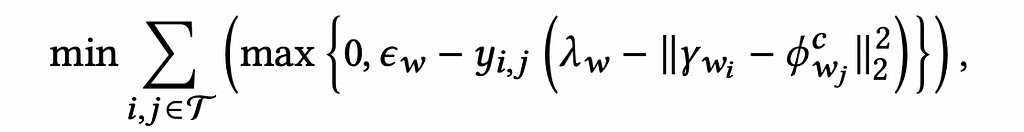
This equation tries to keep the distance between γ_{w_i} and φ^c_{w_j} lesser than λ_w-ε_w when y_{i,j} = 1 while keeping the distance between γ_{w_i} and φ^c_{w_j} greater than λ_w+ε_w when y_{i,j} = -1.
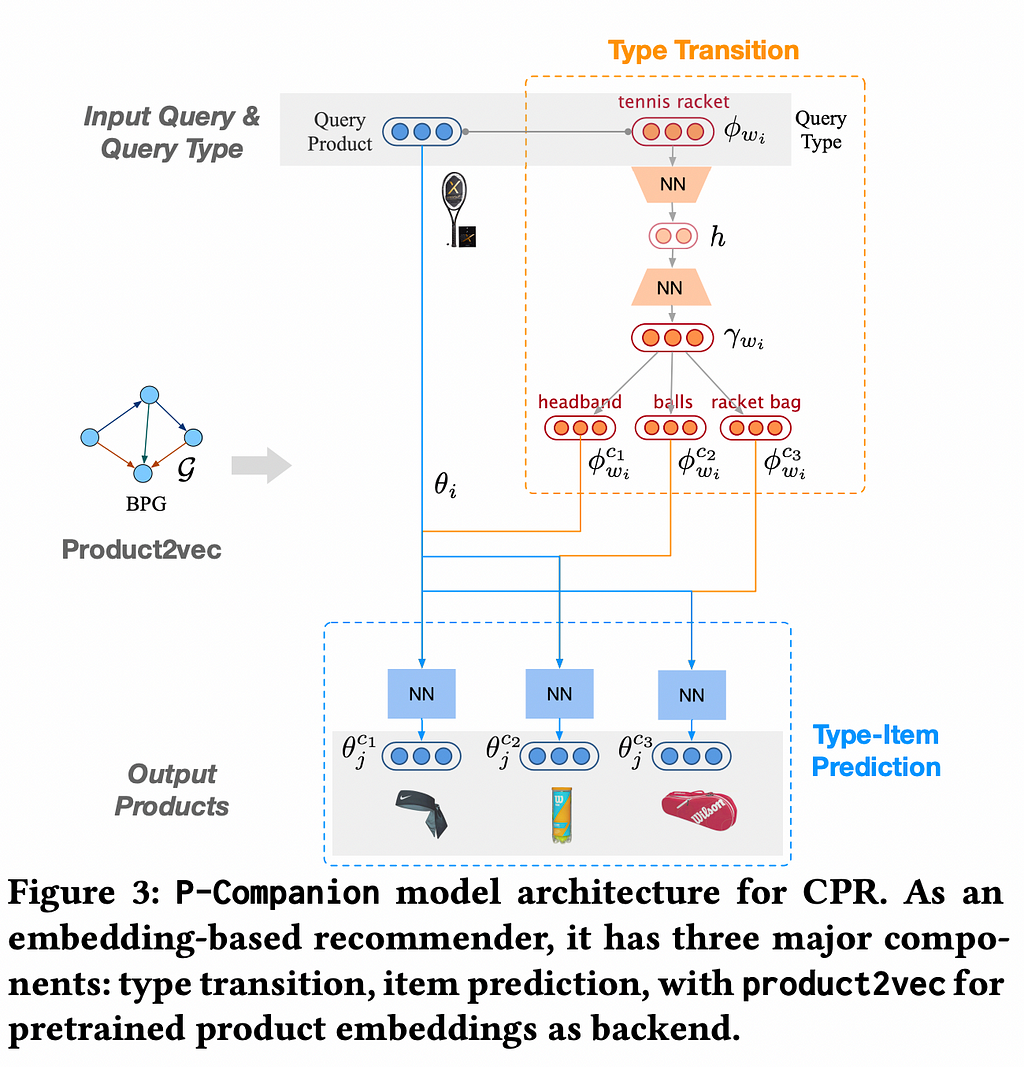
Complementary Item Prediction
The Complementary Item Prediction model performs product recommendations based on the product type obtained from the Complementary Type Transition model. This model takes the query product type’s generated complementary product type embedding γ_{w_i} and the ground truth complementary product type embedding φ^c_{w_c} as inputs and transforms the item embedding θ_i into a complementary item subspace embedding θ^{w_c}_i.
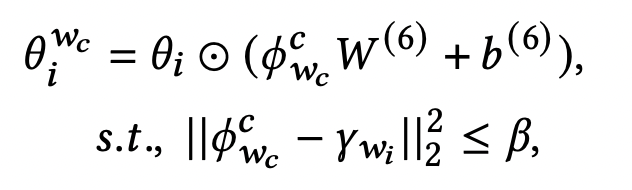
β is the similarity threshold to determine which complementary types will be used to recommend complementary items. Alternatively, we can also explicitly set how many complementary types we want for each query type. This leads to diversity in our recommendations. Based on our design choice, we have multiple complementary type embeddings {φ^c_{w_c}} and the original item embedding θ_i transformed into the complementary item targets {θ^{w_c}_i}.
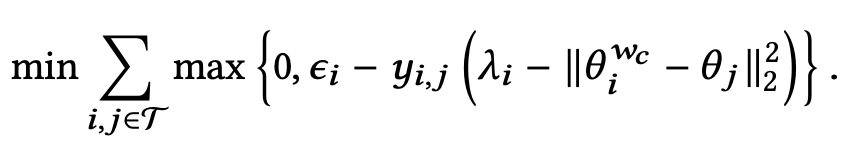
Again, we use hinge loss to optimize the weights of this component. This loss function tries to ensure that the distance between θ^{w_c}_i and θ_j is less than λ_i-ε_i when y_{i,j} = 1 and greater than λ_i_+_i when y_{i,j} = -1.
Implementation Details
Product2Vec has been trained separately as a pre-training task. We can use the embeddings from Product2Vec to jointly train the Complementary Type Transition and Complementary Item Prediction models. The following combined loss function can be used.
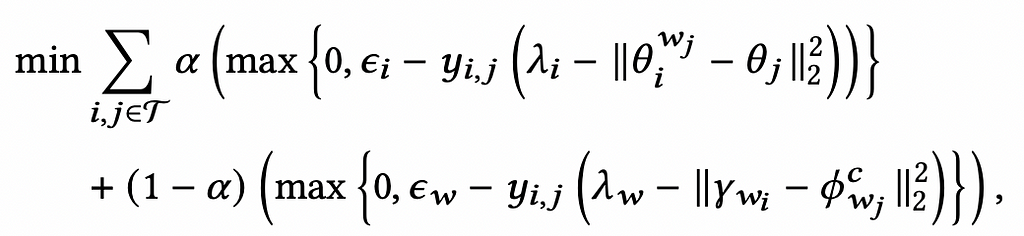
Hyperparameters
The authors kept the product embedding dimension at 128 and the product type embedding dimensions at 64. Distance hyperparameters λ and ε were both set equal to 1.
Inference
During inference, given the item i with product type w_i, we will fetch the item embedding θ_i from Product2Vec and the query product type embedding φ_{w_i}. Using these, the Complementary Type Transition predicts the top-k complementary product types {w^{c_1}_i, w^{c_2}_i, …, w^{c_k}_i}. The Complementary Product Prediction takes as input the item embedding θ_iand the complementary product type embeddings {φ^{c_1}_{w_i}, φ^{c_2}_{w_i}, …, φ^{c_k}_{w_i}} to generate the complementary products {θ_j}.
Evaluation
Offline Evaluation
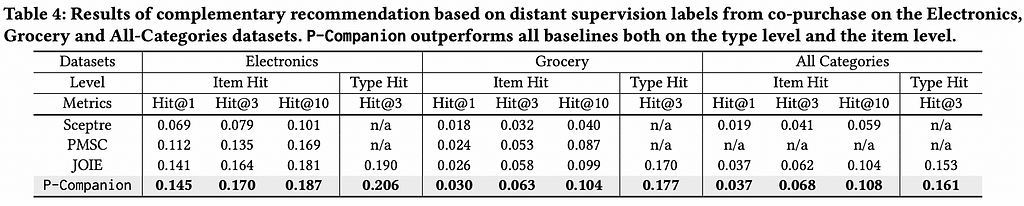
The ranking metric Hit@K was used to evaluate the model on the test co-purchase data. The authors compared P-Companion with Sceptre and JOIE and observed that P-companion outperformed the baseline models across different categories. It performed better with cold-start items.
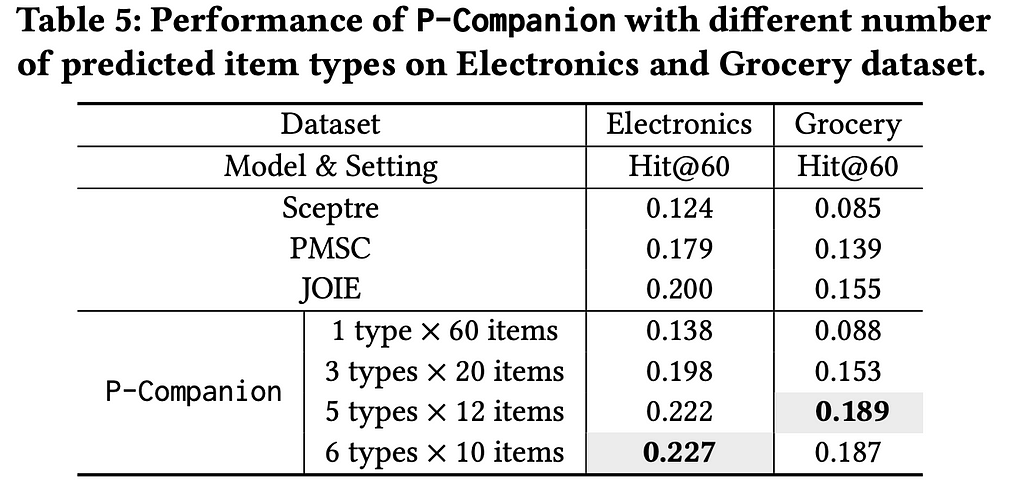
To evaluate the impact of diversity in recommendations, the authors tested P-Companion by analyzing the top 60 recommendations for a common set of query products. Unlike baselines, P-Companion showed items from multiple predicted complementary product types to ensure diversity. The model was tested in four configurations: recommending 60 items from the top 1 type, splitting the recommendations evenly across the top 3, top 5, and top 6 types. This approach enabled P-Companion to offer more balanced and diverse recommendations than traditional methods. Hit@K increased when the model recommended more product types in the Electronics and Grocery datasets.
Online Evaluation
The performance of P-Companion was evaluated in a production environment by conducting an A/B testing experiment. Customer sessions were randomly split, with the control group receiving recommendations based on traditional co-purchase datasets and the treatment group receiving recommendations from P-Companion. The experiment ran for two weeks, and the results showed a +0.23% improvement in product sales and a +0.18% improvement in profit.
These findings demonstrate that P-Companion, which considers both relevance and diversity in recommendations, significantly enhances the customer shopping experience by helping customers discover potential needs more effectively.
References -
- P-Companion: A Principled Framework for Diversified Complementary Product Recommendation (acm.org)
- Hinge loss — Wikipedia
- [1710.10903] Graph Attention Networks (arxiv.org)
I hope you find the article insightful. Thank you for reading!
P-Companion: Amazon’s Principled Framework for Diversified Complementary Product Recommendation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/Sz2VtlN
via IFTTT





