
Data Valuation — A Concise Overview
Understanding the Value of your Data: Challenges, Methods, and Applications
ChatGPT and similar LLMs were trained on insane amounts of data. OpenAI and Co. scraped the internet, collecting books, articles, and social media posts to train their models. It’s easy to imagine that some of the texts (like scientific or news articles) were more important than others (such as random Tweets). This is true for almost any dataset used to train machine learning models; they contain almost always noisy samples, have wrong labels, or have misleading information.
The process that tries to understand how important different training samples are for the training process of a machine learning model is called Data Valuation. Data Valuation is also known as Data Attribution, Data Influence Analysis, and Representer Points. There are many different approaches and applications, some of which I will discuss in this article.
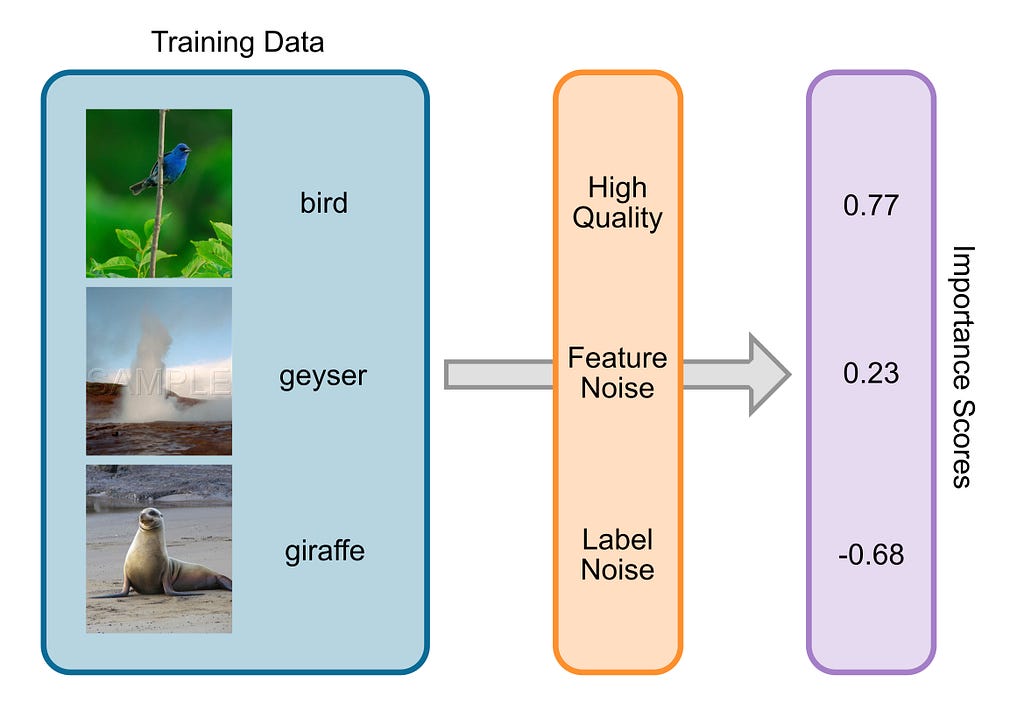
Why do we need Data Valuation?
Data Markets
AI will become an important economic factor in the coming years, but they are hungry for data. High-quality data is indispensable for training AI models, making it a valuable commodity. This leads to the concept of data markets, where buyers and sellers can trade data for money. Data Valuation is the basis for pricing the data, but there’s a catch: Sellers don’t want to keep their data private until someone buys it, but for buyers, it is hard to understand how important the data of that seller will be without having seen it. To dive deeper into this topic, consider having a look at the papers “A Marketplace for Data: An Algorithmic Solution” and “A Theory of Pricing Private Data”.
Data Poisoning
Data poisoning poses a threat to AI models: Bad actors could try to corrupt training data in a way to harm the machine learning training process. This can be done by subtly changing training samples in a way that’s invisible for humans, but very harmful for AI models. Data Valuation methods can counter this because they naturally assign a very low importance score to harmful samples (no matter if they occur naturally, or by malice).
Explainability
In recent years, explainable AI has gained a lot of traction. The High-Level Experts Group on AI of the EU even calls for the explainability of AI as foundational for creating trustworthy AI. Understanding how important different training samples are for an AI system or a specific prediction of an AI system is important for explaining its behaviour.
Active Learning
If we can better understand how important which training samples of a machine learning model are, then we can use this method to acquire new training samples that are more informative for our model. Say, you are training a new large language model and find out that articles from the Portuguese Wikipedia page are super important for your LLM. Then it’s a natural next step to try to acquire more of those articles for your model. In a similar fashion, we used Data Valuation in our paper on “LossVal” to acquire new vehicle crash tests to improve the passive safety systems of cars.
Overview of Data Valuation Methods
Now we know how useful Data Valuation is for different applications. Next, we will have a look at understanding how Data Valuation works. As described in our paper, Data Valuation methods can be roughly divided into three branches:
- Retraining-Based Approaches
- Gradient-Based Approaches
- Data-Based Approaches
- “Others”
Retraining-Based Approaches
The common scheme of retraining-based approaches is that they train a machine learning model multiple times to gain insight into the training dynamics of the model, and ultimately, into the importance of each training sample. The most basic approach (which was introduced in 1977 by Dennis Cook) simply retrains the machine learning model without a data point to determine the importance of that point. If removing the data point decreases the performance of the machine learning model on a validation dataset, then we know that the data point was bad for the model. Reversely, we know that the data point was good (or informative) for the model if the model’s performance on the validation set increases. Repeat the retraining for each data point, and you have valuable importance scores for your complete dataset. This kind of score is called the Leave-One-Out error (LOO). Completely retraining your machine learning model for every single data point is very inefficient, but viable for simple models and small datasets.
Data Shapley extends this idea using the Shapley value. The idea was published concurrently by both Ghorbani & Zou and by Jia et al. in 2019. The Shapley value is a construct from game theory that tells you how much each player of a coalition contributed to the payout. A closer-to-life example is the following: Imagine you share a Taxi with your friends Bob and Alice on the way home from a party. Alice lives very close to your starting destination, but Bob lives much farther away, and you're somewhere in between. Of course, it wouldn’t be fair if each of you pays an equal share of the final price, even though you and Bob drive a longer distance than Alice. The Shapley value solves this, by looking at all the sub-coalitions: What if only you and Alice shared the taxi? What if Bob drove alone? And so on. This way, the Shapley value can help you all three pay a fair share towards the final taxi price. This can also be applied to data: Retrain a machine learning model on different subsets of the training data to fairly assign an “importance” to each of the training samples. Unfortunately, this is extremely inefficient: calculating the exact Shapley values would need more than the O(2ⁿ) retrainings of your machine learning model. However, Data Shapley can be approximated much more efficiently using Monte Carlo methods.
Many alternative methods have been proposed, for example, Data-OOB and Average Marginal Effect (AME). Retraining-based approaches struggle with large training sets, because of the repeated retraining. Importance scores calculated using retraining can be imprecise because of the effect of randomness in neural networks.
Gradient-Based Approaches
Gradient-based approaches only work for machine learning algorithms based on gradient, such as Artificial Neural Networks or linear and logistic regression.
Influence functions are a staple in statistics and were proposed by Dennis Cook, who was mentioned already above. Influence functions use the Hessian matrix (or an approximation of it) to understand how the model’s performance would change if a certain training sample was left out. Using Influence Functions, there is no need to retrain the model. This works for simple regression models, but also for neural networks. Calculating influence functions is quite inefficient, but approximations have been proposed.
Alternative approaches, like TraceIn and TRAK track the gradient updates during the training of the machine learning model. They can successfully use this information to understand how important a data point is for the training without needing to retrain the model. Gradient Similarity is another method that tracks the gradients but uses them to compare the similarity of training and validation gradients.
For my master’s thesis, I worked on a new gradient-based Data Valuation method that exploits gradient information in the loss function, called LossVal. We introduced a self-weighting mechanism into standard loss functions like mean squared error and cross-entropy loss. This allows to assign importance scores to training samples during the first training run, making gradient tracking, Hessian matrix calculation, and retraining unnecessary, while still achieving state-of-the-art results.
Data-Based Approaches
All methods we touched on above are centered around a machine learning model. This has the advantage, that they tell you how important training samples are for your specific use case and your specific machine learning model. However, some applications (like Data Markets) can profit from “model-agnostic” importance scores that are not based on a specific machine learning model, but instead solely build upon the data.
This can be done in different ways. For example, one can analyze the distance between the training set and a clean validation set or use a volume measure to quantify the diversity of the data.
“Others”
Under this category, I subsume all methods that do not fit into the other categories. For example, using K-nearest neighbors (KNN) allows a much more efficient computation of Shapley values without retraining. Sub-networks that result from zero-masking can be analyzed to understand the importance of different data points. DAVINZ analyzes the change in performance when the training data changes by looking at the generalization boundary. Simfluence runs simulated training runs and can estimate how important each training sample is based on that. Reinforcement learning and evolutionary algorithms can also be used for Data Valuation.
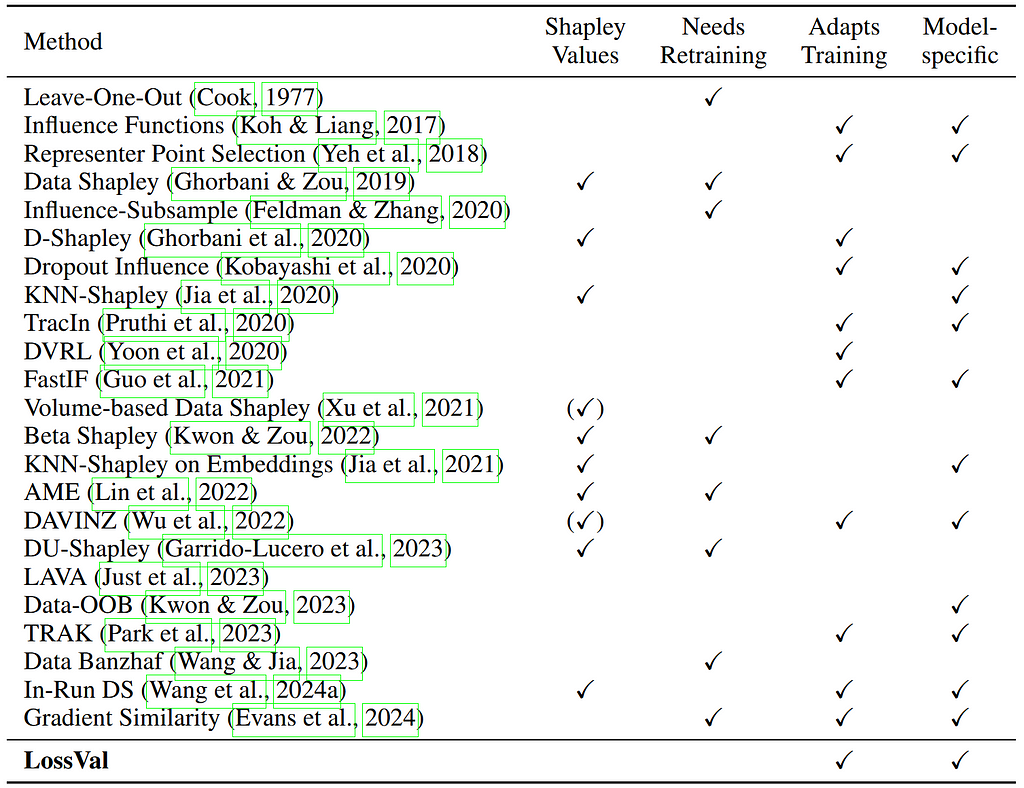
Current Research Directions
Currently, there are some research trends in different directions. Some research is being conducted to bring other game theoretic concepts, like the Banzhaf Value or the Winter value, to Data Valuation. Other approaches try to create joint importance scores that include other aspects of the learning process in the valuation, such as the learning algorithm. Further approaches work on private (where the data does not have to be disclosed) and personalized Data Valuation (where metadata is used to enrich the data).
Conclusion
Data Valuation is a growing topic, lots of other Data Valuation methods were not mentioned in this article. Data Valuation is a valuable tool for better understanding and interpreting machine learning models. If you want to learn more about Data Valuation, I can recommend the following articles:
- Training data influence analysis and estimation: a survey (Hammoudeh & Lowd, 2024)
- Data Valuation in Machine Learning: “Ingredients”, Strategies, and Open Challenges (Sim & Xu et al., 2022)
- OpenDataVal: a Unified Benchmark for Data Valuation (Jian & Liang et al., 2023)
- Awesome Data Valuation Repository
Data Valuation — A Concise Overview was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/GQwrLOW
via IFTTT


