
How Can Self-Driving Cars Work Better?
The far-reaching implications of Waymo’s EMMA and other end-to-end driving systems

Imagine you are a hungry hiker, lost on a trail away from the city. After walking many miles, you find a road and spot a faint outline of a car coming towards you. You mentally prepare a sympathy pitch for the driver, but your hope turns to horror as you realize the car is driving itself. There is no human to showcase your trustworthiness, or seek sympathy from.
Deciding against jumping in front of the car, you try thumbing a ride, but the car’s software clocks you as a weird pedestrian and it whooses past you.
Sometimes having an emergency call button or a live helpline [to satisfy California law requirements] is not enough. Some edge cases require intervention, and they will happen more often as autonomous cars take up more of our roads. Edge cases like these are especially tricky, because they need to be taken on a case by case basis. Solving them isn’t as easy as coding a distressed face classifier, unless you want people posing distressed faces to get free rides. Maybe the cars can make use of human support, ‘tele-guidance’ as Zoox calls it, to vet genuine cases while also ensuring the system is not taken advantage of, a realistically boring solution that would work… for now. An interesting development in autonomous car research holds the key to a more sophisticated solution.
Typically an autonomous driving algorithm works by breaking down driving into modular components and getting good at them. This breakdown looks different in different companies but a popular one that Waymo and Zoox use, has modules for mapping, perception, prediction, and planning.
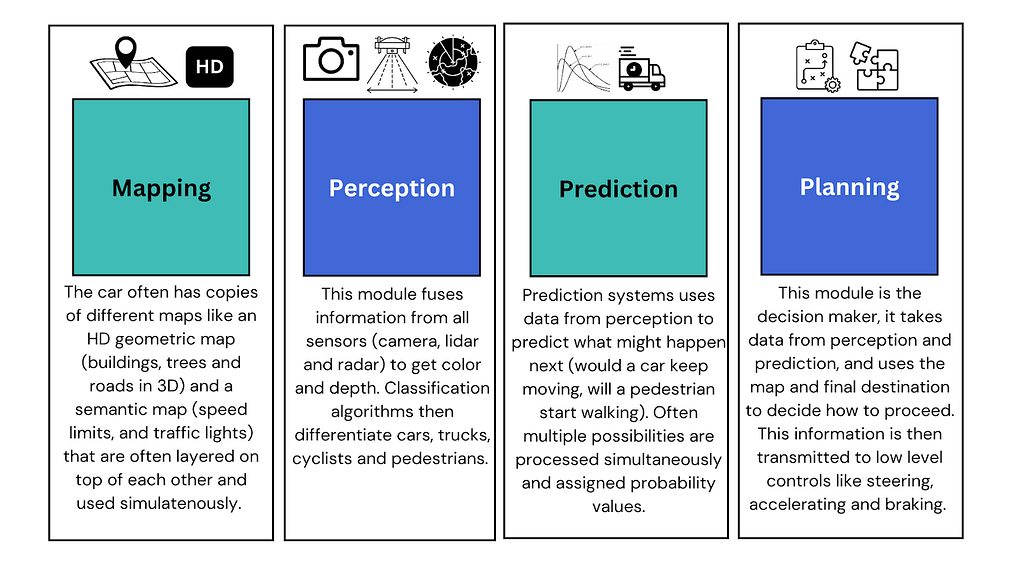
Each of these modules only focus on the one function which they are heavily trained on, this makes them easier to debug and optimize. Interfaces are then engineered on top of these modules to connect them and make them work together.
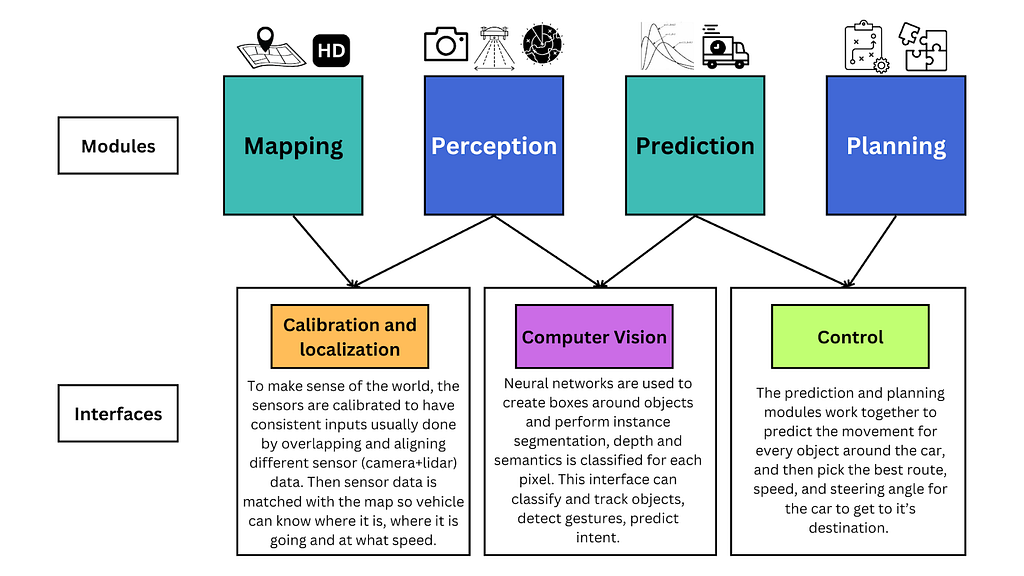
After connecting these modules using the interfaces, the pipeline is then further trained on simulations and tested in the real world.
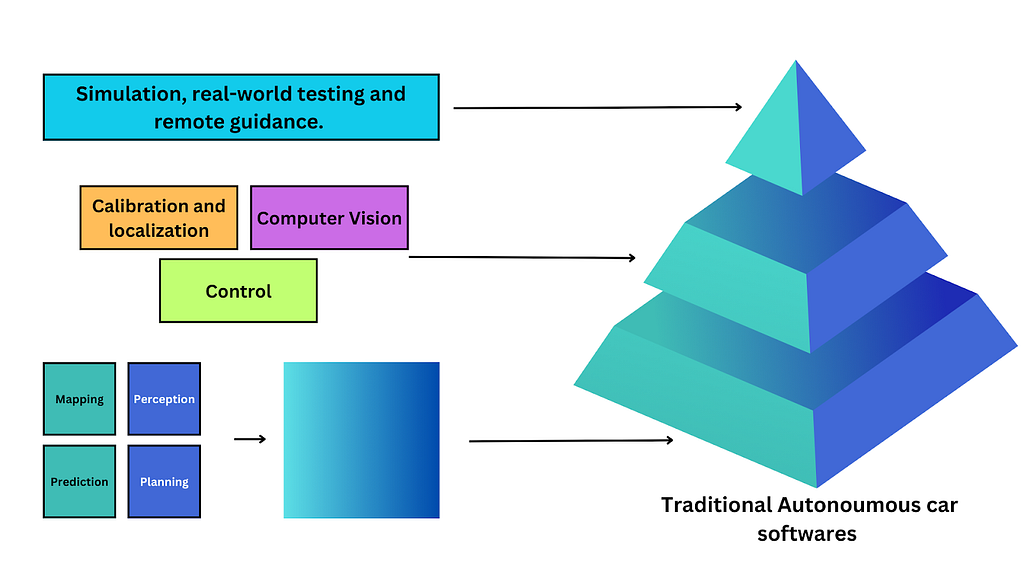
This approach works well, but it is inefficient. Since each module is trained separately, the interfaces often struggle to make them work well together. This means the cars adapt badly to novel environments. Often cumulative errors build up among modules, made worse by inflexible pre-set rules. The answer might seem to just train them on less likely scenarios, which seems plausible intuitively but is actually quite implausible. This is because driving scenarios fall under a long tailed distribution.
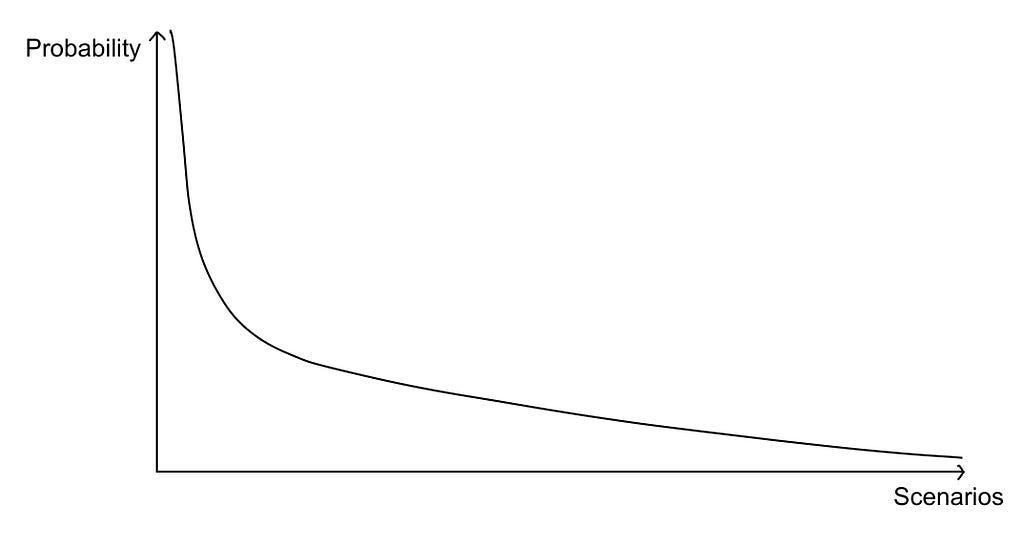
This means we have the most likely scenarios that are easily trained, but there are so many unlikely scenarios that trying to train our model on them is exceptionally computationally expensive and time consuming only to get marginal returns. Scenarios like an eagle nose diving from the sky, a sudden sinkhole formation, a utility pole collapsing, or driving behind a car with a blown brake light fuse. With a car only trained on highly relevant data, with no worldly knowledge, which struggles to adapt to novel solutions, this means an endless catch-up game to account for all these implausible scenarios, or worse, being forced to add more training scenarios when something goes very wrong.
Two weeks ago, Waymo Research published a paper on EMMA, an end-to-end multimodal model which can turn the problem on its head. This end-to-end model instead of having modular components, would include an all knowing LLM with all its worldly knowledge at the core of the model, this LLM would then be further fine-tuned to drive. For example Waymo’s EMMA is built on top of Google’s Gemini while DriveGPT is built on top of OpenAI’s ChatGPT.
This core is then trained using elaborate prompts to provide context and ask questions to deduce its spatial reasoning, road graph estimation, and scene understanding capabilities. The LLMs are also asked to offer decoded visualizations, to analyze whether the textual explanation matches up with how the LLM would act in a simulation. This multimodal infusion with language input makes the training process much more simplified as you can have simultaneous training of multiple tasks with a single model, allowing for task-specific predictions through simple variations of the task prompt.
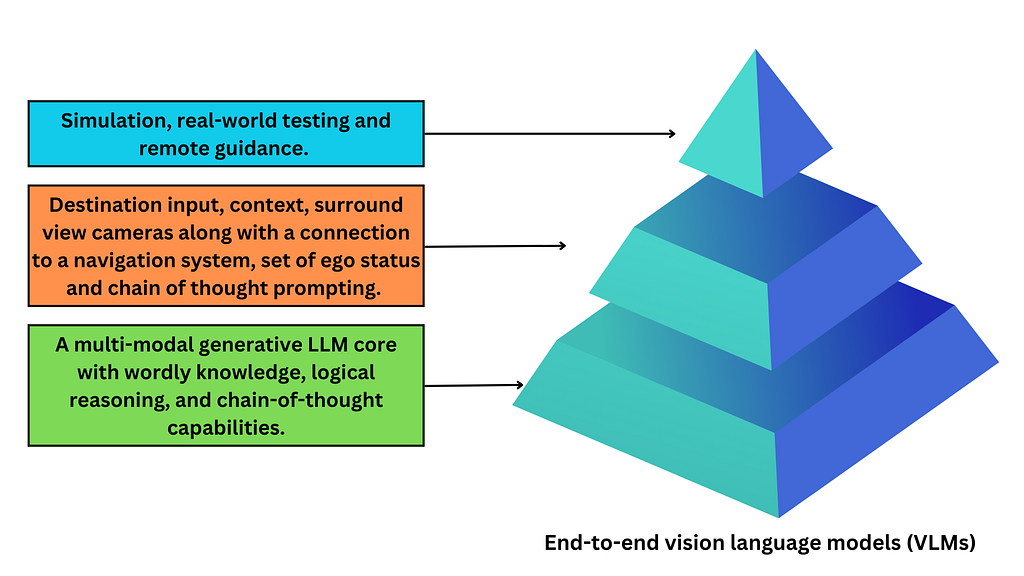
Another interesting input is often an ego variable, which has nothing to do with how superior the car feels but rather stores data like the car’s location, velocity, acceleration and orientation to help the car plan out a route for smooth and consistent driving. This improves performance through smoother behavior transitions and consistent interactions with surrounding agents in multiple consecutive steps.
These end-to-end models, when tested through simulations, give us a state-of-the-art performance on public benchmarks. How does GPT knowing how to file a 1040 help it drive better? Worldly knowledge and logical reasoning capabilities means better performance in novel situations. This model also lets us co-train on tasks, which outperforms single task models by more than 5.5%, an improvement despite much less input (no HD map, no interfaces, and no access to lidar or radar). They are also much better at understanding hand gestures, turn signals, or spoken commands from other drivers and are socially adept at evaluating driving behaviors and aggressiveness of surrounding cars and adjust their predictions accordingly. You can also ask them to justify their decisions which gets us around their “black box” nature, making validation and traceability of decisions much easier.
In addition to all this, LLMs can also help with creating simulations that they can then be tested on, since they can label images and can receive text input to create images. This can significantly simplify constructing an easily controllable setting for testing and validating the decision boundaries of autonomous driving systems and simulating a variety of driving situations.
This approach is still slower, can input limited image frames and is more computationally extensive but as our LLMs get better, faster, less computationally expensive and incorporate additional modalities like lidar and radar, we will see this multimodal approach surpass specialized expert models in 3D object detection quality exponentially, but that might be a few years down the road.
As end-to-end autonomous cars drive for longer it would be interesting to see how they imprint on the human drivers around them, and develop a unique ‘auto-temperament’ or personality in each city. It would be a fascinating case study of driving behaviours around the world. It would be even more fascinating to see how they impact the human drivers around them.
An end-to-end system would also mean being able to have a conversation with the car, like you converse with ChatGPT, or being able to walk up to a car on the street and ask it for directions. It also means hearing less stories from my friends, who vow to never sit in a Waymo again after it almost ran into a speeding ambulance or failed to stop for a low flying bird.
Imagine an autonomous car not just knowing where it is at what time of day (on a desolate highway close to midnight) but also understanding what that means (the pedestrian is out of place and likely in trouble). Imagine a car not just being able to call for help (because California law demands it) but actually being the help because it can logically reason with ethics. Now that would be a car that would be worth the ride.
References:
Chen, L., Sinavski, O., Hünermann, J., Karnsund, A., Willmott, A. J., Birch, D., Maund, D., & Shotton, J. (2023). Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving (arXiv:2310.01957). arXiv. https://doi.org/10.48550/arXiv.2310.01957
Cui, C., Ma, Y., Cao, X., Ye, W., Zhou, Y., Liang, K., Chen, J., Lu, J., Yang, Z., Liao, K.-D., Gao, T., Li, E., Tang, K., Cao, Z., Zhou, T., Liu, A., Yan, X., Mei, S., Cao, J., … Zheng, C. (2024). A Survey on Multimodal Large Language Models for Autonomous Driving. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), 958–979. https://doi.org/10.1109/WACVW60836.2024.00106
Fu, D., Lei, W., Wen, L., Cai, P., Mao, S., Dou, M., Shi, B., & Qiao, Y. (2024). LimSim++: A Closed-Loop Platform for Deploying Multimodal LLMs in Autonomous Driving (arXiv:2402.01246). arXiv. https://doi.org/10.48550/arXiv.2402.01246
Hwang, J.-J., Xu, R., Lin, H., Hung, W.-C., Ji, J., Choi, K., Huang, D., He, T., Covington, P., Sapp, B., Zhou, Y., Guo, J., Anguelov, D., & Tan, M. (2024). EMMA: End-to-End Multimodal Model for Autonomous Driving (arXiv:2410.23262). arXiv. https://doi.org/10.48550/arXiv.2410.23262
The ‘full-stack’: Behind autonomous driving. (n.d.). Zoox. Retrieved November 26, 2024, from https://zoox.com/autonomy
Wang, B., Duan, H., Feng, Y., Chen, X., Fu, Y., Mo, Z., & Di, X. (2024). Can LLMs Understand Social Norms in Autonomous Driving Games? (arXiv:2408.12680). arXiv. https://doi.org/10.48550/arXiv.2408.12680
Wang, Y., Jiao, R., Zhan, S. S., Lang, C., Huang, C., Wang, Z., Yang, Z., & Zhu, Q. (2024). Empowering Autonomous Driving with Large Language Models: A Safety Perspective (arXiv:2312.00812). arXiv. https://doi.org/10.48550/arXiv.2312.00812
Xu, Z., Zhang, Y., Xie, E., Zhao, Z., Guo, Y., Wong, K.-Y. K., Li, Z., & Zhao, H. (2024). DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model (arXiv:2310.01412). arXiv. https://doi.org/10.48550/arXiv.2310.01412
Yang, Z., Jia, X., Li, H., & Yan, J. (n.d.). LLM4Drive: A Survey of Large Language Models for Autonomous Driving.
How Can Self-Driving Cars Work Better? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/AsZwxg0
via IFTTT


