
Data Validation with Pandera in Python
Validating your Dataframes for Production ML Pipelines

Data validation is a crucial step for production applications. You need to ensure the data you are ingesting is compatible with your pipeline and that unexpected values aren’t present. Moreover, validating the data is a security measure that prevents any corrupted or inaccurate information from being further processed, raising a flag on the first steps.
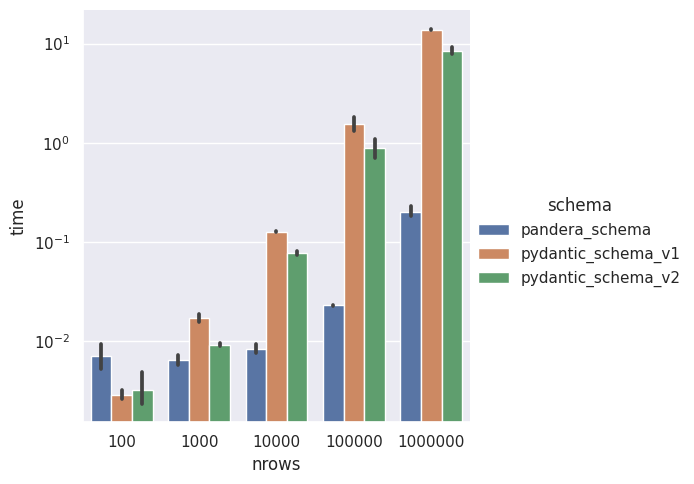
Python already counts with a great OS project for this task called Pydantic. However, when dealing with large dataframe-like objects such as in Machine Learning, Pandera is a much faster and scalable way of validating data (check this article with public notebooks).
In addition, Pandera offers support for a great variety of dataframe libraries like pandas, polars, dask, modin, and pyspark.pandas. For more information on these refer to Pandera’s docs📄.
Disclaimer. Pandera is an open-source project licensed under the MIT License. I have no affiliation with the Pandera team or Union.ai. This post has no commercial interest.
Validating data with Pandera
Pandera has two ways of defining validators: Schemas and Models. I will focus on the second one because of its similarity with Pydantic models and the cleanness of the code.
To define a Pandera model create a child class that inherits from DataframeModel and start declaring the columns and dtypes that the dataframe must have:
import pandera as pa
class UserModel(pa.DataFrameModel):
id: int
username: str
email: str
is_active: bool
membership: str
creation_date: pd.DatetimeTZDtype
# Use
df = pd.DataFrame(...)
UserModel.validate(df) # <- If invalidad raises SchemaError
Note that to define the user’s creation timestamp I used Pandas native date type instead of others like datetime.datetime. Pandera only supports built-in Python, NumPy, and Pandas data types. You can also create custom data types, but this is an advanced topic and rarely necessary in most cases.
Validating column properties
With Pandera, you can also validate other column properties in addition to the type of data:
class UserModel(pa.DataFrameModel):
id: int = pa.Field(unique=True, ge=0)
username: str = pa.Field(str_matches=r"^[a-zA-Z0-9_]+$")
email: str = pa.Field(str_matches=r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$")
is_active: bool
membership: str = pa.Field(isin=["premium", "free"])
creation_date: pd.DatetimeTZDtype = pa.Field(dtype_kwargs={"unit": "ns", "tz": "UTC"})
Here I am using pandera’s Field just like pydantics’.
- First, I am specifying that the id column must not contain duplicated values and these have to be greater or equal to 0.
- In username and email I’m checking using regex expressions if strings are valid. User names must only contain alphanumeric characters and underscore, while emails can also contain dashes and dots but always follow the pattern “smth@smth.smth”.
- membership can only take a value from the list. A better approach is using a StrEnum to define the valid values instead of hardcoding them.
- Finally, creation_date must be in nanosecond units and UTC timezone. This line can be cleaner using Annotated from typing library creation_date: Annotated[pd.DatetimeTZDtype, "ns", "UTC"]
Check out the docs to read all Field options😋
Custom Validations
Sometimes it is necessary to add your own custom validations. Pandera allows you to inject column/index checks (custom checks of single columns) and dataframe checks (checks between several columns).
import pandera as pa
from pandera.typing import Series
class UserModel(pa.DataFrameModel):
id: int = pa.Field(unique=True, ge=0)
username: str = pa.Field(str_matches=r"^[a-zA-Z0-9_]+$")
email: str = pa.Field(
str_matches=r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$"
)
is_active: bool
membership: str = pa.Field(isin=["premium", "free"])
creation_date: Annotated[pd.DatetimeTZDtype, "ns", "UTC"]
# column/index checks
@pa.check("username", name="username_length")
def username_length(cls, x: Series[str]) -> Series[bool]:
"""
Check username length is between 1 and 20 characters
"""
return x.str.len().between(1, 20)
@pa.check("creation_date", name="min_creation_date")
def min_creation_date(cls, x: Series[pd.DatetimeTZDtype]) -> Series[bool]:
"""
Check creation date is after 2000-01-01
"""
return x >= dt.datetime(2000, 1, 1, tzinfo=dt.timezone.utc)
# dataframe check
@pa.dataframe_check
def membership_is_valid(
cls, df: pd.DataFrame, name="membership_is_valid"
) -> Series[bool]:
"""
Check account age for free memebers is <= 30 days
"""
current_time = dt.datetime.now(dt.timezone.utc)
thirty_days = dt.timedelta(days=30)
return (df["membership"] == "premium") | (
(df["membership"] == "free")
& ((current_time - df["creation_date"]) <= thirty_days)
)
Keep in mind that you are working with entire column objects (Series) so that operations in checks should be vectorized for better performance.
Other Configurations
Aliases
When column names can’t be declared as Python variables due to the language syntax, Pandera allows setting an alias for the column validator to match the dataframe.
class MyModel(pa.DataFrameModel):
alias_column: int = pa.Field(..., alias="Alias Column")
...
Strict and Coerce
When the strict option is set to true, it forces the validated dataframe to only contain the columns defined in the Pandera DataFrameModel. On the other hand, when the coerce option is activated, Pandera will try to cast the column data to match the model’s dtype.
class MyModel(pa.DataFrameModel):
...
class Config:
strict = True # defaul: False
coerce = True # default: False
The coerce option can be set at the Field level too using pa.Field(..., coerce=True)
Lazy validation
By default, pandera raises an error whenever a validation check isn’t passed. This can be annoying because it only displays the first validation error encountered, and prevents the rest of the data from being checked.
In some cases, it is better to let the whole dataframe validate and collect all errors in one run, rather than fixing them one by one and waiting for the validation to run again. The first is what lazy validation does.
df = pd.DataFrame(...)
Mymodel.validate(df, lazy_validation=True)
An ML Production Pipeline with Data Validation

Because the majority of ML Pipelines are trained in Python with tabular data encoded into dataframe structures, Pandera is a great and powerful tool to validate their Inputs and Outputs.
# pipeline.py
class MLPipeline:
"""General ML Pipeline"""
def __init__(self, model_id: str):
self.model_id = model_id
def load_model(self) -> None:
...
def transform_data(self, df: pd.DataFrame) -> pd.DataFrame:
... # <- Potential invalid data error
return df_transform
def predict(self, df: pd.DataFrame) -> pd.DataFrame:
self.load_model()
df_transform = self.transform(df)
df['score'] = self.model.predict(df_transform) # <- Potential invalid data error
return df
We want to avoid the model raising an error due to invalid data. That would mean that we’ve done all the work of loading the model into memory and processing the raw data for nothing, wasting resources and preventing the rest of the data points from being evaluated.
Similarly, if the model’s output has an incorrect structure our postprocessing pipeline (uploading results to DB, returning results by RESTful API, etc.) will fail.
After defining the validation models using Pandera, we can leverage its decorators for pipeline integration to perform I/O validation.
# models.py
import pandera as pa
class InputModel(pa.DataFrameModel):
...
class PredictorModel(pa.DataFrameModel):
...
# OutputModel inherits all InputModel validation fields
# and also includes the score
class OutputModel(InputModel):
score: float = pa.Field(ge=0, le=1) # assuming model returns probab.
# pipeline.py
import pandera as pa
from .models import InputModel, PredictorModel, OutputModel
class MLPipeline:
"""General ML Pipeline"""
def __init__(self, model_id: str):
self.model_id = model_id
def load_model(self) -> None:
...
@pa.check_io(df=InputModel.to_schema(), out=PredictorModel.to_schema(), lazy=True)
def transform_data(self, df: pd.DataFrame) -> pd.DataFrame:
...
return df_transform
@pa.check_output(OutputModel.to_schema(), lazy=True)
def predict(self, df: pd.DataFrame) -> pd.DataFrame:
self.load_model()
df_transform = self.transform(df)
df['score'] = self.model.predict(df_transform)
return df
Because we are generating an intermediate dataframe object df_transform in the ML Pipeline, it is a good practice to validate it too to prevent errors. The predict method input is not validated as it is already done by transform_data.
Handling invalid rows
We don’t want our pipeline to break just because some data points have incorrect data. In case of a validation error, the strategy should be to set aside the problematic data points and continue running the pipeline with the rest of the data. The pipeline cannot stop!🔥
Pandera models have the option to automatically remove all invalid rows:
class MyModel(pa.DataFrameModel):
...
class Config:
drop_invalid_rows = True
However, dropping all invalid rows without logging them can be dangerous. You need to know why those data points were invalid so that later you can communicate to the client or to the data engineer what was the cause of the error.
That is why instead of using pandera decorators I rather create my own validation helper functions:
from typing import Tuple
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def log_pandera_errors(exc: pa.errors.SchemaErrors) -> None:
"""
Logs all errors from a SchemaErrors exception.
"""
for err_type, categories in exc.message.items():
for _, errors in categories.items():
for err in errors:
logger.error(f"{err_type} ERROR: {err['column']}. {err['error']}")
def handle_invalid(
df: pd.DataFrame, exc: pa.errors.SchemaErrors
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
Handles invalid data in a DataFrame based on a SchemaErrors exception.
"""
log_pandera_errors(exc)
df_failure = exc.failure_cases
# Check for errors that cannot be resolved
# i.e. they aren't associated with a specific row index
nan_indices = df_failure["index"].isna()
if nan_indices.any():
error_msg = "\n".join(
f" - Column: {row['column']}, check: {row['check']}, "
f"failure_case: {row['failure_case']}"
for row in df_failure[nan_indices].to_dict("records")
)
raise ValueError(
f"Schema validation failed with no possibility of continuing:\n{error_msg}\n"
"The pipeline cannot continue 😢. Resolve before rerunning"
)
invalid_idcs = df.index.isin(df_failure["index"].unique())
df_invalid = format_invalid_df(df.loc[invalid_idcs, :], exc)
df_valid = df.iloc[~invalid_idcs]
return df_valid, df_invalid
def validate(
df: pd.DataFrame, model: pa.DataFrameModel
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
Validates a DataFrame against a DataFrameModel and handles errors.
"""
try:
return model.validate(df, lazy=True), pd.DataFrame()
except pa.errors.SchemaErrors as ex:
return handle_invalid(df, ex)
Output forcing some errors and removing column id:
# Error output
ERROR:__main__:SCHEMA ERROR: UserModel. column 'id' not in dataframe. Columns in dataframe: ['username', 'email', 'membership', 'is_active', 'creation_date']
ERROR:__main__:DATA ERROR: username. Column 'username' failed element-wise validator number 0: str_matches('^[a-zA-Z0-9_]+$') failure cases: b%09
ERROR:__main__:DATA ERROR: email. Column 'email' failed element-wise validator number 0: str_matches('^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$') failure cases: ef.com
ERROR:__main__:DATA ERROR: UserModel. DataFrameSchema 'UserModel' failed element-wise validator number 0: <Check membership_is_valid> failure cases: c, ef.com, free, True, 2000-12-31 00:00:00+00:00
ValueError: Schema validation failed with no possibility of continuing:
- Column: UserModel, check: column_in_dataframe, failure_case: id
The pipeline cannot continue 😢. Resolve before rerunning
In case of an unresolvable error that involves an entire column, the pipeline cannot continue.
Testing
Last but not least, Pandera models and schemas also incorporate a method for generating sample data according to their definition. You will need to install hypothesis library to use it.
However, after testing it with some examples I do not recommend it. As soon as you start adding a few constraints, it takes too long to generate the synthetic data and most of the time it isn’t varied (the generated data do not cover the entire restriction space and repeats itself) The best alternative I found is to add data generators for each model you want to test — after all, there aren’t so many data frames to validate in a pipeline either — .
class UserModel(pa.DataFrameModel):
...
def sample(size: int = 10) -> pd.DataFrame:
"""Added method to generate valid test data manually"""
current_time = dt.datetime.now(dt.timezone.utc)
return pd.DataFrame(
{
"id": range(size),
"username": [f"user_{i}" for i in range(size)],
"email": [f"user_{i}@example.com" for i in range(size)],
"is_active": [True] * size,
"membership": ["premium"] * size, # All premium to pass checks
"creation_date": [current_time] * size,
}
)
Conclusion
Data validation is vital for every data processing pipeline and especially in Machine Learning. Pandera simplifies a lot of this work by providing a flexible, and efficient model-based approach to validating data in dataframes.
With Pandera, you can define model classes that enforce column types, ranges, and even complex conditional constraints. This makes it easy to catch data quality issues early in the pipeline, ensuring that the data conforms to expected standards before it reaches the next steps.
By integrating Pandera into an ML pipeline, you can create robust data checks that help prevent errors and improve the reliability of model outputs.
Final pandera.DataFrameModel used in the tests:
import pandas as pd
import pandera as pa
from pandera.typing import Series
from typing import Annotated
import datetime as dt
class UserModel(pa.DataFrameModel):
id: int = pa.Field(unique=True, ge=0, coerce=False)
username: str = pa.Field(str_matches=r"^[a-zA-Z0-9_]+$")
email: str = pa.Field(
str_matches=r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$"
)
is_active: bool
membership: str = pa.Field(isin=["premium", "free"])
creation_date: Annotated[pd.DatetimeTZDtype, "ns", "UTC"]
@pa.check("username", name="username_length")
def username_length(cls, x: Series[str]) -> Series[bool]:
"""
Check username length is between 1 and 20 characters
"""
return x.str.len().between(1, 20)
@pa.check("creation_date", name="min_creation_date")
def min_creation_date(cls, x: Series[pd.DatetimeTZDtype]) -> Series[bool]:
"""
Check creation date is after 2000-01-01
"""
return x >= dt.datetime(2000, 1, 1, tzinfo=dt.timezone.utc)
@pa.dataframe_check
def membership_is_valid(
cls, df: pd.DataFrame, name="membership_is_valid"
) -> Series[bool]:
"""
Check account age for free memebers is <= 30 days
"""
current_time = dt.datetime.now(dt.timezone.utc)
thirty_days = dt.timedelta(days=30)
return (df["membership"] == "premium") | (
(df["membership"] == "free")
& ((current_time - df["creation_date"]) <= thirty_days)
)
class Config:
strict = True
coerce = True
def sample(size: int = 10) -> pd.DataFrame:
"""Added method to generate valid test data manually"""
current_time = dt.datetime.now(dt.timezone.utc)
return pd.DataFrame(
{
"id": range(size),
"username": [f"user_{i}" for i in range(size)],
"email": [f"user_{i}@example.com" for i in range(size)],
"is_active": [True] * size,
"membership": ["premium"]
* size, # All premium to avoid date restrictions
"creation_date": [current_time] * size,
}
)
Hi, I’m Gabriel Furnieles, a Mathematical Engineer specializing in Artificial Intelligence, Data Pipelines, and MLOps. I hope you enjoyed the article and found it helpful, if so, please consider following me Gabriel Furnieles, and subscribing to my newsletter so stories will be sent directly to you 👇
Data Validation with Pandera in Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/1rzmvJq
via IFTTT


