
An Introduction to VLMs: The Future of Computer Vision Models
Building a 28% more accurate multimodal image search engine with VLMs.
Until recently, AI models were narrow in scope and limited to understanding either language or specific images, but rarely both.
In this respect, general language models like GPTs were a HUGE leap since we went from specialized models to general yet much more powerful models.
But even as language models progressed, they remained separate from computer vision аreas, each domain advancing in silos without bridging the gap. Imagine what would happen if you could only listen but not see, or vice versa.
My name is Roman Isachenko, and I’m part of the Computer Vision team at Yandex.
In this article, I’ll discuss visual language models (VLMs), which I believe are the future of compound AI systems.
I’ll explain the basics and training process for developing a multimodal neural network for image search and explore the design principles, challenges, and architecture that make it all possible.
Towards the end, I’ll also show you how we used an AI-powered search product to handle images and text and what changed with the introduction of a VLM.
Let’s begin!
What Are VLMs?
LLMs with billions or even hundreds of billions of parameters are no longer a novelty.
We see them everywhere!
The next key focus in LLM research has been more inclined towards developing multimodal models (omni-models) — models that can understand and process multiple data types.
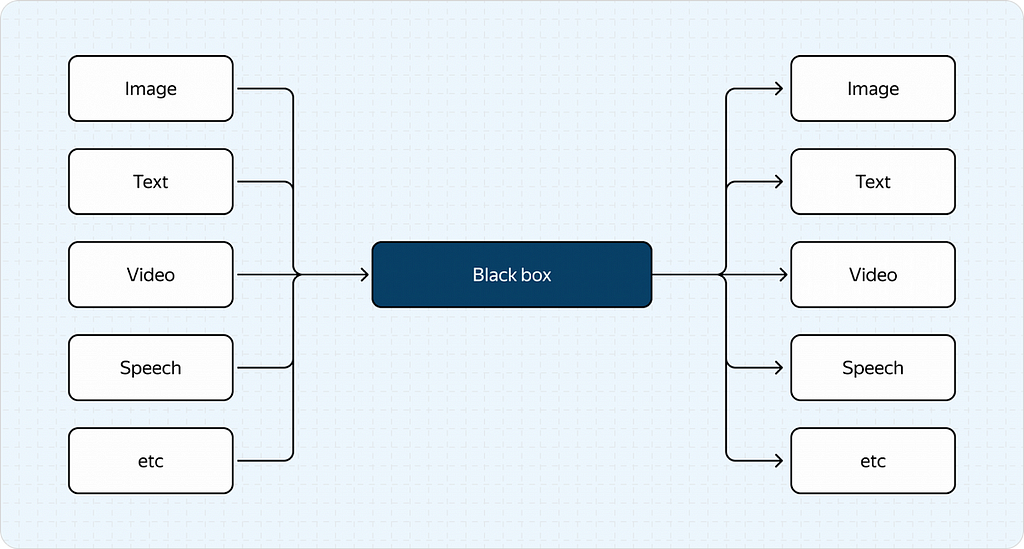
As the name suggests, these models can handle more than just text. They can also analyze images, video, and audio.
But why are we doing this?
Jack of all trades, master of none, oftentimes better than master of one.
In recent years, we’ve seen a trend where general approaches dominate narrow ones.
Think about it.
Today’s language-driven ML models have become relatively advanced and general-purpose. One model can translate, summarize, identify speech tags, and much more.
But earlier, these models used to be task-specific (we have them now as well, but fewer than before).
- A dedicated model for translating.
- A dedicated model for summarizing, etc.
In other words, today’s NLP models (LLMs, specifically) can serve multiple purposes that previously required developing highly specific solutions.
Second, this approach allows us to exponentially scale the data available for model training, which is crucial given the finite amount of text data. Earlier, however, one would need task-specific data:
- A dedicated translation labeled dataset.
- A dedicated summarization dataset, etc.
Third, we believe that training a multimodal model can enhance the performance of each data type, just like it does for humans.
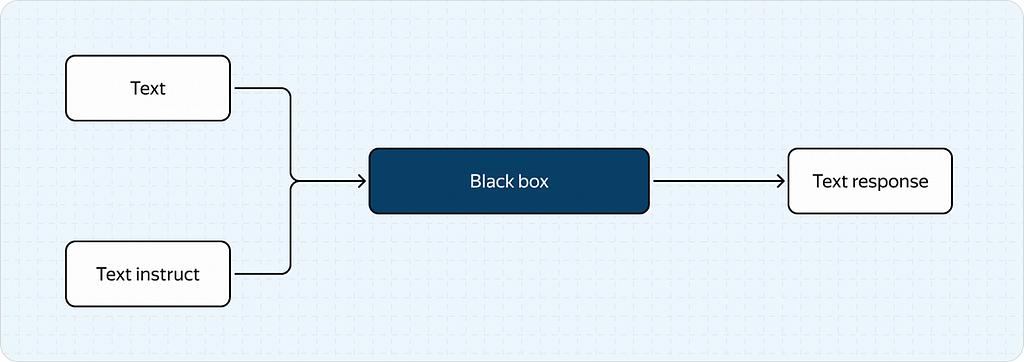
For this article, we’ll simplify the “black box” concept to a scenario where the model receives an image and some text (which we call the “instruct”) as input and outputs only text (the response).
As a result, we end up with a much simpler process as shown below:
We’ll discuss image-discriminative models that analyze and interpret what an image depicts.
Before delving into the technical details, consider the problems these models can solve.
A few examples are shown below:

- Top left image: We ask the model to describe the image. This is specified with text.
- Top mid image: We ask the model to interpret the image.
- Top right image: We ask the model to interpret the image and tell us what would happen if we followed the sign.
- Bottom image: This is the most complicated example. We give the model some math problems. From these examples, you can see that the range of tasks is vast and diverse.
VLMs are a new frontier in computer vision that can solve various fundamental CV-related tasks (classification, detection, description) in zero-shot and one-shot modes.
While VLMs may not excel in every standard task yet, they are advancing quickly.
Now, let’s understand how they work.
VLM Architecture
These models typically have three main components:
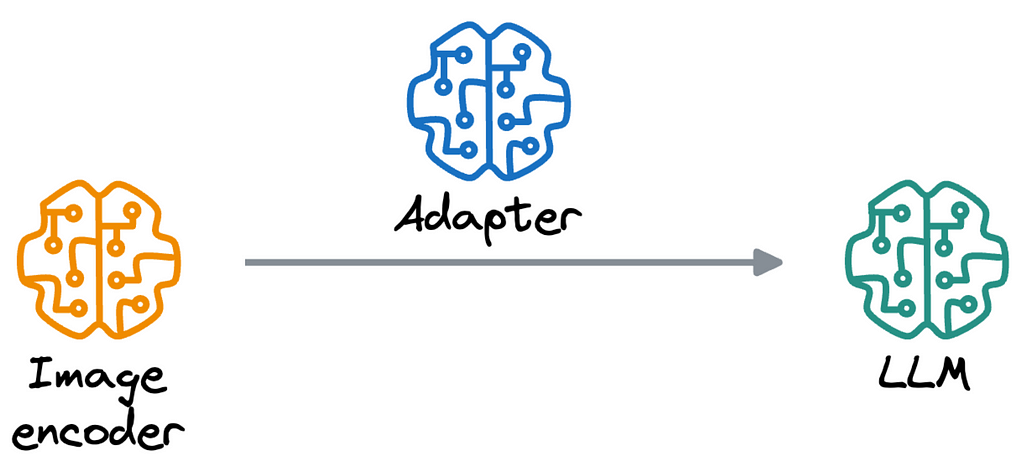
- LLM — a text model (YandexGPT, in our case) that doesn’t understand images.
- Image encoder — an image model (CNN or Vision Transformer) that doesn’t understand text.
- Adapter — a model that acts as a mediator to ensure that the LLM and image encoder get along well.
The pipeline is pretty straightforward:
- Feed an image into the image encoder.
- Transform the output of the image encoder into some representation using the adapter.
- Integrate the adapter’s output into the LLM (more on that below).
- While the image is processed, convert the text instruct into a sequence of tokens and feed them into the LLM.
More Information About Adapters
The adapter is the most exciting and important part of the model, as it precisely facilitates the communication/interaction between the LLM and the image encoder.
There are two types of adapters:
- Prompt-based adapters
- Cross-attention-based adapters
Prompt-based adapters were first proposed in BLIP-2 and LLaVa models.
The idea is simple and intuitive, as evident from the name itself.
We take the output of the image encoder (a vector, a sequence of vectors, or a tensor — depending on the architecture) and transform it into a sequence of vectors (tokens), which we feed into the LLM. You could take a simple MLP model with a couple of layers and use it as an adapter, and the results will likely be pretty good.
Cross-attention-based adapters are a bit more sophisticated in this respect.
They were used in recent papers on Llama 3.2 and NVLM.
These adapters aim to transform the image encoder’s output to be used in the LLM’s cross-attention block as key/value matrices. Examples of such adapters include transformer architectures like perceiver resampler or Q‑former.
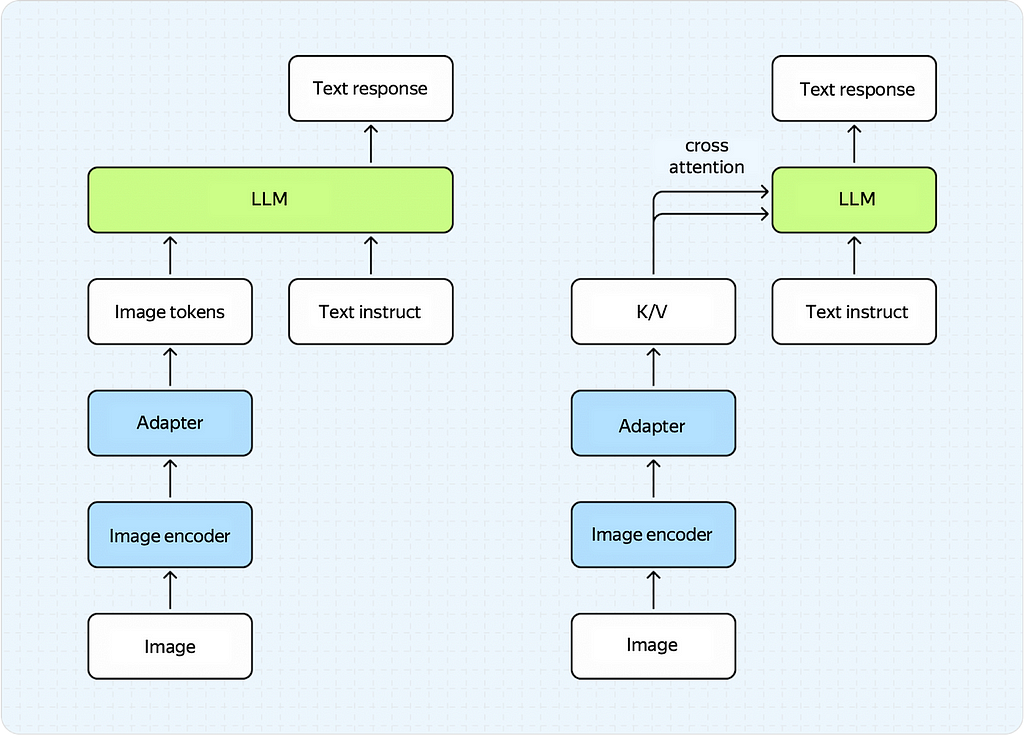
Prompt-based adapters (left) and Cross-attention-based adapters (right)
Both approaches have pros and cons.
Currently, prompt-based adapters deliver better results but take away a large chunk of the LLM’s input context, which is important since LLMs have limited context length (for now).
Cross-attention-based adapters don’t take away from the LLM’s context but require a large number of parameters to achieve good quality.
VLM Training
With the architecture sorted out, let’s dive into training.
Firstly, note that VLMs aren’t trained from scratch (although we think it’s only a matter of time) but are built on pre-trained LLMs and image encoders.
Using these pre-trained models, we fine-tune our VLM in multimodal text and image data.
This process involves two steps:
- Pre-training
- Alignment: SFT + RL (optional)
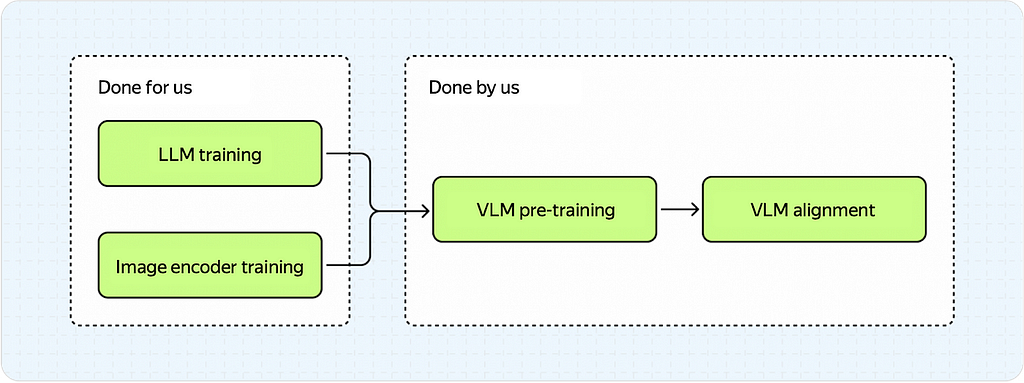
Training procedure of VLMs (Image by Author)
Notice how these stages resemble LLM training?
This is because the two processes are similar in concept. Let’s take a brief look at these stages.
VLM Pre-training
Here’s what we want to achieve at this stage:
- Link the text and image modalities together (remember that our model includes an adapter we haven’t trained before).
- Load world knowledge into our model (the images have a lot of specifics, for one, OCR skills).
There are three types of data used in pre-training VLMs:
- Interleaved Pre-training: This mirrors the LLM pre-training phase, where we teach the model to perform the next token prediction task by feeding it web documents. With VLM pre-training, we pick web documents with images and train the model to predict text. The key difference here is that a VLM considers both the text and the images on the page. Such data is easy to come by, so this type of pre-training isn’t hard to scale up. However, the data quality isn’t great, and boosting it proves to be a tough job.

Image-Text Pairs Pre-training: We train the model to perform one specific task: captioning images. You need a large corpus of images with relevant descriptions to do that. This approach is more popular because many such corpora are used to train other models (text-to-image generation, image-to-text retrieval).

Instruct-Based Pre-training: During inference, we’ll feed the model images and text. Why not train the model this way from the start? This is precisely what instruct-based pre-training does: It trains the model on a massive dataset of image-instruct-answer triplets, even if the data isn’t always perfect.

How much data is needed to train a VLM model properly is a complex question. At this stage, the required dataset size can vary from a few million to several billion (thankfully, not a trillion!) samples.
Our team used instruct-based pre-training with a few million samples. However, we believe interleaved pre-training has great potential, and we’re actively working in that direction.
VLM Alignment
Once pre-training is complete, it’s time to start on alignment.
It comprises SFT training and an optional RL stage. Since we only have the SFT stage, I’ll focus on that.
Still, recent papers (like this and this) often include an RL stage on top of VLM, which uses the same methods as for LLMs (DPO and various modifications differing by the first letter in the method name).
Anyway, back to SFT.
Strictly speaking, this stage is similar to instruct-based pre-training.
The distinction lies in our focus on high-quality data with proper response structure, formatting, and strong reasoning capabilities.
This means that the model must be able to understand the image and make inferences about it. Ideally, it should respond equally well to text instructs without images, so we’ll also add high-quality text-only data to the mix.
Ultimately, this stage’s data typically ranges between hundreds of thousands to a few million examples. In our case, the number is somewhere in the six digits.
Quality Evaluation
Let’s discuss the methods for evaluating the quality of VLMs. We use two approaches:
- Calculate metrics on open-source benchmarks.
- Compare the models using side-by-side (SBS) evaluations, where an assessor compares two model responses and chooses the better one.
The first method allows us to measure surrogate metrics (like accuracy in classification tasks) on specific subsets of data.
However, since most benchmarks are in English, they can’t be used to compare models trained in other languages, like German, French, Russian, etc.
While translation can be used, the errors introduced by translation models make the results unreliable.
The second approach allows for a more in-depth analysis of the model but requires meticulous (and expensive) manual data annotation.
Our model is bilingual and can respond in both English and Russian. Thus, we can use English open-source benchmarks and run side-by-side comparisons.
We trust this method and invest a lot in it. Here’s what we ask our assessors to evaluate:
- Grammar
- Readability
- Comprehensiveness
- Relevance to the instruct
- Errors (logical and factual)
- Hallucinations
We strive to evaluate a complete and diverse subset of our model’s skills.
The following pie chart illustrates the distribution of tasks in our SbS evaluation bucket.
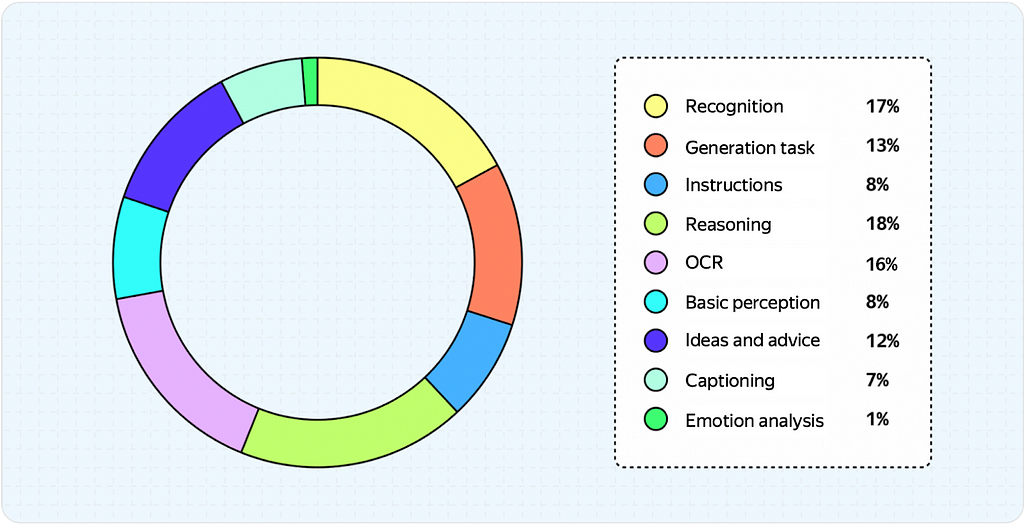
This summarizes the overview of VLM fundamentals and how one can train a model and evaluate its quality.
Pipeline Architecture
This spring, we added multimodality to Neuro, an AI-powered search product, allowing users to ask questions using text and images.
Until recently, its underlying technology wasn’t truly multimodal.
Here’s what this pipeline looked like before.
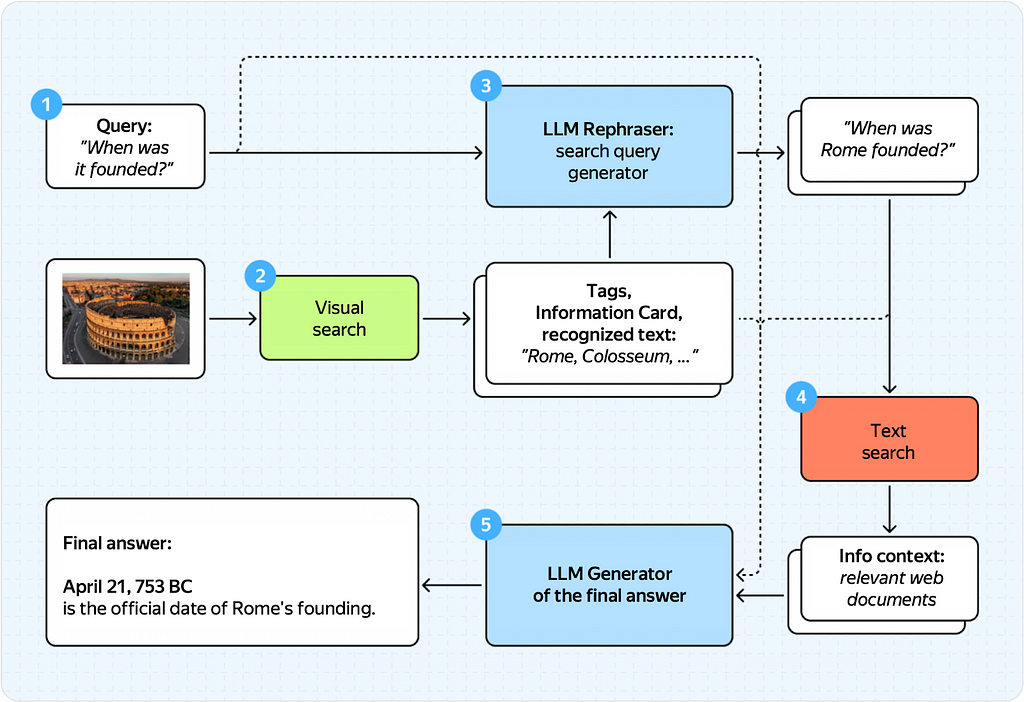
This diagram seems complex, but it’s straightforward once you break it down into steps.
Here’s what the process used to look like
- The user submits an image and a text query.
- We send the image to our visual search еngine, which would return a wealth of information about the image (tags, recognized text, information card).
- We formulate a text query using a rephraser (a fine-tuned LLM) with this information and the original query.
- With the rephrased text query, we use Yandex Search to retrieve relevant documents (or excerpts, which we call infocontext).
- Finally, with all this information (original query, visual search information, rephrased text query, and info context), we generate the final response using a generator model (another fine-tuned LLM).
Done!
As you can see, we used to rely on two unimodal LLMs and our visual search engine. This solution worked well on a small sample of queries but had limitations.
Below is an example (albeit slightly exaggerated) of how things could go wrong.
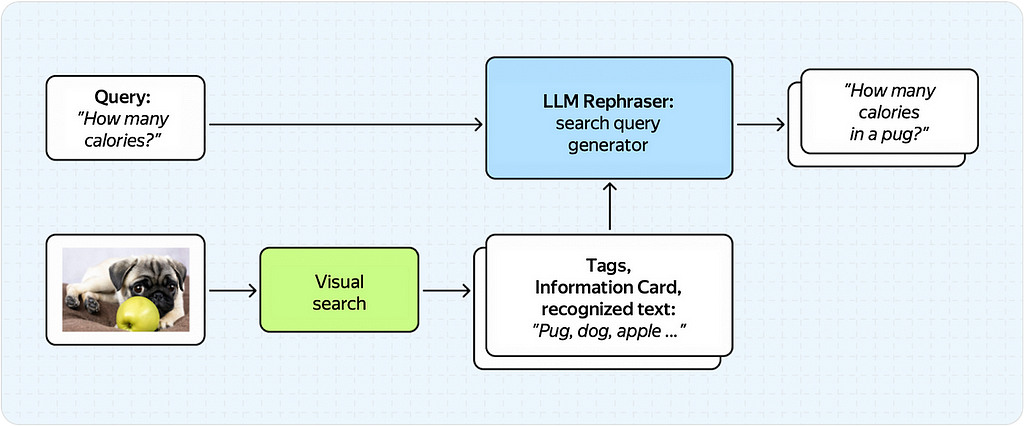
Here, the rephraser receives the output of the visual search service and simply doesn’t understand the user’s original intent.
In turn, the LLM model, which knows nothing about the image, generates an incorrect search query, getting tags about the pug and the apple simultaneously.
To improve the quality of our multimodal response and allow users to ask more complex questions, we introduced a VLM into our architecture.
More specifically, we made two major modifications:
- We replaced the LLM rephraser with a VLM rephraser. Essentially, we started feeding the original image to the rephraser’s input on top of the text from the visual search engine.
- We added a separate VLM captioner to the pipeline. This model provides an image description, which we use as info context for the final generator.
You might wonder
Why not make the generator itself VLM-based?
That’s a good idea!
But there’s a catch.
Our generator training inherits from Neuro’s text model, which is frequently updated.
To update the pipeline faster and more conveniently, it was much easier for us to introduce a separate VLM block.
Plus, this setup works just as well, which is shown below:
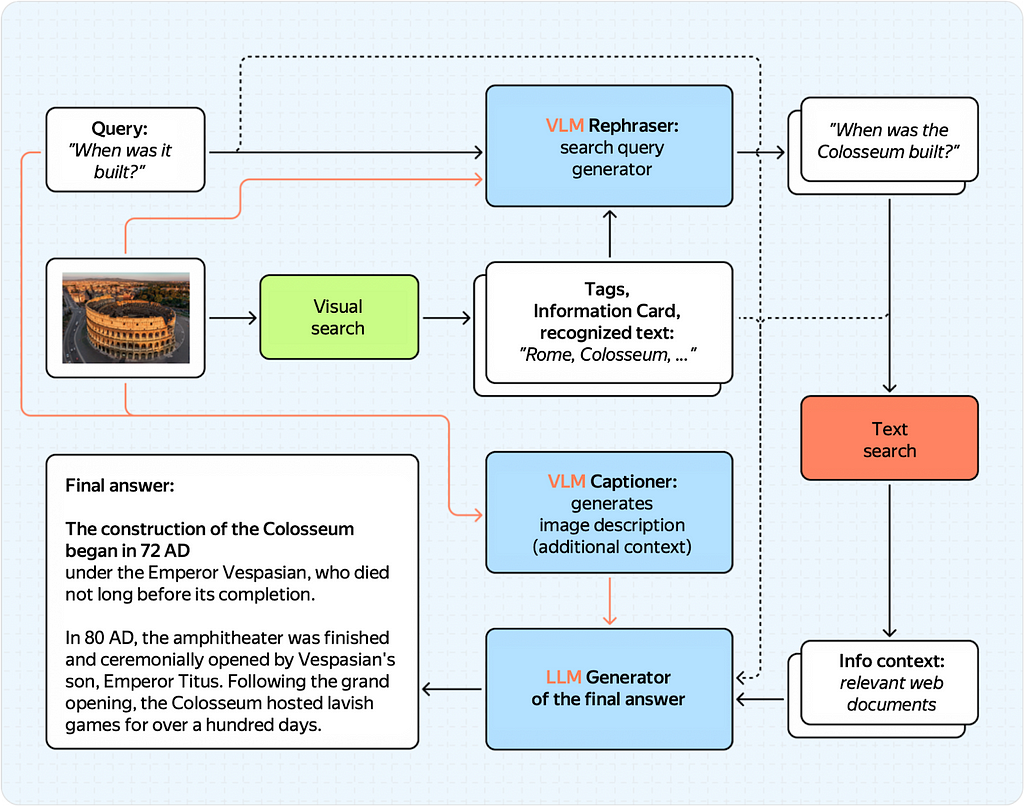
Training VLM rephraser and VLM captioner are two separate tasks.
For this, we use mentioned earlierse VLM, as mentioned e for thise-tuned it for these specific tasks.
Fine-tuning these models required collecting separate training datasets comprising tens of thousands of samples.
We also had to make significant changes to our infrastructure to make the pipeline computationally efficient.
Gauging the Quality
Now for the grand question:
Did introducing a VLM to a fairly complex pipeline improve things?
In short, yes, it did!
We ran side-by-side tests to measure the new pipeline’s performance and compared our previous LLM framework with the new VLM one.
This evaluation is similar to the one discussed earlier for the core technology. However, in this case, we use a different set of images and queries more aligned with what users might ask.
Below is the approximate distribution of clusters in this bucket.

Our offline side-by-side evaluation shows that we’ve substantially improved the quality of the final response.
The VLM pipeline noticeably increases the response quality and covers more user scenarios.

We also wanted to test the results on a live audience to see if our users would notice the technical changes that we believe would improve the product experience.
So, we conducted an online split test, comparing our LLM pipeline to the new VLM pipeline. The preliminary results show the following change:
- The number of instructs that include an image increased by 17%.
- The number of sessions (the user entering multiple queries in a row) saw an uptick of 4.5%.
To reiterate what was said above, we firmly believe that VLMs are the future of computer vision models.
VLMs are already capable of solving many out-of-the-box problems. With a bit of fine-tuning, they can absolutely deliver state-of-the-art quality.
Thanks for reading!
An Introduction to VLMs: The Future of Computer Vision Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/xTavU3B
via IFTTT


