
Under-trained and Unused tokens in Large Language Models
Existence of under-trained and unused tokens and Identification Techniques using GPT-2 Small as an Example

Introduction: Unused and Under-trained Tokens
We have observed the existence of both unused and under-trained tokens in exploration of transformer based large language models (LLMs) such as ChatGPT, of which the tokenization and the model training stay as two separate processes. Unused tokens and under-trained tokens have the following different behaviors:
- Unused Tokens exist in the LLM’s vocabulary and were included during the process training but were not sufficiently seen.
- Under-Trained Tokens may or may not exist in the LLM’s vocabulary and were not at all represented in the training data.
Ideally, the two types of tokens would have very low probabilities to be generated, or equivalently, have extremely negative logit values, so that they should not be generated by the LLMs. However, in practice, users have still found some unused tokens with important logits and the model can sometimes unfortunately predict them. This can lead to undesirable behaviors in LLMs.
Let us consider an LLM which unexpectedly generates nonsensical or inappropriate text because of some tokens that was never trained during the model training. Such occurrences can sometimes cause serious consequences, such as hallucination, leading to lack of accuracy and appropriateness.
We claim this issue is due to the separation between tokenization and the training process of LLMs. In general, these two aspects are never trained together and it did happen that a token in the model’s vocabulary fails to be trained and appears randomly in the output of the model.
In this article, we will demonstrate the existence of unused tokens, including under-trained ones, with some simple experiments using GPT-2 Small . We will also discuss techniques for identifying under-trained tokens.
Existence of Unused Tokens: Experiments on GPT-2 Small
In many LLMs, including GPT-2 Small on which our experiments are executed, there exist unused tokens, that is, tokens existing in the LLM’s vocabulary and were included during the process training but were not sufficiently seen.
In the following examples, we give two cases proving the existence of unused tokens:
Example 1: Reproducing Unused Tokens
In this experiment, we aim to show how GPT-2 Small struggles to reproduce unused tokens, even with very straightforward instructions. Let us now consider the following unused token:"ú" (\u00fa). We would like to instruct GPT-2 small to repeat the token exactly as given by the input.
This is a very simple task: For the given input token "ú", the model have to give the same token as output.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained model (GPT-2 Small) and tokenizer
model_name = "gpt2" # GPT-2 Small (124M parameters)
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# Configure the model's `pad_token_id`
model.config.pad_token_id = model.config.eos_token_id
# Encode a prompt to generate text
token= "\u00fa"
prompt_text = "Rpeats its input exactly" + ', '.join([f"Input: {token}, Output: {token}" for _ in range(20)])+ f"Input: {token}, Output: "
inputs = tokenizer(prompt_text, return_tensors="pt", padding=True)
# Generate text with attention mask
output = model.generate(
inputs['input_ids'],
attention_mask=inputs['attention_mask'], # Explicitly pass attention_mask
max_new_tokens=10, # Maximum length of the generated text
num_return_sequences=1, # Number of sequences to return
no_repeat_ngram_size=2, # Prevent repeating n-grams
do_sample=True, # Enable sampling
top_k=50, # Limit sampling to top k choices
top_p=0.95, # Use nucleus sampling
)
As you can see in the code above, we have designed a prompt as n-shot examples, instructing the model to give exactly the same specific token "ú" . What we see is that the model fails to predict this token: it gives some grabled text as "Output: - ß, *- *-, " . In contrast, when we tested the same task with common tokens such as "a" , the model successfully predicted the correct output, showing the stark difference in performance between frequently encountered and unused tokens.
Example 2: Token Repetition
We now consider the range of unused tokens from indices 177 to 188, the range of unused tokens for GPT2 [1].
Our goal now is to generate sequences of repeated random tokens and evaluate the model’s performance on the repeated sequencee. As discussed in my previous blog post, “How to Interpret GPT-2 Small: Mechanistic Interpretability on Prediction of Repeated Tokens,” transformer-based LLMs have a strong ability to recognize and predict repeated patterns, even for small models such as GPT2 small.
For example, when the model encounters an ‘A’, it searches for the previous occurrence of ‘A’ or a token closely related to ‘A’ in the embedding space. It then identifies the subsequent token, ‘B’, and predicts that the next token following ‘A’ will be ‘B’ or a token similar to ‘B’ in the embedding space.
We begin by defining a function, generate_repeated_tokens which generated a sequence whose second half repeats the first half.
import torch as t
from typing import Tuple
# Assuming HookedTransformer and other necessary components are defined elsewhere.
t.manual_seed(42)
def generate_repeated_tokens(
model: HookedTransformer, seq_len: int, batch: int = 1
) -> Int[Tensor, "batch full_seq_len"]:
'''
Generates a sequence of repeated random tokens
Outputs are:
rep_tokens: [batch, 1+2*seq_len]
'''
bos_token = (t.ones(batch, 1) * model.tokenizer.bos_token_id).long() # generate bos token for each batch
rep_tokens_half = t.randint(177, 188, (batch, seq_len), dtype=t.int64)
rep_tokens = t.cat([bos_token, rep_tokens_half, rep_tokens_half], dim=-1).to(device)
return rep_tokens
Next, we define the run_and_cache_model_repeated_tokens function, which runs the model on the generated repeated tokens, returning the logits and caching the activations. We will use only logits here.
def run_and_cache_model_repeated_tokens(model: HookedTransformer, seq_len: int, batch: int = 1) -> Tuple[t.Tensor, t.Tensor, ActivationCache]:
'''
Generates a sequence of repeated random tokens, and runs the model on it, returning logits, tokens and cacheShould use the `generate_repeated_tokens` function above
Outputs are:
rep_tokens: [batch, 1+2*seq_len]
rep_logits: [batch, 1+2*seq_len, d_vocab]
rep_cache: The cache of the model run on rep_tokens
'''
rep_tokens = generate_repeated_tokens(model, seq_len, batch)
rep_logits, rep_cache = model.run_with_cache(rep_tokens)
return rep_tokens, rep_logits, rep_cache
Now we run the model using the defined run_and_cache_model_repeated_tokens function, generating both the tokens and the associated logits with the following code:
seq_len = 25
batch = 1
(rep_tokens, rep_logits, rep_cache) = run_and_cache_model_repeated_tokens(gpt2_small, seq_len, batch)
rep_cache.remove_batch_dim()
rep_str = gpt2_small.to_str_tokens(rep_tokens)
gpt2_small.reset_hooks()
log_probs = get_log_probs(rep_logits, rep_tokens).squeeze()Copy co
After running the model, we analyze the log probabilities of the predicted tokens for both halves of the repeated sequences. We observed a mean log probability of -17.270 for the first half and -19.675 for the second half for token sequences varying in indices 177 to 188.
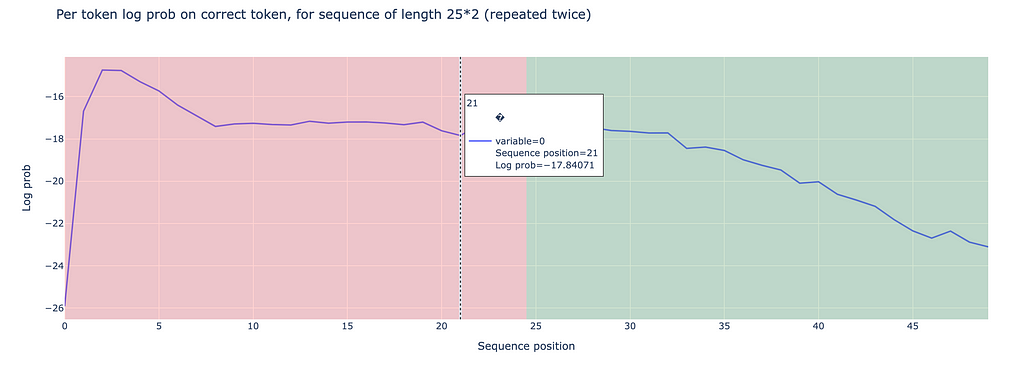
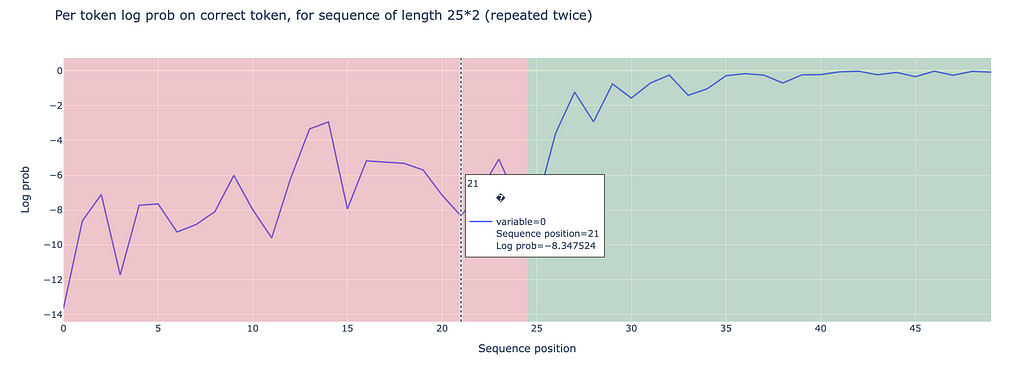
On the other hand, doing the same experiment with a commonly used range of tokens gives different results: When examining token indices 100 to 110, we observe significantly better performance in the second half, with log probabilities of -0.971 compared to -7.327 in the first half.
Under-trained Tokens
The world of LLM would ideally have less surprise if all unused tokens had significantly negative logits and the model would therefore never produce weird texts.
The reality is, unfortunately much more complex. The fact that the creation of the tokenizer and the training of LLM do not happen at the same time lead sometimes to undertrained tokens which are, the the culprits of unexpected behaviors of LLMs.
An example of undertrained tokens is:_SolidGoldMagikarp[1] which was seen sometimes in ChatGPT’s outputs. Now we would like to prove the existence of under-trained tokens in the case of GPT-2 Small.
Example: Reproducing Unused Tokens
In our former experiment of reproducing unused tokens within the GPT-2 Small model, we proved that the token "ú" has hardly any chance to be generated by the model.
Now we slice the logits tensor after runing the model to isolate the outputs to the unused token indices ranging from 177 to 188:
sliced_tensor = gpt2_logits[0, :, 177:188]
Interestingly, we have observed that the logit values for some tokens in this “unused” range reached approximately -1.7, which is to say, there is a probability of around 0.18 for some unused tokens being generated.
This finding highlights the model’s possiblity to assign non-negligible probabilities to some unused tokens, despite they are uncommonly used in most of the context.
Identifying Under-Trained Tokens
In recent years, researchers have proposed techniques to automatically identify under-trained tokens in LLMs. Works in this area include those by Watkins and Rumbelow (2023), and Fell (2023) among which one very interesting approach to identifying under-trained tokens involves analyzing the output embeddings E_{out} generated by the model:
The the method computes the average embedding vector of the unused tokens and uses cosine distances to measure how the vector is similar to all tokens’e embedding vector of the model. Tokens with cosine distances close to the mean embeddings are thus marked as candidates of under-trained tokens. Please check more details in [1].
Conclusion
In conclusion, this blog posts discusses the under-trained tokens LLMs. We do some experiments with GPT-2 Small to illustrate that under-trained tokens can unexpectedly affect model outputs, giving sometimes unpredictable and undesirable behaviors. Recent researches propose methods in identifying under-trained tokens accordingly. For those interested in more details of my implementation, you can check my accompanying notebook.
Reference
[1] Land, S., & Bartolo, M. (2024). Fishing for Magikarp: Automatically detecting under-trained tokens in large language models. arXiv. https://doi.org/10.48550/arXiv.2405.05417.
[2] Jessica Rumbelow and Matthew Watkins. 2023. SolidGoldMagikarp (plus, prompt generation). Blog Post.
[3] Martin Fell. 2023. A search for more ChatGPT / GPT3.5 / GPT-4 “unspeakable” glitch tokens. Blog post.
Under-trained and Unused tokens in Large Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/3UCvQqL
via IFTTT





