
Creating Dynamic Pivots on Snowflake Tables with dbt
Leverage dbt and its advanced scripting functionality to generate dynamic pivot tables that adapt to changing pivot values

What are Pivoted Tables?
When dealing with tabular data, you often will have that data laid out in a format that best suits day-to-day operations. For example, rows that represent purchase transactions for different customers.
A pivot table allows you to rotate rows into columns, creating a more organized and digestible format for large datasets. You can also aggregate data, such as calculating sums, averages, or counts, and display these results as unique columns for each summarized category.
Let’s take a look at a visual that will help describe it. Here, we’re grouping by the user value, then taking the sum of the count of each transaction and creating a unique column for each product.
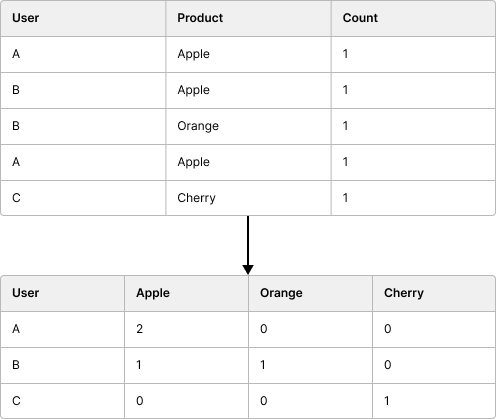
The Manual Approach
Most of us will approach this by writing SQL with case statements for each category. While this works for simple cases, if you have a more dynamic set of values that you need to include in the case statement, maintaining this can be a nightmare, leading to troubles with data analysis where you have incomplete data.
SELECT
User,
SUM(CASE WHEN Product = 'Apple' THEN Count ELSE 0 END) AS Apple,
SUM(CASE WHEN Product = 'Orange' THEN Count ELSE 0 END) AS Orange,
SUM(CASE WHEN Product = 'Cherry' THEN Count ELSE 0 END) AS Cherry
FROM
your_table_name
GROUP BY
User;
I’ve tried solving this problem using raw SQL and creating a stored procedure that handles this. However, I could never solve this until I ran across dbt and leveraged some of its more advanced capabilities.
What is dbt?
dbt is an incredibly popular tool in the data community today. If you search the internet for terms like Modern Data Stack in almost every image or article, you’ll see a reference to dbt. It’s everywhere; you must learn it if you’re a data practitioner.
dbt stands for Data Build Tool, and according to their website, they describe it as:
dbt™ is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Anyone on the data team can safely contribute to production-grade data pipelines.
By leveraging dbt, you can create dynamic pivots! Let’s take a look.
Dynamic Pivot Tables with dbt
As you become more proficient in DBT, you will probably run across the concepts of Jina and Macros. Utilizing Jinja is a templating language used throughout the Python ecosystem. dbt supports using Jinja to create scripts that, when compiled, output standard SQL code for your database’s or warehouse’s interpretation. You might recognize it from its syntax utilizing curly braces { }. Jinja allows us to provide logic-based interaction with our code creation to build these dynamic queries.
If we listed off the steps to build that query above dynamically, it might look like this:
- Get a list of all unique products
- Clean up any product names that violate column naming conventions (spaces, special characters, numbers, etc.)
- Create a loop that goes through the list and builds a CASE statement for each
Let’s see how we do that in dbt.
First, let’s get the list of all products — we will wrap this as a Jinja function, which won’t end up being in the final SQL code but will be executed when dbt compiles the SQL file.

That’s a very simple select statement to get all distinct product names. However, you can put any SQL select logic in that query you need. Note that the function’s name is in the first line after the keyword set.
Next, we need to run that query and convert the results into a list we can loop or iterate over later. The first line will execute the query we just defined, and the following code will convert it into a list of values. The else statement is needed for this to run successfully, where you need to generate an empty list if, for some reason, the query returns no results.

We must build our logic to loop over the list and dynamically create our CASE statement. Notice that we have a normal query that starts with the first two lines, and then we see additional Jinja syntax inserted that will create our dynamic SQL. There are two additional tricks in here:
- Replacing invalid characters with underscores — such as spaces and hyphens. You can add as many as you’d like to the replacement list by simply piping them together.
- Lowering the text for consistency as well.
- And the “loop.last” conditional will insert a comma after all of the CASE lines except the last one.

When you compile all of the above code, you get the following perfect SQL syntax
select
user,
count(case when product = 'Apple' then 1 end) as apple,
count(case when product = 'Orange' then 1 end) as orange
from pivot_example
group by user
The output is a perfectly formed pivot of the original data.
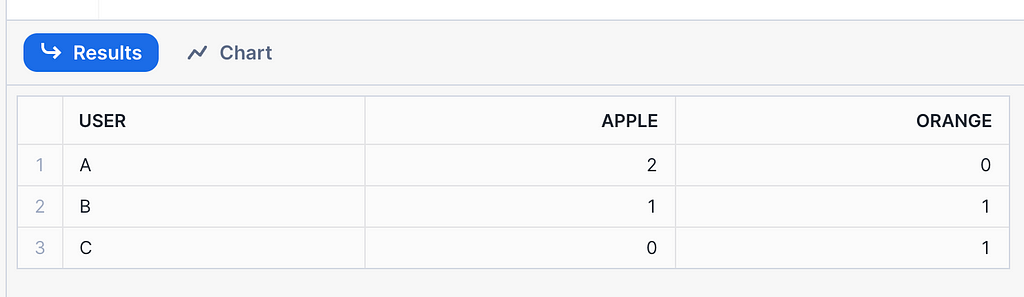
Updates to the Categorical Values
As the article suggests, we want to make these dynamic. Let’s try this by inserting two new rows with two new products. Notice that the second product has invalid spaces in its name, which cannot be used as a column name. The replace commands will take care of that for us.
INSERT INTO pivot_example (user, product, count) VALUES
('C', 'Cherry', 1),
('C', 'Lemon and Lime', 1);
Next, we need to build the view again in dbt, and the pivot code will be updated in the data warehouse. Notice we have our two new products automatically added!
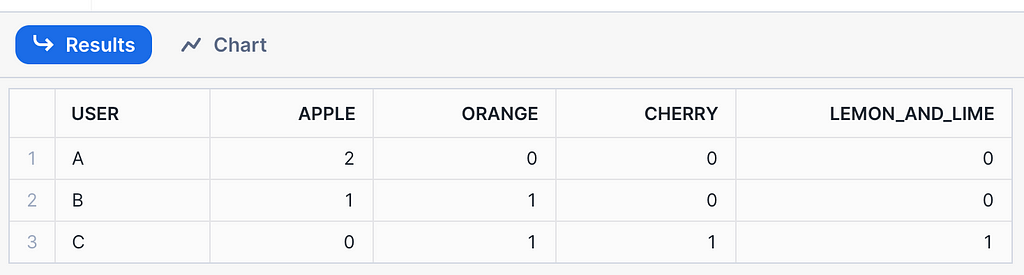
Keeping the View Up-to-Date
As mentioned above, we needed to rebuild the pivot view in dbt for the new values to be recognized. This can be achieved with simple automation in dbt, known as a Job. You can create one that runs nightly or whatever interval makes sense for you, and it will run just the new pivoted view build command. It will be a fast and efficient job ensuring your views always reflect the latest values.
Source Code for Reference
If you want to see more complex example code, please look at this Gist on GitHub. You can also see the fully compiled version of the query in this Gist. Finally, the simple example used in this blog can also be found on GitHub.
Conclusion
In conclusion, mastering pivot tables with dbt simplifies transforming and organizing large datasets and enhances the flexibility and maintainability of your data workflows. By utilizing Jinja and macros in dbt, you can create dynamic, error-free SQL queries that adapt to changes in your data, ensuring your analytics remain accurate and up-to-date. This approach saves time and effort and empowers data practitioners to focus more on deriving insights rather than wrestling with complex SQL scripts.
If you enjoy reading stories like these and want to support me as a writer, consider signing up to become a Medium member. It’s $5 a month, with unlimited access to thousands of articles. If you sign up using my link, I’ll earn a small commission at no extra cost.
Creating Dynamic Pivots on Snowflake Tables with dbt was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/eHDsmOR
via IFTTT
