
Multimodal AI Search for Business Applications
Enabling businesses to extract real value from their data
Business documents, such as complex reports, product catalogs, design files, financial statements, technical manuals, and market analysis reports, usually contain multimodal data (text as well as visual content such as graphs, charts, maps, photos, infographics, diagrams, and blueprints, etc.). Finding the right information from these documents requires a semantic search of text and related images for a given query posed by a customer or a company employee. For instance, a company’s product might be described through its title, textual description, and images. Similarly, a project proposal might include a combination of text, charts illustrating budget allocations, maps showing geographical coverage, and photos of past projects.
Accurate and quick search of multimodal information is important for improving business productivity. Business data is often spread across various sources in text and image formats, making retrieving all relevant information efficiently challenging. While generative AI methods, particularly those leveraging LLMs, enhance knowledge management in business (e.g., retrieval augment generation, graph RAGs, among others), they face limitations in accessing multimodal, scattered data. Methods that unify different data types allow users to query diverse formats with natural language prompts. This capability can benefit employees and management within a company and improve customer experience. It can have several use cases, such as clustering similar topics and discovering thematic trends, building recommendation engines, engaging customers with more relevant content, faster access to information for improved decision-making, delivering user-specific search results, enhancing user interactions to feel more intuitive and natural, and reducing time spent finding information, to name a few.
In modern AI models, data is processed as numerical vectors known as embeddings. Specialized AI models, called embedding models, transform data into numerical representations that can be used to capture and compare similarities in meaning or features efficiently. Embeddings are extremely useful for semantic search and knowledge mapping and serve as the foundational backbone of today’s sophisticated LLMs.
This article explores the potential of embedding models (particularly multimodal embedding models introduced later) for enhancing semantic search across multiple data types in business applications. The article begins by explaining the concept of embeddings for readers unfamiliar with how embeddings work in AI. It then discusses the concept of multimodal embeddings, explaining how the data from multiple data formats can be combined into unified embeddings that capture cross-modal relationships and could be immensely useful for business-related information search tasks. Finally, the article explores a recently introduced multimodal embedding model for multimodal semantic search for business applications.
Understanding Embedding Space & Semantic Search
Embeddings are stored in a vector space where similar concepts are located close to each other. Imagine the embedding space as a library where books on related topics are shelved together. For example, in an embedding space, embeddings for words like “desk” and “chair” would be near to each other, while “airplane” and “baseball” would be further apart. This spatial arrangement enables models to identify and retrieve related items effectively and enhances several tasks like recommendation, search, and clustering.
To demonstrate how embeddings are computed and visualized, let’s create some categories of different concepts. The complete code is available on GitHub.
categories = {
"Fruits": ["Apple", "Banana", "Orange", "Grape", "Mango", "Peach", "Pineapple"],
"Animals": ["Dog", "Cat", "Elephant", "Tiger", "Lion", "Monkey", "Rabbit"],
"Countries": ["Canada", "France", "India", "Japan", "Brazil", "Germany", "Australia"],
"Sports": ["Soccer", "Basketball", "Tennis", "Baseball", "Cricket", "Swimming", "Running"],
"Music Genres": ["Rock", "Jazz", "Classical", "Hip Hop", "Pop", "Blues"],
"Professions": ["Doctor", "Engineer", "Teacher", "Artist", "Chef", "Lawyer", "Pilot"],
"Vehicles": ["Car", "Bicycle", "Motorcycle", "Airplane", "Train", "Boat", "Bus"],
"Furniture": ["Chair", "Table", "Sofa", "Bed", "Desk", "Bookshelf", "Cabinet"],
"Emotions": ["Happiness", "Sadness", "Anger", "Fear", "Surprise", "Disgust", "Calm"],
"Weather": ["Hurricane", "Tornado", "Blizzard", "Heatwave", "Thunderstorm", "Fog"],
"Cooking": ["Grilling", "Boiling", "Frying", "Baking", "Steaming", "Roasting", "Poaching"]
}
I will now use an embedding model (Cohere’s embed-english-v3.0 model which is the focus of this article and will be discussed in detail after this example) to compute the embeddings of these concepts, as shown in the following code snippet. The following libraries need to be installed for running this code.
!pip install cohere umap-learn seaborn matplotlib numpy pandas regex altair scikit-learn ipython faiss-cpu
This code computes the text embeddings of the above-mentioned concepts and stores them in a NumPy array.
import cohere
import umap
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Initialize Cohere client
co = cohere.Client(api_key=os.getenv("COHERE_API_KEY_2"))
# Flatten categories and concepts
labels = []
concepts = []
for category, items in categories.items():
labels.extend([category] * len(items))
concepts.extend(items)
# Generate text embeddings for all concepts with corrected input_type
embeddings = co.embed(
texts=concepts,
model="embed-english-v3.0",
input_type="search_document" # Corrected input type for text
).embeddings
# Convert to NumPy array
embeddings = np.array(embeddings)
Embeddings can have hundreds or thousands of dimensions that are not possible to visualize directly. Hence, we reduce the dimensionality of embeddings to make high-dimensional data visually interpretable. After computing the embeddings, the following code maps the embeddings to a 2-dimensional space using the UMAP (Uniform Manifold Approximation and Projection) dimensionality reduction method so that we can plot and analyze how similar concepts cluster together.
# Dimensionality reduction using UMAP
reducer = umap.UMAP(n_neighbors=20, random_state=42)
reduced_embeddings = reducer.fit_transform(embeddings)
# Create DataFrame for visualization
df = pd.DataFrame({
"x": reduced_embeddings[:, 0],
"y": reduced_embeddings[:, 1],
"Category": labels,
"Concept": concepts
})
# Plot using Seaborn
plt.figure(figsize=(12, 8))
sns.scatterplot(data=df, x="x", y="y", hue="Category", style="Category", palette="Set2", s=100)
# Add labels to each point
for i in range(df.shape[0]):
plt.text(df["x"][i] + 0.02, df["y"][i] + 0.02, df["Concept"][i], fontsize=9)
plt.legend(loc="lower right")
plt.title("Visualization of Embeddings by Category")
plt.xlabel("UMAP Dimension 1")
plt.ylabel("UMAP Dimension 2")
plt.savefig("C:/Users/h02317/Downloads/embeddings.png",dpi=600)
plt.show()
Here is the visualization of the embeddings of these concepts in a 2D space.
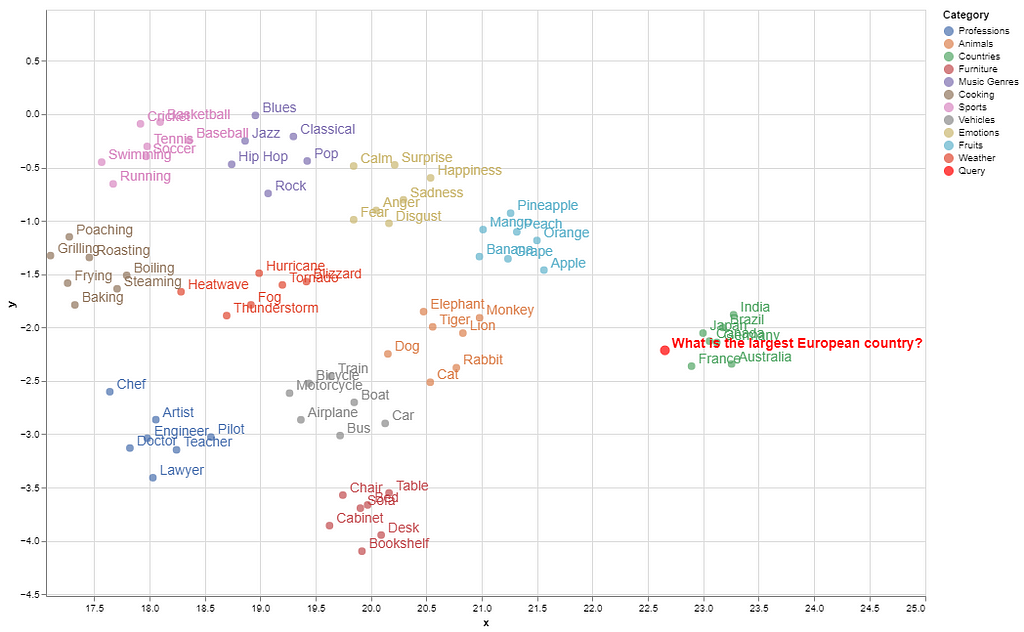
Semantically similar items are grouped in the embedding space, while concepts with distant meanings are located farther apart (e.g., countries are clustered farther from other categories).
To illustrate how a search query maps to its matching concept within this space, we first store the embeddings in a vector database (FAISS vector store). Next, we compute the query’s embeddings in the same way and identify a “neighborhood” in the embedding space where embeddings closely match the query’s semantics. This proximity is calculated using Euclidean distance or cosine similarity between the query embeddings and those stored in the vector database.
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
import warnings
from IPython.display import display, Markdown
import faiss
import numpy as np
import pandas as pd
from sklearn.preprocessing import normalize
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
# Normalize embeddings (optional but recommended for cosine similarity)
embeddings = normalize(np.array(embeddings))
# Create FAISS index
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension) # L2 distance, can use IndexFlatIP for inner product (cosine similarity)
index.add(embeddings) # Add embeddings to the FAISS index
# Embed the query
query = "Which is the largest European country?"
query_embedding = co.embed(texts=[query], model="embed-english-v3.0", input_type="search_document").embeddings[0]
query_embedding = normalize(np.array([query_embedding])) # Normalize query embedding
# Search for nearest neighbors
k = 5 # Number of nearest neighbors
distances, indices = index.search(query_embedding, k)
# Format and display results
results = pd.DataFrame({
'texts': [concepts[i] for i in indices[0]],
'distance': distances[0]
})
display(Markdown(f"Query: {query}"))
# Convert DataFrame to markdown format
def print_markdown_results(df):
markdown_text = f"Nearest neighbors:\n\n"
markdown_text += "| Texts | Distance |\n"
markdown_text += "|-------|----------|\n"
for _, row in df.iterrows():
markdown_text += f"| {row['texts']} | {row['distance']:.4f} |\n"
display(Markdown(markdown_text))
# Display results in markdown
print_markdown_results(results)
Here are the top-5 closest matches to the query, ranked by their smallest distances from the query’s embedding among the stored concepts.

As shown, France is the correct match for this query among the given concepts. In the visualized embedding space, the query’s position falls within the ‘country’ group.
The whole process of semantic search is depicted in the following figure.
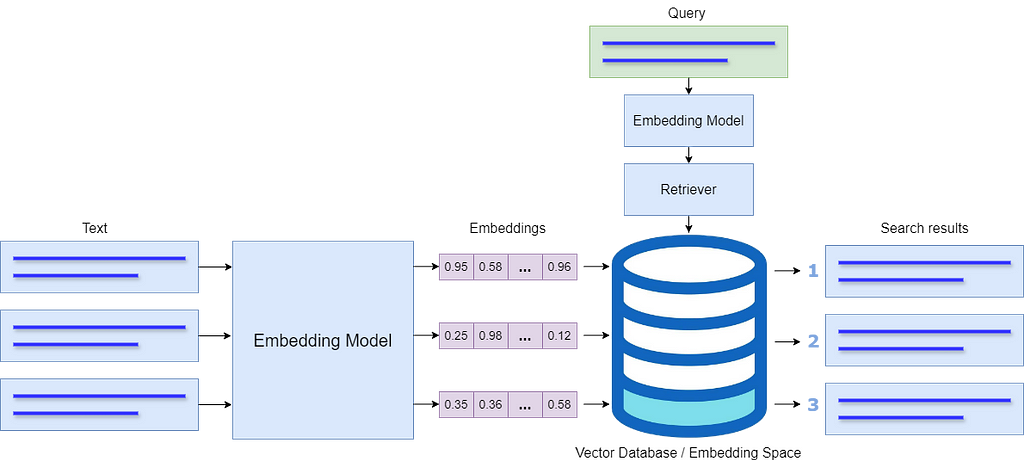
Multimodal Embeddings
Text embeddings are successfully used for semantic search and retrieval augment generation (RAG). Several embedding models are used for this purpose, such as from OpenAI’s, Google, Cohere, and others. Similarly, several open-source models are available on the Hugging Face platform such as all-MiniLM-L6-v2. While these models are very useful for text-to-text semantic search, they cannot deal with image data which is an important source of information in business documents. Moreover, businesses often need to quickly search for relevant images either from documents or from vast image repositories without proper metadata.
This problem is partially addressed by some multimodal embedding models, such as OpenAI’s CLIP, which connects text and images and can be used to recognize a wide variety of visual concepts in images and associate them with their names. However, it has very limited text input capacity and shows low performance for text-only or even text-to-image retrieval tasks.
A combination of text and image embedding models is also used to cluster text and image data into separate spaces; however, it leads to weak search results that are biased toward text-only data. In multimodal RAGs, a combination of a text embedding model and a multimodal LLM is used to answer both from text and images. For the details of developing a multimodal RAG, please read my following article.
Integrating Multimodal Data into a Large Language Model
A multimodal embedding model should be able to include both image and text data within a single database which will reduce complexity compared to maintaining two separate databases. In this way, the model will prioritize the meaning behind data, instead of biasing towards a specific modality.
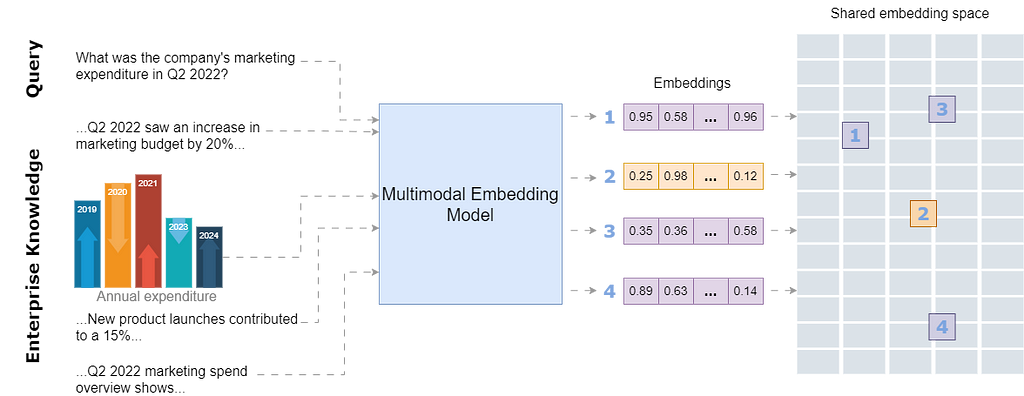
By storing all modalities in a single embedding space, the model will be able to connect text with relevant images and retrieve and compare information across different formats. This unified approach enhances search relevance and allows for a more intuitive exploration of interconnected information within the shared embedding space.
Exploring a Multimodal Embedding Model for a Business Use-Case
Cohere recently introduced a multimodal embedding model, Embed 3, which can generate embeddings from both text and images and store them in a unified embedding space. According to Cohere’s blog, the model shows impressive performance for a variety of multimodal tasks such as zero-shot, text-to-image, graphs and charts, eCommerce catalogs, and design files, among others.
In this article, I explore Cohere’s multimodal embedding model for text-to-image, text-to-text, and image-to-image retrieval tasks for a business scenario in which the customers search for products from an online product catalog using either text queries or images. Using text-to-image, text-to-text, and image-to-image retrieval in an online product catalog brings several advantages to businesses as well as customers. This approach allows customers to search for products in a flexible way, either by typing a query or uploading an image. For instance, a customer who sees an item they like can upload a photo, and the model will retrieve visually similar products from the catalog along with all the details about the product. Similarly, customers can search for specific products by describing their characteristics rather than using the exact product name.
The following steps are involved in this use case.
- Demonstrating how multimodal data (text and images) can be parsed from a product catalog using LlamaParse.
- Creating a multimodal index using Cohere’s multimodal model embed-english-v3.0.
- Creating a multimodal retriever and testing it for a given query.
- Creating a multimodal query engine with a prompt template to query the multimodal vector database for text-to-text and text-to-image tasks (combined)
- Retrieving relevant images and text from the vector database and sending it to an LLM to generate the final response.
- Testing for image-to-image retrieval tasks.
I generated an example furniture catalog of a fictitious company using OpenAI’s DALL-E image generator. The catalog comprises 4 categories of a total of 36 product images with descriptions. Here is the snapshot of the first page of the product catalog.

The complete code and the sample data are available on GitHub. Let’s discuss it step by step.
Cohere’s embedding model is used in the following way.
model_name = "embed-english-v3.0"
api_key = "COHERE_API_KEY"
input_type_embed = "search_document" #for image embeddings, input_type_embed = "image"
# Create a cohere client.
co = cohere.Client(api_key)
text = ['apple','chair','mango']
embeddings = co.embed(texts=list(text),
model=model_name,
input_type=input_type_embed).embeddings
The model can be tested using Cohere’s trial API keys by creating a free account on their website.
To demonstrate how multimodal data can be extracted, I used LlamaParse to extract product images and text from the catalog. This process is detailed in my previous article. LlamaParse can be used by creating an account on Llama Cloud website to get an API key. The free API key allows 1000 pages of credit limit per day.
The following libraries need to be installed to run the code in this article.
!pip install nest-asyncio python-dotenv llama-parse qdrant-client
The following piece of code loads the API keys of Llama Cloud, Cohere, and OpenAI from an environment file (.env). OpenAI’s multimodal LLM, GPT-4o, is used to generate the final response.
import os
import time
import nest_asyncio
from typing import List
from dotenv import load_dotenv
from llama_parse import LlamaParse
from llama_index.core.schema import ImageDocument, TextNode
from llama_index.embeddings.cohere import CohereEmbedding
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core import Settings
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
import qdrant_client
from llama_index.core import SimpleDirectoryReader
# Load environment variables
load_dotenv()
nest_asyncio.apply()
# Set API keys
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
LLAMA_CLOUD_API_KEY = os.getenv("LLAMA_CLOUD_API_KEY")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
The following code extracts the text and image nodes from the catalog using LlamaParse. The extracted text and images are saved to a specified path.
# Extract text nodes
def get_text_nodes(json_list: List[dict]) -> List[TextNode]:
return [TextNode(text=page["text"], metadata={"page": page["page"]}) for page in json_list]
# Extract image nodes
def get_image_nodes(json_objs: List[dict], download_path: str) -> List[ImageDocument]:
image_dicts = parser.get_images(json_objs, download_path=download_path)
return [ImageDocument(image_path=image_dict["path"]) for image_dict in image_dicts]
# Save the text in text nodes to a file
def save_texts_to_file(text_nodes, file_path):
texts = [node.text for node in text_nodes]
all_text = "\n\n".join(texts)
with open(file_path, "w", encoding="utf-8") as file:
file.write(all_text)
# Define file paths
FILE_NAME = "furniture.docx"
IMAGES_DOWNLOAD_PATH = "parsed_data"
# Initialize the LlamaParse parser
parser = LlamaParse(
api_key=LLAMA_CLOUD_API_KEY,
result_type="markdown",
)
# Parse document and extract JSON data
json_objs = parser.get_json_result(FILE_NAME)
json_list = json_objs[0]["pages"]
#get text nodes
text_nodes = get_text_nodes(json_list)
#extract the images to a specified path
image_documents = get_image_nodes(json_objs, IMAGES_DOWNLOAD_PATH)
# Save the extracted text to a .txt file
file_path = "parsed_data/extracted_texts.txt"
save_texts_to_file(text_nodes, file_path)
Here is the snapshot showing the extracted text and metadata of one of the nodes.
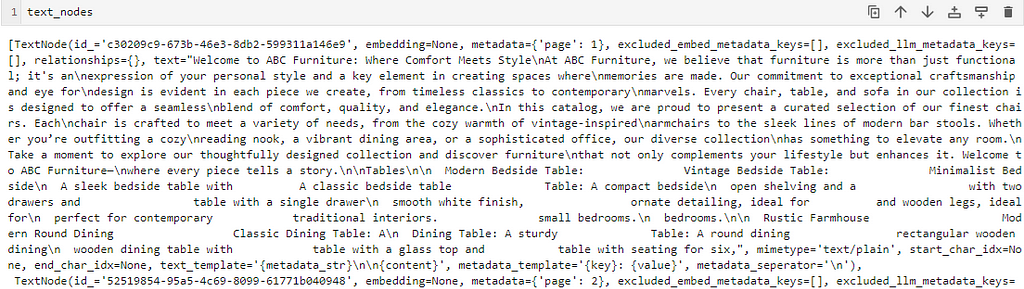
I saved the text data to a .txt file. Here is what the text in the .txt file looks like.

Here’s the structure of the parsed data within a folder

Note that the textual description has no connection with their respective images. The purpose is to demonstrate that the embedding model can retrieve the text as well as the relevant images in response to a query due to the shared embedding space in which the text and the relevant images are stored close to each other.
Cohere’s trial API allows a limited API rate (5 API calls per minute). To embed all the images in the catalog, I created the following custom class to send the extracted images to the embedding model with some delay (30 seconds, smaller delays can also be tested).
delay = 30
# Define custom embedding class with a fixed delay after each embedding
class DelayCohereEmbedding(CohereEmbedding):
def get_image_embedding_batch(self, img_file_paths, show_progress=False):
embeddings = []
for img_file_path in img_file_paths:
embedding = self.get_image_embedding(img_file_path)
embeddings.append(embedding)
print(f"sleeping for {delay} seconds")
time.sleep(tsec) # Add a fixed 12-second delay after each embedding
return embeddings
# Set the custom embedding model in the settings
Settings.embed_model = DelayCohereEmbedding(
api_key=COHERE_API_KEY,
model_name="embed-english-v3.0"
)
The following code loads the parsed documents from the directory and creates a multimodal Qdrant Vector database and an index (adopted from LlamaIndex implementation).
# Load documents from the directory
documents = SimpleDirectoryReader("parsed_data",
required_exts=[".jpg", ".png", ".txt"],
exclude_hidden=False).load_data()
# Set up Qdrant vector store
client = qdrant_client.QdrantClient(path="furniture_db")
text_store = QdrantVectorStore(client=client, collection_name="text_collection")
image_store = QdrantVectorStore(client=client, collection_name="image_collection")
storage_context = StorageContext.from_defaults(vector_store=text_store, image_store=image_store)
# Create the multimodal vector index
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
image_embed_model=Settings.embed_model,
)
Finally, a multimodal retriever is created to retrieve the matching text and image nodes from the multimodal vector database. The number of retrieved text nodes and images is defined by similarity_top_k and image_similarity_top_k.
retriever_engine = index.as_retriever(similarity_top_k=4, image_similarity_top_k=4)
Let’s test the retriever for the query “Find me a chair with metal stands”. A helper function display_images plots the retrieved images.
###test retriever
from llama_index.core.response.notebook_utils import display_source_node
from llama_index.core.schema import ImageNode
import matplotlib.pyplot as plt
from PIL import Image
def display_images(file_list, grid_rows=2, grid_cols=3, limit=9):
"""
Display images from a list of file paths in a grid.
Parameters:
- file_list: List of image file paths.
- grid_rows: Number of rows in the grid.
- grid_cols: Number of columns in the grid.
- limit: Maximum number of images to display.
"""
plt.figure(figsize=(16, 9))
count = 0
for idx, file_path in enumerate(file_list):
if os.path.isfile(file_path) and count < limit:
img = Image.open(file_path)
plt.subplot(grid_rows, grid_cols, count + 1)
plt.imshow(img)
plt.axis('off')
count += 1
plt.tight_layout()
plt.show()
query = "Find me a chair with metal stands"
retrieval_results = retriever_engine.retrieve(query)
retrieved_image = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
display_images(retrieved_image)
The text node and the images retrieved by the retriever are shown below.
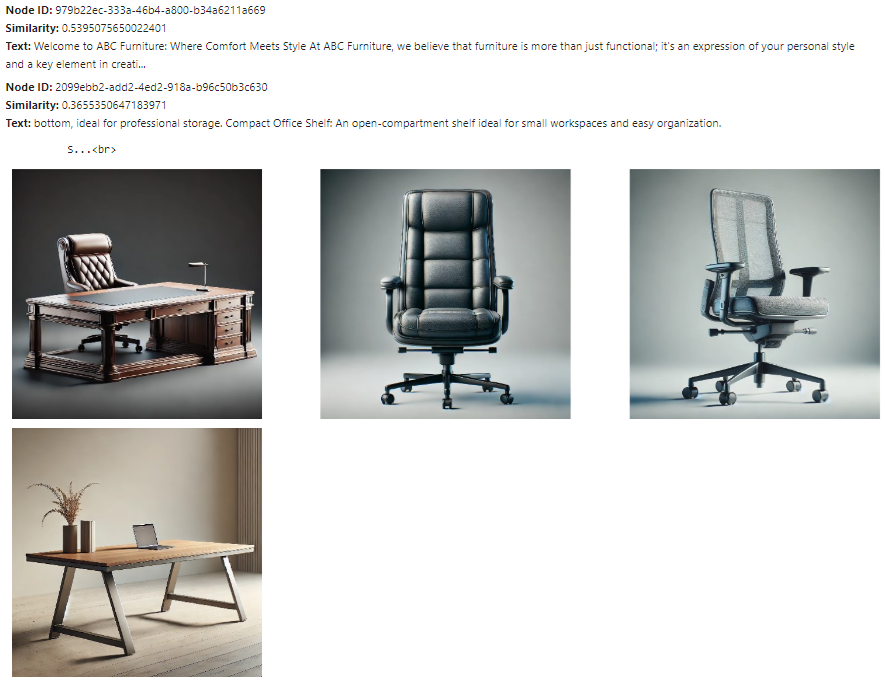
The text nodes and images retrieved here are close to the query embeddings, but not all may be relevant. The next step is to send these text nodes and images to a multimodal LLM to refine the selection and generate the final response. The prompt template qa_tmpl_str guides the LLM's behavior in this selection and response generation process.
import logging
from llama_index.core.schema import NodeWithScore, ImageNode, MetadataMode
# Define the template with explicit instructions
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Using the provided context and images (not prior knowledge), "
"answer the query. Include only the image paths of images that directly relate to the answer.\n"
"Your response should be formatted as follows:\n"
"Result: [Provide answer based on context]\n"
"Relevant Image Paths: array of image paths of relevant images only separated by comma\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
# Initialize multimodal LLM
multimodal_llm = OpenAIMultiModal(model="gpt-4o", temperature=0.0, max_tokens=1024)
# Setup the query engine with retriever and prompt template
query_engine = index.as_query_engine(
llm=multimodal_llm,
text_qa_template=qa_tmpl,
retreiver=retriever_engine
)
The following code creates the context string ctx_str for the prompt template qa_tmpl_str by preparing the image nodes with valid paths and metadata. It also embeds the query string with the prompt template. The prompt template, along with the embedded context, is then sent to the LLM to generate the final response.
# Extract the underlying nodes
nodes = [node.node for node in retrieval_results]
# Create ImageNode instances with valid paths and metadata
image_nodes = []
for n in nodes:
if "file_path" in n.metadata and n.metadata["file_path"].lower().endswith(('.png', '.jpg')):
# Add the ImageNode with only path and mimetype as expected by LLM
image_node = ImageNode(
image_path=n.metadata["file_path"],
image_mimetype="image/jpeg" if n.metadata["file_path"].lower().endswith('.jpg') else "image/png"
)
image_nodes.append(NodeWithScore(node=image_node))
logging.info(f"ImageNode created for path: {n.metadata['file_path']}")
logging.info(f"Total ImageNodes prepared for LLM: {len(image_nodes)}")
# Create the context string for the prompt
ctx_str = "\n\n".join(
[n.get_content(metadata_mode=MetadataMode.LLM).strip() for n in nodes]
)
# Format the prompt
fmt_prompt = qa_tmpl.format(context_str=ctx_str, query_str=query)
# Use the multimodal LLM to generate a response
llm_response = multimodal_llm.complete(
prompt=fmt_prompt,
image_documents=[image_node.node for image_node in image_nodes], # Pass only ImageNodes with paths
max_tokens=300
)
# Convert response to text and process it
response_text = llm_response.text # Extract the actual text content from the LLM response
# Extract the image paths after "Relevant Image Paths:"
image_paths = re.findall(r'Relevant Image Paths:\s*(.*)', response_text)
if image_paths:
# Split the paths by comma if multiple paths are present and strip any extra whitespace
image_paths = [path.strip() for path in image_paths[0].split(",")]
# Filter out the "Relevant Image Paths" part from the displayed response
filtered_response = re.sub(r'Relevant Image Paths:.*', '', response_text).strip()
display(Markdown(f"**Query**: {query}"))
# Print the filtered response without image paths
display(Markdown(f"{filtered_response}"))
if image_paths!=['']:
# Plot images using the paths collected in the image_paths array
display_images(image_paths)
The final (filtered) response generated by the LLM for the above query is shown below.

This shows that the embedding model successfully connects the text embeddings with image embeddings and retrieves relevant results which are then further refined by the LLM.
The results of a few more test queries are shown below.



Now let’s test the multimodal embedding model for an image-to-image task. We use a different product image (not in the catalog) and use the retriever to bring the matching product images. The following code retrieves the matching product images with a modified helper function display_images.
import matplotlib.pyplot as plt
from PIL import Image
import os
def display_images(input_image_path, matched_image_paths):
"""
Plot the input image alongside matching images with appropriate labels.
"""
# Total images to show (input + first match)
total_images = 1 + len(matched_image_paths)
# Define the figure size
plt.figure(figsize=(7, 7))
# Display the input image
plt.subplot(1, total_images, 1)
if os.path.isfile(input_image_path):
input_image = Image.open(input_image_path)
plt.imshow(input_image)
plt.title("Given Image")
plt.axis("off")
# Display matching images
for idx, img_path in enumerate(matched_image_paths):
if os.path.isfile(img_path):
matched_image = Image.open(img_path)
plt.subplot(1, total_images, idx + 2)
plt.imshow(matched_image)
plt.title("Match Found")
plt.axis("off")
plt.tight_layout()
plt.show()
# Sample usage with specified paths
input_image_path = 'C:/Users/h02317/Downloads/trial2.png'
retrieval_results = retriever_engine.image_to_image_retrieve(input_image_path)
retrieved_images = []
for res in retrieval_results:
retrieved_images.append(res.node.metadata["file_path"])
# Call the function to display images side-by-side
display_images(input_image_path, retrieved_images[:2])
Some results of the input and output (matching) images are shown below.


These results show that this multimodal embedding model offers impressive performance across text-to-text, text-to-image, and image-to-image tasks. This model can be further explored for multimodal RAGs with large documents to enhance retrieval experience with diverse data types.
In addition, multimodal embedding models hold good potential in various business applications, including personalized recommendations, content moderation, cross-modal search engines, and customer service automation. These models can enable companies to develop richer user experiences and more efficient knowledge retrieval systems.
If you like the article, please clap the article and follow me on Medium and/or LinkedIn
GitHub
For the full code reference, please take a look at my repo:
Multimodal AI Search for Business Applications was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/rY5bW72
via IFTTT





