
Spoiler Alert: The Magic of RAG Does Not Come from AI
Why retrieval, not generation, makes RAG systems magical
Quick POCs
Most quick proof of concepts (POCs) which allow a user to explore data with the help of conversational AI simply blow you away. It feels like pure magic when you can all of a sudden talk to your documents, or data, or code base.
These POCs work wonders on small datasets with a limited count of docs. However, as with almost anything when you bring it to production, you quickly run into problems at scale. When you do a deep dive and you inspect the answers the AI gives you, you notice:
- Your agent doesn’t reply with complete information. It missed some important pieces of data
- Your agent doesn’t reliably give the same answer
- Your agent isn’t able to tell you how and where it got which information, making the answer significantly less useful
It turns out that the real magic in RAG does not happen in the generative AI step, but in the process of retrieval and composition. Once you dive in, it’s pretty obvious why…
* RAG = Retrieval Augmented Generation — Wikipedia Definition of RAG
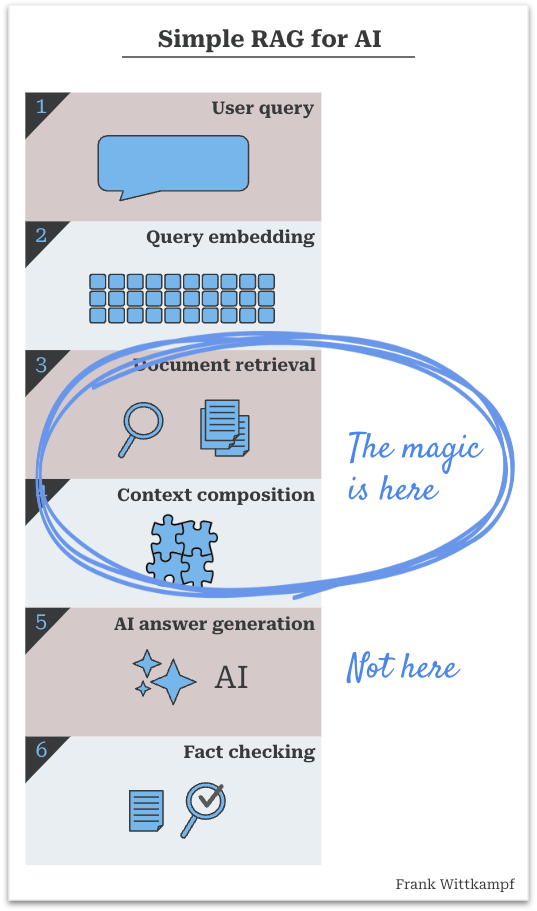
So, how does a RAG-enabled AI agent answer a question?
A quick recap of how a simple RAG process works:
- It all starts with a query. The user asked a question, or some system is trying to answer a question. E.g. “Does patient Walker have a broken leg?”
- A search is done with the query. Mostly you’d embed the query and do a similarity search, but you can also do a classic elastic search or a combination of both, or a straight lookup of information
- The search result is a set of documents (or document snippets, but let’s simply call them documents for now)
- The documents and the essence of the query are combined into some easily readable context so that the AI can work with it
- The AI interprets the question and the documents and generates an answer
- Ideally this answer is fact checked, to see if the AI based the answer on the documents, and/or if it is appropriate for the audience
Where’s the magic?
The dirty little secret is that the essence of the RAG process is that you have to provide the answer to the AI (before it even does anything), so that it is able to give you the reply that you’re looking for.
In other words:
- the work that the AI does (step 5) is apply judgement, and properly articulate the answer
- the work that the engineer does (step 3 and 4) is find the answer and compose it such that AI can digest it
Which is more important? The answer is, of course, it depends, because if judgement is the critical element, then the AI model does all the magic. But for an endless amount of business use cases, finding and properly composing the pieces that make up the answer, is the more important part.
What are the typical engineering problems to solve if you want proper RAG process?
The first set of problems to solve when running a RAG process are the data ingestion, splitting, chunking, document interpretation issues. I’ve written about a few of these in prior articles, but am ignoring them here. For now let’s assume you have properly solved your data ingestion, you have a lovely vector store or search index.
Typical challenges:
- Duplication — Even the simplest production systems often have duplicate documents. More so when your system is large, you have extensive users or tenants, you connect to multiple data sources, or you deal with versioning, etc.
- Near duplication — Documents which largely contain the same data, but with minor changes. There are two types of near duplication:
— Meaningful — E.g. a small correction, or a minor addition, e.g. a date field with an update
— Meaningless — E.g.: minor punctuation, syntax, or spacing differences, or just differences introduced by timing or intake processing - Volume — Some queries have a very large relevant response data set
- Data freshness vs quality — Which snippets of the response data set have the most high quality content for the AI to use vs which snippets are most relevant from a time (freshness) perspective?
- Data variety — How do we ensure a variety of search results such that the AI is properly informed?
- Query phrasing and ambiguity — The prompt that triggered the RAG flow, might not be phrased in such a way that it yields the optimal result, or might even be ambiguous
- Response Personalization — The query might require a different response based on who asks it
This list goes on, but you get the gist.
Sidebar: Don’t unlimited context windows solve this?
Short answer: no.
The cost and performance impact of using extremely large context windows shouldn’t be underestimated (you easily 10x or 100x your per query cost), not including any follow up interaction that the user/system has.
However, putting that aside. Imagine the following situation.
We put Anne in room with a piece of paper. The paper says: *patient Joe: complex foot fracture.* Now we ask Anne, does the patient have a foot fracture? Her answer is “yes, he does”.
Now we give Anne a hundred pages of medical history on Joe. Her answer becomes “well, depending on what time you are referring to, he had …”
Now we give Anne thousands of pages on all the patients in the clinic…
What you quickly notice, is that how we define the question (or the prompt in our case) starts to get very important. The larger the context window, the more nuance the query needs.
Additionally, the larger the context window, the universe of possible answers grows. This can be a positive thing, but in practice, it’s a method that invites lazy engineering behavior, and is likely to reduce the capabilities of your application if not handled intelligently.
Suggested approaches
As you scale a RAG system from POC to production, here’s how to address typical data challenges with specific solutions. Each approach has been adjusted to suit production requirements and includes examples where useful.
Duplication
Duplication is inevitable in multi-source systems. By using fingerprinting (hashing content), document IDs, or semantic hashing, you can identify exact duplicates at ingestion and prevent redundant content. However, consolidating metadata across duplicates can also be valuable; this lets users know that certain content appears in multiple sources, which can add credibility or highlight repetition in the dataset.
# Fingerprinting for deduplication
def fingerprint(doc_content):
return hashlib.md5(doc_content.encode()).hexdigest()
# Store fingerprints and filter duplicates, while consolidating metadata
fingerprints = {}
unique_docs = []
for doc in docs:
fp = fingerprint(doc['content'])
if fp not in fingerprints:
fingerprints[fp] = [doc]
unique_docs.append(doc)
else:
fingerprints[fp].append(doc) # Consolidate sources
Near Duplication
Near-duplicate documents (similar but not identical) often contain important updates or small additions. Given that a minor change, like a status update, can carry critical information, freshness becomes crucial when filtering near duplicates. A practical approach is to use cosine similarity for initial detection, then retain the freshest version within each group of near-duplicates while flagging any meaningful updates.
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.cluster import DBSCAN
import numpy as np
# Cluster embeddings with DBSCAN to find near duplicates
clustering = DBSCAN(eps=0.1, min_samples=2, metric="cosine").fit(doc_embeddings)
# Organize documents by cluster label
clustered_docs = {}
for idx, label in enumerate(clustering.labels_):
if label == -1:
continue
if label not in clustered_docs:
clustered_docs[label] = []
clustered_docs[label].append(docs[idx])
# Filter clusters to retain only the freshest document in each cluster
filtered_docs = []
for cluster_docs in clustered_docs.values():
# Choose the document with the most recent timestamp or highest relevance
freshest_doc = max(cluster_docs, key=lambda d: d['timestamp'])
filtered_docs.append(freshest_doc)
Volume
When a query returns a high volume of relevant documents, effective handling is key. One approach is a **layered strategy**:
- Theme Extraction: Preprocess documents to extract specific themes or summaries.
- Top-k Filtering: After synthesis, filter the summarized content based on relevance scores.
- Relevance Scoring: Use similarity metrics (e.g., BM25 or cosine similarity) to prioritize the top documents before retrieval.
This approach reduces the workload by retrieving synthesized information that’s more manageable for the AI. Other strategies could involve batching documents by theme or pre-grouping summaries to further streamline retrieval.
Data Freshness vs. Quality
Balancing quality with freshness is essential, especially in fast-evolving datasets. Many scoring approaches are possible, but here’s a general tactic:
- Composite Scoring: Calculate a quality score using factors like source reliability, content depth, and user engagement.
- Recency Weighting: Adjust the score with a timestamp weight to emphasize freshness.
- Filter by Threshold: Only documents meeting a combined quality and recency threshold proceed to retrieval.
Other strategies could involve scoring only high-quality sources or applying decay factors to older documents.
Data Variety
Ensuring diverse data sources in retrieval helps create a balanced response. Grouping documents by source (e.g., different databases, authors, or content types) and selecting top snippets from each source is one effective method. Other approaches include scoring by unique perspectives or applying diversity constraints to avoid over-reliance on any single document or perspective.
# Ensure variety by grouping and selecting top snippets per source
from itertools import groupby
k = 3 # Number of top snippets per source
docs = sorted(docs, key=lambda d: d['source'])
grouped_docs = {key: list(group)[:k] for key, group in groupby(docs, key=lambda d: d['source'])}
diverse_docs = [doc for docs in grouped_docs.values() for doc in docs]
Query Phrasing and Ambiguity
Ambiguous queries can lead to suboptimal retrieval results. Using the exact user prompt is mostly not be the best way to retrieve the results they require. E.g. there might have been an information exchange earlier on in the chat which is relevant. Or the user pasted a large amount of text with a question about it.
To ensure that you use a refined query, one approach is to ensure that a RAG tool provided to the model asks it to rephrase the question into a more detailed search query, similar to how one might carefully craft a search query for Google. This approach improves alignment between the user’s intent and the RAG retrieval process. The phrasing below is suboptimal, but it provides the gist of it:
tools = [{
"name": "search_our_database",
"description": "Search our internal company database for relevent documents",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "A search query, like you would for a google search, in sentence form. Take care to provide any important nuance to the question."
}
},
"required": ["query"]
}
}]
Response Personalization
For tailored responses, integrate user-specific context directly into the RAG context composition. By adding a user-specific layer to the final context, you allow the AI to take into account individual preferences, permissions, or history without altering the core retrieval process.
By addressing these data challenges, your RAG system can evolve from a compelling POC into a reliable production-grade solution. Ultimately, the effectiveness of RAG relies more on careful engineering than on the AI model itself. While AI can generate fluent answers, the real magic lies in how well we retrieve and structure information. So the next time you’re impressed by an AI system’s conversational abilities, remember that it’s likely the result of an expertly designed retrieval process working behind the scenes.
I hope this article provided you some insight into the RAG process, and why the magic that you experience when talking to your data isn’t necessarily coming from the AI model, but is largely dependent on the design of your retrieval process.
Please comment with your thoughts.
Spoiler Alert: The Magic of RAG Does Not Come from AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/Wzqw5Jd
via IFTTT


