
The Statistical Significance Scam
A detailed look into the flaws of science’s favorite tool

Statistical significance is like the drive-thru of the research world. Roll up to the study, grab your “significance meal,” and boom — you’ve got a tasty conclusion to share with all your friends. And it isn’t just convenient for the reader, it makes researchers’ lives easier too. Why make the hard sell when you can say two words instead?
But there’s a catch.
Those fancy equations and nitty-gritty details we’ve conveniently avoided? They’re the real meat of the matter. And when researchers and readers rely too heavily on one statistical tool, we can end up making a whopper of a mistake, like the one that nearly broke the laws of physics.
In 2011, physicists at the renowned CERN laboratory announced a shocking discovery: neutrinos could travel faster than the speed of light. The finding threatened to overturn Einstein’s theory of relativity, a cornerstone of modern physics. The researchers were confident in their results, passing physics’ rigorous statistical significance threshold of 99.9999998%. Case closed, right?
Not quite. As other scientists scrutinized the experiment, they found flaws in the methodology and ultimately could not replicate the results. The original finding, despite its impressive “statistical significance,” turned out to be false.
In this article, we’ll delve into four critical reasons why you shouldn’t instinctively trust a statistically significant finding. Moreover, why you shouldn’t habitually discard non-statistically significant results.
TL;DR
The four key flaws of statistical significance:
- It’s made up: The statistical significance/non-significance line is all too often plucked out of thin air, or lazily taken from the general line of 95% confidence.
- It doesn’t mean what (most) people think it means: Statistical significance does not mean ‘There is Y% chance X is true’.
- It’s easy to hack (and frequently is): Randomness is frequently labeled statistically significant due to mass experiments.
- It’s nothing to do with how important the result is: Statistical significance is not related to the significance of the difference.
Flaw 1: It’s made up
Statistical significance is simply a line in the sand humans have created with zero mathematical support. Think about that for a second. Something that is generally thought of as an objective measure is, at its core, entirely subjective.
The mathematical part is provided one step before deciding on the significance, via a numerical measure of confidence. The most common form used in hypothesis testing is called the p-value. This provides the actual mathematical probability that the test data results were not simply due to randomness.
For example, a p-value of 0.05 means there’s a 5% chance of seeing these data points (or more extreme) due to random chance, or that we are 95% confident the result wasn’t due to chance. For example, suppose you believe a coin is unfair in favour of heads i.e. the probability of landing on heads is greater than 50%. You toss the coin 5 times and it lands on heads each time. There’s a 1/2 x 1/2 x 1/2 x 1/2 x 1/2 = 3.1% chance that it happened simply because of chance, if the coin was fair.
But is this enough to say it’s statistically significant? It depends who you ask.
Often, whoever is in charge of determining where the line of significance will be drawn in the sand has more influence on whether a result is significant than the underlying data itself.
Given this subjective final step, often in my own analysis I’d provide the reader of the study with the level of confidence percentage, rather than the binary significance/non-significance result. The final step is simply too opinion-based.
Sceptic: “But there are standards in place for determining statistical significance.”
I hear the argument a lot in response to my argument above (I talk about this quite a bit — much to the delight of my academic researcher girlfriend). To which, I respond with something like:
Me: “Of course, if there is a specific standard you must adhere to, such as for regulatory or academic journal publishing reasons, then you have no choice but to follow the standard. But if that isn’t the case then there’s no reason not to.”
Sceptic: “But there is a general standard. It’s 95% confidence.”
At that point in the conversation I try my best not to roll my eyes. Deciding your test’s statistical significance point is 95%, simply because that is the norm, is frankly lazy. It doesn’t take into account the context of what is being tested.
In my day job, if I see someone using the 95% significance threshold for an experiment without a contextual explanation, it raises a red flag. It suggests that the person either doesn’t understand the implications of their choice or doesn’t care about the specific business needs of the experiment.
An example can best explain why this is so important.
Suppose you work as a data scientist for a tech company, and the UI team want to know, “Should we use the color red or blue for our ‘subscribe’ button to maximise out Click Through Rate (CTR)?”. The UI team favour neither color, but must choose one by the end of the week. After some A/B testing and statistical analysis we have our results:
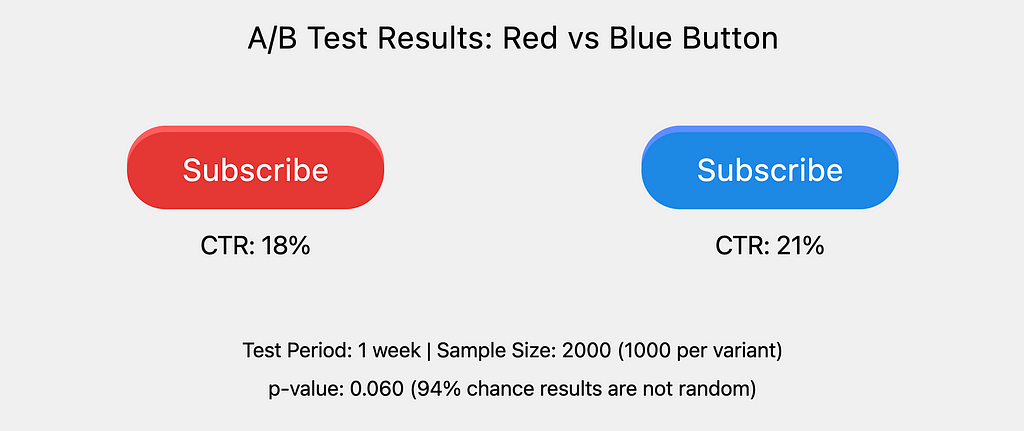
The follow-the-standards data scientist may come back to the UI team announcing, “Unfortunately, the experiment found no statistically significant difference between the click-through rate of the red and blue button.”
This is a horrendous analysis, purely due to the final subjective step. Had the data scientist taken the initiative to understand the context, critically, that ‘the UI team favour neither color, but must choose one by the end of the week’, then she should have set the significance point at a very high p-value, arguably 1.0 i.e. the statistical analysis doesn’t matter, the UI team are happy to pick whichever color had the highest CTR.
Given the risk that data scientists and the like may not have the full context to determine the best point of significance, it’s better (and simpler) to give the responsibility to those who have the full business context — in this example, the UI team. In other words, the data scientist should have announced to the UI team, “The experiment resulted with the blue button receiving a higher click-through rate, with a confidence of 94% that this wasn’t attributed to random chance.” The final step of determining significance should be made by the UI team. Of course, this doesn’t mean the data scientist shouldn’t educate the team on what “confidence of 94%” means, as well as clearly explaining why the statistical significance is best left to them.
Flaw 2: It doesn’t mean what (most) people think it means
Let’s assume we live in a slightly more perfect world, where point one is no longer an issue. The line in the sand figure is always perfect, huzza! Say we want to run an experiment, with the the significance line set at 99% confidence. Some weeks pass and at last we have our results and the statistical analysis finds that it’s statistically significant, huzza again!.. But what does that actually mean?
Common belief, in the case of hypothesis testing, is that there is a 99% chance that the hypothesis is correct. This is painfully wrong. All it means is there is a 1% chance of observing data this extreme or more extreme by randomness for this experiment.
Statistical significance doesn’t take into account whether the experiment itself is accurate. Here are some examples of things statistical significance can’t capture:
- Sampling quality: The population sampled could be biased or unrepresentative.
- Data quality: Measurement errors, missing data, or other data quality issues aren’t addressed.
- Assumption validity: The statistical test’s assumptions (like normality, independence) could be violated.
- Study design quality: Poor experimental controls, not controlling for confounding variables, testing multiple outcomes without adjusting significance levels.
Coming back to the example mentioned in the introduction. After failures to independently replicate the initial finding, physicists of the original 2011 experiment announced they had found a bug in their measuring device’s master clock i.e. data quality issue, which resulted in a full retraction of their initial study.
The next time you hear a statistically significant discovery that goes against common belief, don’t be so quick to believe it.
Flaw 3: It’s easy to hack (and frequently is)
Given statistical significance is all about how likely something may have occurred due to randomness, an experimenter who is more interested in achieving a statistical significant result than uncovering the truth can quite easily game the system.
The odds of rolling two ones from two dice is (1/6 × 1/6) = 1/36, or 2.8%; a result so rare it would be classified as statistically significant by many people. But what if I throw more than two dice? Naturally, the odds of at least two ones will rise:
- 3 dice: ≈ 7.4%
- 4 dice: ≈ 14.4%
- 5 dice: ≈ 23%
- 6 dice: ≈ 32.4%
- 7 dice: ≈ 42%
- 8 dice: ≈ 51%
- 12 dice: ≈ 80%*
*At least two dice rolling a one is the equivalent of: 1 (i.e. 100%, certain), minus the probability of rolling zero ones, minus the probability of rolling only one one
P(zero ones) = (5/6)^n
P(exactly one one) = n * (1/6) * (5/6)^(n-1)
n is the number of dice
So the complete formula is: 1 — (5/6)^n — n*(1/6)*(5/6)^(n-1)
Let’s say I run a simple experiment, with an initial theory that one is more likely than other numbers to be rolled. I roll 12 dice of different colors and sizes. Here are my results:

Unfortunately, my (calculated) hopes of getting at least two ones have been dashed… Actually, now that I think of it, I didn’t really want two ones. I was more interested in the odds of big red dice. I believe there is a high chance of getting sixes from them. Ah! Looks like my theory is correct, the two big red dice have rolled sixes! There is only a 2.8% chance of this happening by chance. Very interesting. I shall now write a paper on my findings and aim to publish it in an academic journal that accepts my result as statistically significant.
This story may sound far-fetched, but the reality isn’t as distant from this as you’d expect, especially in the highly regarded field of academic research. In fact, this sort of thing happens frequently enough to make a name for itself, p-hacking.
If you’re surprised, delving into the academic system will clarify why practices that seem abominable to the scientific method occur so frequently within the realm of science.
Academia is exceptionally difficult to have a successful career in. For example, In STEM subjects only 0.45% of PhD students become professors. Of course, some PhD students don’t want an academic career, but the majority do (67% according to this survey). So, roughly speaking, you have a 1% chance of making it as a professor if you have completed a PhD and want to make academia your career. Given these odds you need think of yourself as quite exceptional, or rather, you need other people to think that, since you can’t hire yourself. So, how is exceptional measured?
Perhaps unsurprisingly, the most important measure of an academic’s success is their research impact. Common measures of author impact include the h-index, g-index and i10-index. What they all have in common is they’re heavily focused on citations i.e. how many times has their published work been mentioned in other published work. Knowing this, if we want to do well in academia, we need to focus on publishing research that’s likely to get citations.
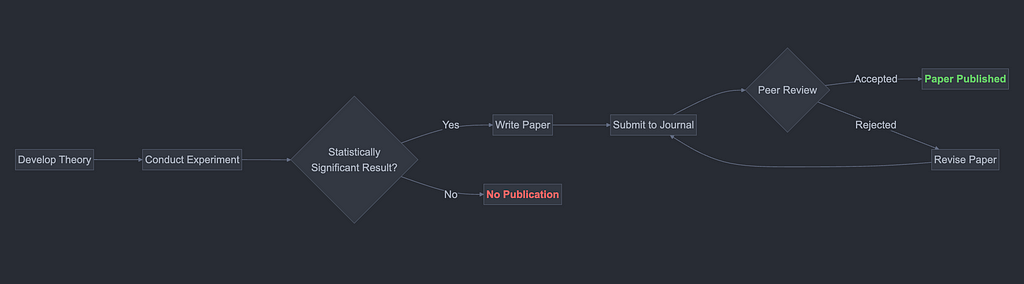
You’re far more likely to be cited if you publish your work in a highly rated academic journal. And, since 88% of top journal papers are statistically significant, you’re far more likely to get accepted into these journals if your research is statistically significant. This pushes a lot of well-meaning, but career-driven, academics down a slippery slope. They start out with a scientific methodology for producing research papers like so:
But end up warping their methodology to look scientific on the surface — but really, they’ve thrown proper scientific methods out the window:
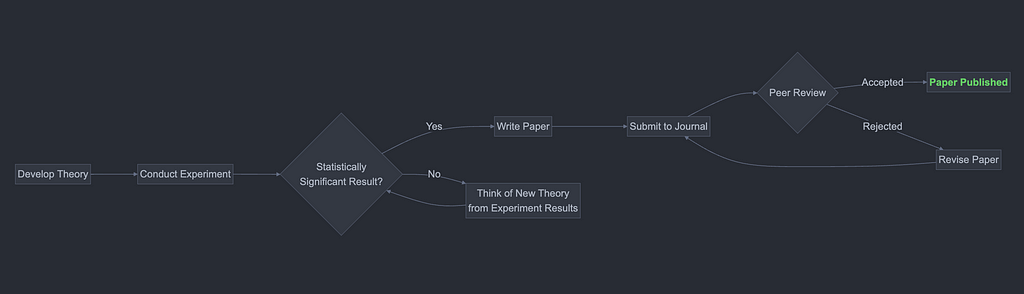
Given the decision diagrams have the researcher writing the paper after discovering a significant result, there’s no evidence for the journal reviewer to criticise the experiment for p-hacking.
That’s the theory anyway. But does it really happen all that often in reality?
The answer is a resounding yes. In fact, the majority of scientific research is unreproducible by fellow academics. Unreproducible means a research paper attempts to copy another research paper’s experiment, but ends up with statistically unexpected results. Often finding a statistically significant result in the original paper was statistically insignificant in the replication, or in some instances statistically significant in the opposite direction!
Flaw 4: It’s nothing to do with how important the result is
Finally, statistical significance doesn’t care about the scale of the difference.
Think about it this way — statistical significance basically just tells you “hey, this difference probably isn’t due to random chance” but says nothing about whether the difference actually matters in the real world.
Let’s say you test a new medication and find it reduces headache pain by 0.0001% compared to a placebo. If you run this test on millions of people, that tiny difference might be statistically significant, since your sample size is massive. But… who cares about a 0.0001% reduction in pain? That’s meaningless in practical terms!
On the other hand, you might find a drug that reduces pain by 5%, but there hasn’t been a large experiment to demonstrate statistical significance. It’s likely there are many examples of this in medicine because if the drug in question is cheap there is no incentive for pharmaceutical companies to run the experiment since large scale medical testing is expensive.
This is why it’s important to look at effect size (how big the difference is) separately from statistical significance. In the real world, you want both — a difference that’s unlikely to be random and big enough to actually matter.
An example of this mistake happening time and time again is when there is a (statistically significant) discovery in carcinogens i.e. something that causes cancer. A 2015 Guardian article said:
“Bacon, ham and sausages rank alongside cigarettes as a major cause of cancer, the World Health Organisation has said, placing cured and processed meats in the same category as asbestos, alcohol, arsenic and tobacco.”
This is straight up misinformation. Indeed, bacon, ham and sausages are in the same category as asbestos, alcohol, arsenic and tobacco. However, the categories do not denote the scale of the effect of the carcinogens, rather, how confident the World Health Organisation is that these items are carcinogens i.e. statistical significance.
The scale of the cancer cases caused by processed meat is questionable, since there haven’t been any Randomized Controlled Trials (RCT). One of the most damning research in favour of processed meat causing cancer is a 2020 observational (think correlation, not causation) study in the UK. It found that people eating over 79 grams per day on average of red and processed meat had a 32% increased risk of bowel cancer compared to people eating less than 11 grams per day on average.
However, to understand the true risk we need to understand the number of people who are at risk of bowel cancer. For every 10,000 people on the study who ate less than 11 grams of processed and red meat a day, 45 were diagnosed with bowel cancer, while it was 59 from those eating 79 grams of processed and red meat a day. That’s an extra 14 extra cases of bowel cancer per 10,000 people, or 0.14%. The survivability in the UK of bowel cancer is 53%, so a rough estimate of carcinogens in processed meat killing you is 0.07%.
Compare this to another substance The Guardian mention, tobacco. Cancer Research say:
“Tobacco is the largest preventable cause of cancer and death in the UK. And one of the largest preventable causes of illness and death in the world. Tobacco caused an estimated 75,800 deaths in the UK in 2021 — around a tenth (11%) of all deaths from all causes.”
First of all, wow. Don’t smoke.
Secondly, the death rate of cancer caused by tobacco is 11%/0.07% = 157 times greater than processed meat! Coming back to the quotation in the article, “Bacon, ham and sausages rank alongside cigarettes as a major cause of cancer”. Simply, fake news.
Summary
In conclusion, while statistical significance has a place in validating quantitative research, it’s crucial to understand its severe limitations.
As readers, we have a responsibility to approach claims of statistical significance with a critical eye. The next time you encounter a study or article touting a “statistically significant” finding, take a moment to ask yourself:
- Is the significance threshold appropriate for the context?
- How robust was the study design and data collection process?
- Could the researchers have engaged in p-hacking or other questionable practices?
- What is the practical significance of the effect size?
By asking these questions and demanding more nuanced discussions around statistical significance, we can help promote a more responsible and accurate use of the tool.
Over-time analysis
I actually think the main reason statistical significance has gained such over prominence is because of the name. People associate “statistical” with mathematical and objective, and “significance” with, well, significant. I hope this article has persuaded you that these associations are merely fallacies.
If the scientific and wider community wanted to deal with the over prominence issue, they should seriously consider simply renaming “statistical significance”. Perhaps “chance-threshold test” or “Non-random confidence”. Then again, this would lose its Big Mac convenience.
The Statistical Significance Scam was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/SzHX7rC
via IFTTT


