
Context-Aided Forecasting: Enhancing Forecasting with Textual Data
A promising alternative approach to improve forecasting

The use of textual data to enhance forecasting performance isn’t new.
In financial markets, text data and economic news often play a critical role in producing accurate forecasts — sometimes even more so than numeric historical data.
Recently, many large language models (LLMs) have been fine-tuned on Fedspeak and news sentiment analysis. These models rely solely on text data to estimate market sentiment.
An intriguing new paper, “Context is Key”[1], explores a different approach: how much does forecasting accuracy improve by combining numerical and external text data?
The paper introduces several key contributions:
- Context-is-Key (CiK) Dataset: A dataset of forecasting tasks that pairs numerical data with corresponding textual information.
- Region of Interest CRPS (RCRPS): A modified CRPS metric designed for evaluating probabilistic forecasts, focusing on context-sensitive windows.
- Context-is-Key Benchmark: A new evaluation framework demonstrating how external textual information benefits popular time-series models.
Let’s dive in.
✅ Find the hands-on project for Context-is-Key in the AI Projects folder — showing how to use Meta’s popular Llama-3.1 model for context-aided forecasting.
Context-is-Key Methodology
The idea is simple:
How can we embed additional text information into historical numerical data to improve the accuracy of forecasting models?
Since traditional time-series models can’t process textual data, the authors employ LLMs for this purpose.
They outline 4 main methods for integrating text data:
A) Provide Additional Context
In Figure 1, the model overestimates afternoon sunlight levels in the following time series example from a weather dataset.
By specifying that the location is in Alaska, the prediction aligns more closely with observed data:
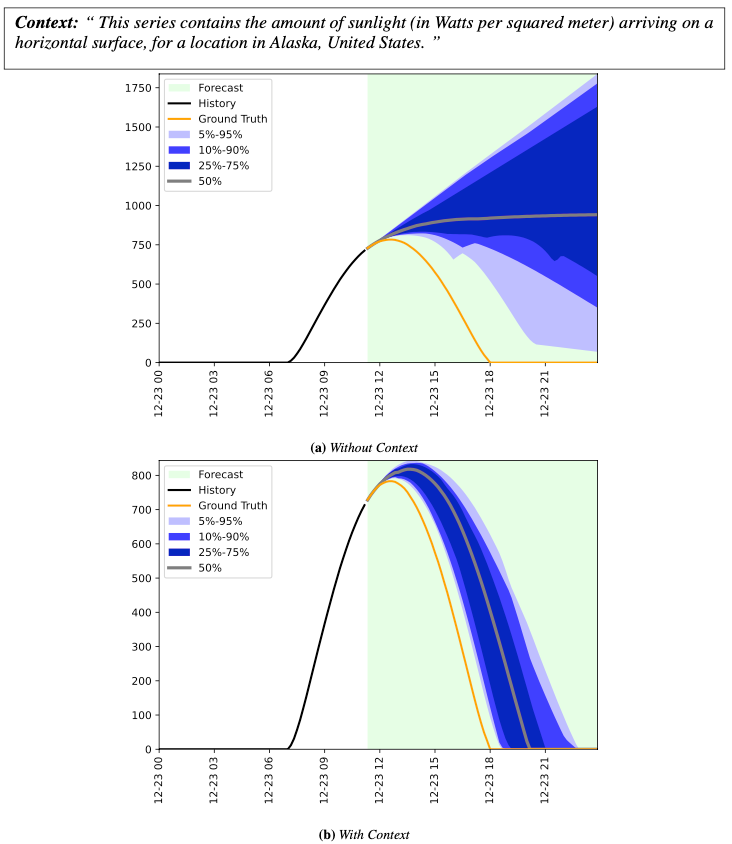
Additionally, the probabilistic coverage improves. While the ground truth remains outside the 5%-95% prediction interval, the added context helps refine the model.
B) Future-known Context Input
Embedding future-known information can better guide forecasting.
This is already possible with current models that accept future-known inputs like NHITS. The difference here is we can supply ad-hoc information.
In Figure 2, the model is informed that the target variable will likely drop to zero — common in intermittent data:
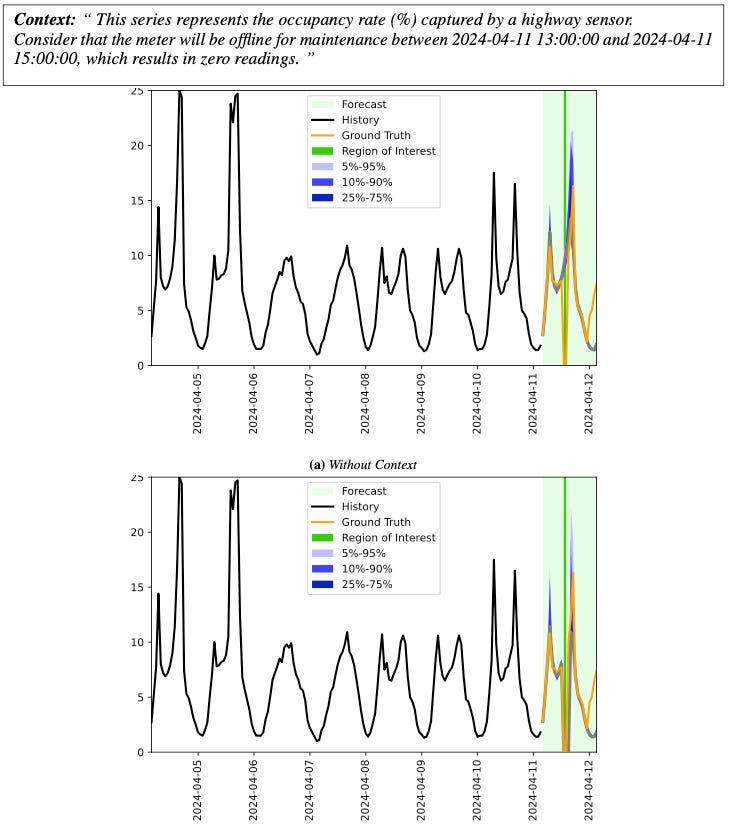
Key observations:
- The authors define a Region-of-Interest (ROI) covering the zero-inflated window, prompting the model to focus on this range when calculating CPRS — this calculates the RCRPS metrics I mentioned earlier.
- This context enables the model to capture sparse data effectively (zoom into the figure for details).
C) Bound the Forecast to Specific Levels
This feature is interesting as traditional time-series models can’t achieve it.
In the task below, we inform the model that the target value is expected to exceed 0.80:
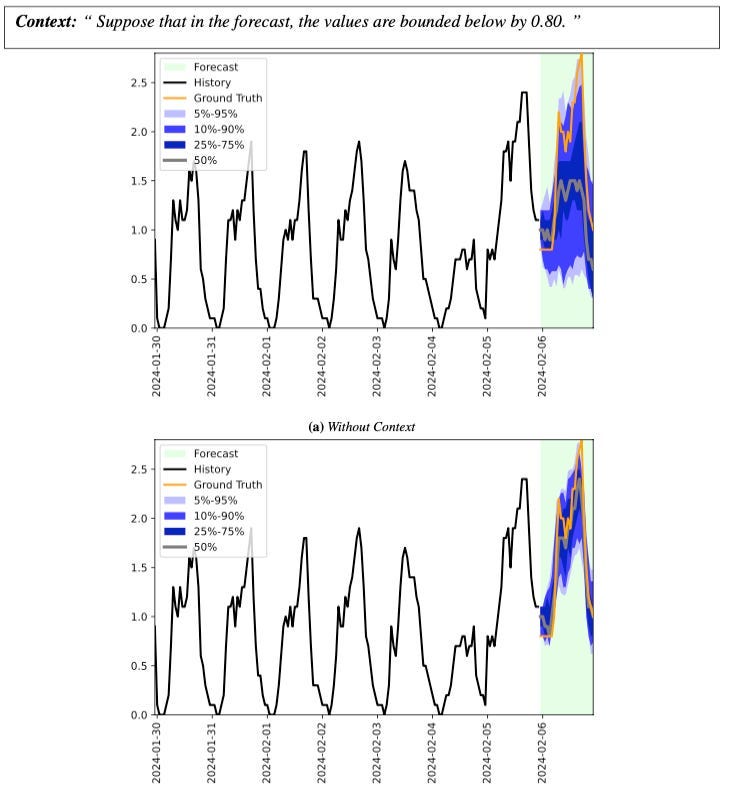
We notice the following:
- The initial prediction stays above 0.8 for most of the forecast.
- Adding bounds steers predictions closer to the ground truth while tightening the prediction interval and reducing uncertainty.
D) In-Context Learning / Cold Start
This approach is common in text models.
By including examples as part of the input, models improve accuracy. In text applications, this is called in-context learning and can be adapted for forecasting.
In Figure 4, examples of unemployment rates from U.S. states are added to the prompt:
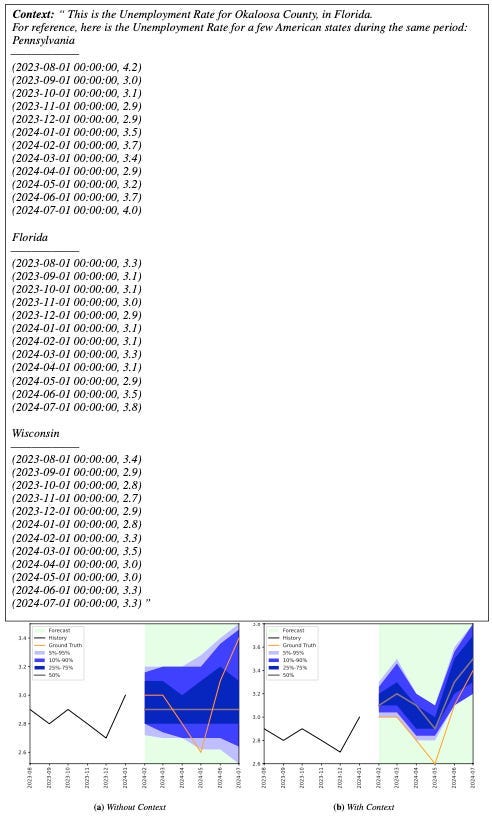
- The model adjusts predictions by leveraging the unemployment data provided.
- This is particularly useful in cold-start scenarios: when predicting a new time series without numerical context, we can supply examples with similar characteristics to guide the model.
The General Framework
We just saw a few examples of the CiK Dataset.
The authors manually curated and released 71 tasks across various domains and datasets. They used live time-series data to include foundation time-series models like MOIRAI in the benchmark, ensuring exposure to existing public datasets and avoiding data leakage.
The authors grouped these tasks into three categories: instruction following, retrieval, and reasoning. Details of these tasks can be browsed here. The context format is depicted in Figure 5:
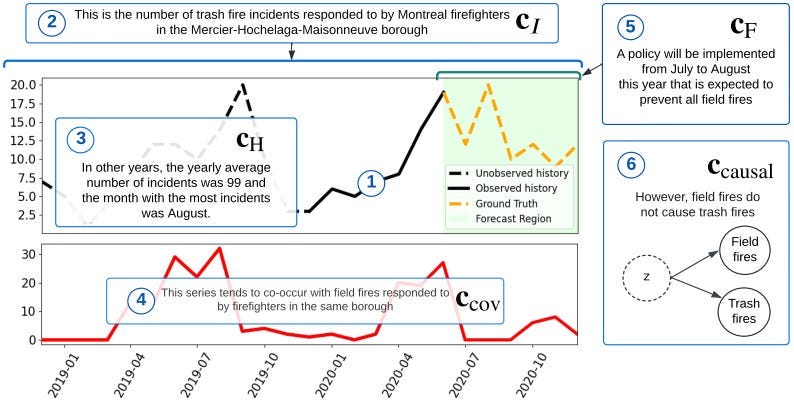
The context of a process is built on several key components that provide a comprehensive understanding of the target variable and its behavior. First is Intemporal Information (cI), which encompasses time-invariant details. This includes descriptions of the process, the intrinsic nature of the target variable, patterns like long-period seasonalities that can’t be deduced from numerical data, and constraints such as positivity requirements for values.
Historical Information (cH) offers insights into past behaviors not visible in the numerical data. This could include statistics on past series values or reasons for ignoring irrelevant patterns, such as anomalies caused by sensor maintenance. These details help refine the understanding of historical trends and anomalies.
Covariate Information (ccov) pertains to additional variables linked statistically to the target variable, helping improve predictions. These could be factors like correlated variables that provide context or enhance the predictive accuracy of the analysis.
Finally, Future Information (cF) and Causal Information (ccausal) focus on forward-looking and relational aspects. Future Information includes anticipated events, simulated scenarios, or constraints (e.g., inventory shortages) that might influence outcomes. Meanwhile, Causal Information highlights relationships between covariates and the target, distinguishing genuine causation from coincidental correlations or confounding effects. Together, these elements ensure a holistic view of the process.
Figures 1–4 focused on tasks involving Intemporal, Historical, and Future Information contexts. Refer to the original paper for more examples.
CiK Benchmark
The authors benchmarked models in the CiK Dataset across 4 categories:
- LLMs: Includes popular closed LLMs (e.g., GPT4-o) and open-source models (Mixtral-8x7B, Llama-3–8b, and Llama-3.1–405b).
- LLM-based Forecasters: Covers Time-LLM and UniTime, which use GPT-2 as a backbone for processing textual data alongside time-series components.
- Time-Series Foundation Models: Pretrained models like MOIRAI and Chronos deliver zero-shot forecasts without task-specific training.
- Statistical Models: Baseline models like ARIMA and ETS fitted to each task’s numerical history.
For the first 2 categories, where text data is applicable, performance was compared with and without context using 2 prompting methods:
- Direct Prompt: Models generate forecasts for the entire horizon in a single step Think of it as a multi-step forecast.
- LLMP (LLM Processes): Produces forecasts step-by-step, appending each result to the context for the next prediction Think of it as autoregressive/recursive forecasting.
The results are shown in Figure 6 below. The scores are partitioned by both the type of task and method (Direct vs LLMP)
Note: Each model includes both the base and fine-tuned versions. For example, Llama-3–70B represents the base model, while Llama-3–70B-Inst is the fine-tuned version. The base models are pretrained on massive corpora (trillions of words) to predict the next word in a sequence. Fine-tuned models undergo additional training on smaller instruction datasets (~100k samples or more), making them more refined.
Instruction datasets follow a format like:
“[INST] Do this task… [/INST] Here’s the answer…”
Each model has its own instruction format, but all Chat LLMs seen online are trained on such datasets. There is also a third step, alignment, where the LLM is further trained to provide helpful, unbiased, and non-toxic responses. However, this step is beyond the scope of the current paper, as it focuses on generating numbers rather than text.

We notice the following:
- LLMs outperform other models on average.
- Direct Prompt is better than LLMP for larger models (>70B parameters).
- Fine-tuned models perform better with Direct Prompt. In LLMP, base versions often excel since they aren’t instruction-trained.
- Open-source Llama-3.1–405B-Inst outperforms proprietary GPT-4o.
- TS foundation models surpass statistical models but lag behind LLM-based models since they don’t leverage external context.
It’s crucial to evaluate the impact of context on LLM-based models:
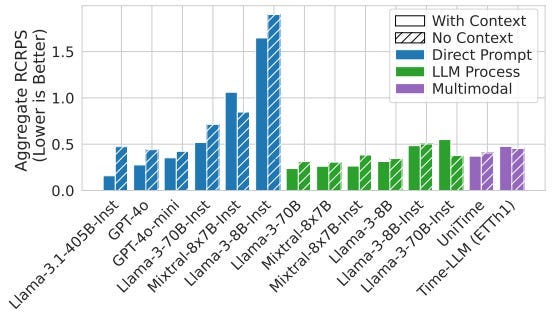
As expected, most LLM-based models benefit from additional context.
Another key factor is inference cost.
Bigger LLMs, especially those with >70B parameters, require expensive GPUs with vast VRAM. For example, Llama-3.1–70 has 70 billion parameters. Each fp16 parameter uses 2 bytes, so loading the model requires 140 GB of memory (70 billion × 2 bytes) plus overhead.
Proprietary LLMs like GPT-4o add costs through paywalled APIs, charging per token — rates that fluctuate over time.
To address this, the authors conducted a cost analysis to evaluate performance in relation to runtime:

Notice that:
- Llama-405B-Instruct scores are the highest but require extensive training time (log-scaled runtime axis).
- LLMP models take longer as they use autoregressive techniques, generating one forecast at a time.
- TS foundation models balance runtime and performance effectively. Undoubtedly, multi-modal TS foundation models hold great potential.
Closing Remarks
As we’ve discussed in this article, the future of foundation TS models lies in their ability to incorporate multiple domains/modalities.
In practice, time series data depends on various external factors — some of which are impossible to capture with the available numerical features or covariates.
Text is one such factor. This is why leveraging text in time series problems can be transformative, depending on the scenario.
The “Context is Key” framework isn’t a native multimodal model — it’s a perspective on combining an LLM with a traditional forecasting model. Future research may explore ways to ensemble these 2 modalities.
Meanwhile, preliminary native multimodal TS models are emerging. We’ll cover them in a future article, so stay tuned!
Thank you for reading!
- Subscribe to my newsletter, AI Horizon Forecast!
Will Transformers Revolutionize Time-Series Forecasting? - Advanced Insights, Part 2
References
[1] Williams et al. Context is Key: A Benchmark for Forecasting with Essential Textual Information
Context-Aided Forecasting: Enhancing Forecasting with Textual Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/cVJo1OX
via IFTTT


