
Overcoming Security Challenges in Protecting Shared Generative AI Environments
Ensuring Safe AI on Multi-Tenancy
‘Introduction
Let us begin by outlining the situation in the field: many organizations are riding the generative AI wave. In a recent report, over 65 percent of organizations reported having implemented generative AI in their business processes. However, upon closer inspection, the majority of these said applications are either early stage or in conceptual design phases mostly due to optimism bias around the company’s capabilities to deploy them successfully.

The gap between concept and production comes from several challenges: data integration issues, legacy system limitations, use case ROI considerations, and security barriers. In this article, we’ll focus on one critical security aspect — resources in multiple tenants.
In generative AI-powered applications, it is rarely only about composing text or responses. Most applications perform data lookup operations to feed LLMs with relevant information to ensure quality outputs. When an AI model is used in Generative AI that targets more than one client or internal department, we usually let each client or department have different sets of dataset to work with internally. This requirement makes multi-tenancy a fundamental aspect of ensuring security and scalability.
Real-life Multi-tenancy Issues
To demonstrate the necessity of multi-tenancy, let us consider two case studies drawn from real life:
Case Study 1: A Foreign International Banking Company internal chatbot
An international banking firm implements a knowledge management application powered by RAG (Retrieval-Augmented Generation tool). The system needs to perform the following functions:
- General Information: The type of information available on a company-wide basis, for instance, human resources guidelines, or legal compliance changes.
- Interdepartmental Tenancy: A central repository’s main unit. Numerous sensitive, high-attachment documents linked to various global-centric comprising departments, such as HR, Finance, Development & Product. All such departments act as tenants to the system.
In regard to privacy, one department’s employees should not view other department’s critical information, for example an HR employee should not be exposed to financial documents or product development sensitive data.
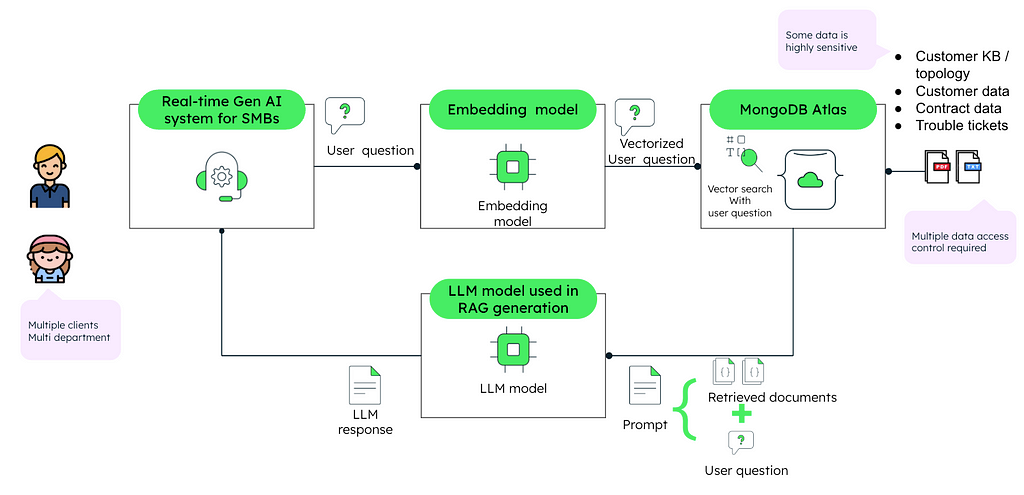
Case Study 2: A Cloud-based ERP system for SMBs
A business IT firm relies on the generative AI method to accelerate customer service for small to medium-sized businesses. Provided application enables:
- Clients to submit support requests with particular case information.
- The ability for support workers to search for similar past cases from the broader audience in the knowledge base information connected.
Another client’s data, comprising support cases, as well as KBs, and other sensitive information about agreements must not be mixed with the data of other clients. This ensures that Company A’s support cases are not visible in Company B’s support answers, even when both are using the same generative AI platform.
In either case, multi-tenancy is more than just a cherry on the cake, it is absolutely required.
Challenges of multi-tenancy and choosing the appropriate parameters to define the right balance
Trust and Data Isolation
Allowing one tenant to access another tenant’s data damages relations and violates legal obligations regarding personal information confidentiality. The problem is providing strong data isolation without compromising the application’s performance or the developer’s productivity. Isolation policies that are too complicated can degrade performance and may also increase the chances of a data breach should they be poorly executed.
Developer Productivity
New use cases and applications of Gen AI will be for different tenants to address and expand the geography of their needs. Building a separate data set or access controls at an object level does incur technical overhead that can slow down development and increase bugs during implementation. The key issues are, how to design effective and secure controls for different and diverse access without making the work of the developer complex and unmanageable.
Flexibility and Customization
There will be different tenants and they will have different needs and that’s why the architecture should allow different levels of configuration without major redevelopments. The aim is to enable or customize tenant specific features or configurations without violating the system design.
Developers and architects can design a multi-tenant system that effectively addresses data isolation, security, and efficiency. However, reaching the best target tradeoff is not a walk in the park as it requires due diligence and an in-depth appreciation of all relevant and applicable technical and commercial effects of the appropriate architectural design.
Proposed Solutions for Multi-tenant Architectures
When dealing with multi-tenancy in generative AI applications, many architectural techniques can be applied to achieve security, scalability, and personalization. Below are three practical solutions with their advantages, challenges, and code implementations:
Option 1: Separated Collections
In this approach, each tenant employer’s data is preserved within a separate collection in a specific database. Collection-based restrictions are granted which guarantee that different tenants’ data cannot be intermingled.
Effective Isolation: This concerns every tenant data associated with one record. Roles are assigned to specific collection attributes. Security and Privacy are normally high.
However, this could result in a problem of collection bloat when many tenants are deployed. It requires the application backend to handle the triage on different collections to query.

Define Roles for Collection Access:
{
"role": "HR_Access",
"db": "Tenant_DB",
"collection": "HR_Docs"
},
{
"role": "Finance_Access",
"db": "Tenant_DB",
"collection": "Finance_Docs"
}
Dynamic collection routing:
The identifier of the tenant (X-Tenant-ID) is included in the request header. The backend dynamically determines the appropriate collection based on this X-Tenant-ID.
Vector search query:
The $vectorSearch aggregation operator is meant to be used with the embedding that is hosted in a collection, to give the closest n neighbors to the input query vector.
API Request flow:
A tenant makes a vector search request specifying the tenant unique ID.The backend directs the query into the tenant collection and carries out the search.
from flask import Flask, request, jsonify
from pymongo import MongoClient
# Initialize Flask app
app = Flask(__name__)
# MongoDB Atlas Connection
client = MongoClient("mongodb+srv://<username>:<password>@cluster.mongodb.net/")
db = client["TenantDB"] # Replace with your database name
# Middleware to fetch tenant ID from request headers
@app.before_request
def fetch_tenant():
tenant_id = request.headers.get("X-Tenant-ID")
if not tenant_id:
return jsonify({"error": "Tenant ID is required"}), 400
request.tenant_id = tenant_id
# Route for vector search
@app.route('/vector-search', methods=['POST'])
def vector_search():
try:
# Get tenant-specific collection
tenant_id = request.tenant_id
collection_name = f"{tenant_id}_Collection" # e.g., TenantA_Collection
collection = db[collection_name]
# Get input query vector and search parameters
query_vector = request.json.get("vector")
num_candidates = request.json.get("numCandidates", 10)
limit = request.json.get("limit", 5)
if not query_vector:
return jsonify({"error": "Vector is required"}), 400
# Perform vector search
results = collection.aggregate([
{
"$vectorSearch": {
"vector": query_vector,
"path": "embedding", # Field storing the embeddings
"numCandidates": num_candidates,
"limit": limit
}
}
])
# Format the results
results_list = [result for result in results]
return jsonify(results_list)
except Exception as e:
return jsonify({"error": str(e)}), 500
# Start the Flask server
if __name__ == '__main__':
app.run(debug=True, port=5000)
Option 2: Role + Content Collection Control
All tenants information is captured in the same database but each document contains an important identifying metadata. Users’ roles and powers are stored in other separate databases. Also, access can be controlled using metadata controls embedded in the language of the query.
It eliminates the need to create so many collections by hosting all the tenants' data in one collection. This makes it Easier to Organize and Manage Business Information. There are many collections, making it easier to expand than separate collections standalone.
Proper governance of roles and metadata tags is essential.
How It Works?
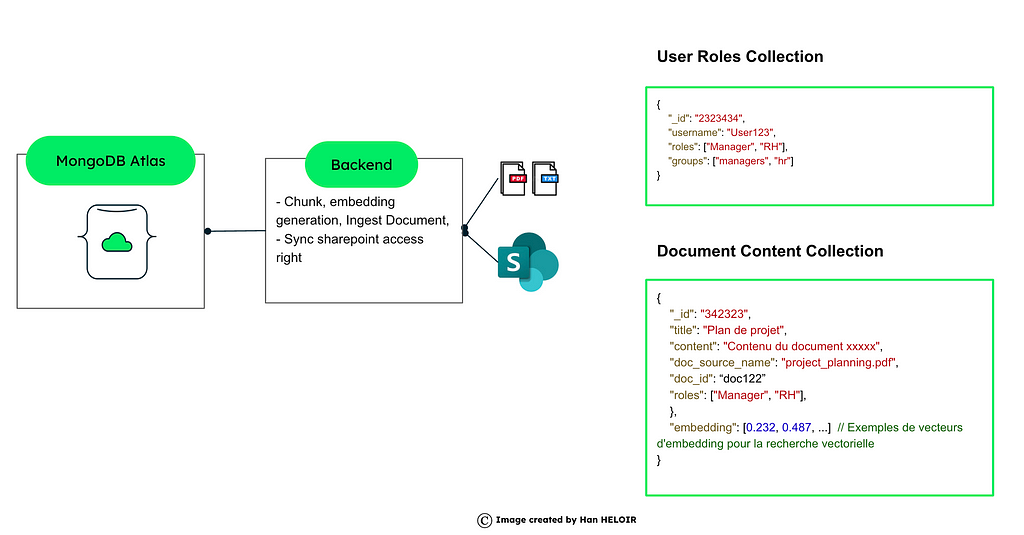
1. Metadata-Based Access Control:
Every document contains relevant metadata concerning the roles or the tenants of the resource who have the rights of access. Metadata is used in the queries to filter data and thereby control access to certain information.
2. User Roles Management:
A user Roles Access Collection holds the users, roles, groups, and tenants. • Using this information, access queries may be constructed on the fly as the queries are being executed.
This approach reduces the complexity of storage and retrieval by reducing the number of collections.
How to implement it?
User Roles Collection example
{
"_id": "12345",
"username": "user123",
"roles": ["HR_Manager", "HR_Staff"],
"tenant": "TenantA"
}
Document Content Collection example
{
"_id": "67890",
"title": "Employee Handbook",
"content": "HR policies and guidelines...",
"roles": ["HR_Manager", "HR_Staff"],
"tenant": "TenantA",
"embedding": [0.123, 0.456, 0.789...] // For vector search
}
Vector search index definition
You need to first create a vector search index on the collection before querying it for similarity search. Here’s what you can do in order to perform this using the PyMongo library.
from pymongo.mongo_client import MongoClient
from pymongo.operations import SearchIndexModel
import time
# Connect to your MongoDB Atlas deployment
uri = "<connectionString>" # Replace with your MongoDB Atlas URI
client = MongoClient(uri)
# Access the database and collection
database = client["MultiTenantDB"]
# Access the Content Collection
collection = db["ContentCollection"]
# Define the vector search index model
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"type": "vector",
"path": "embedding", # Field storing embeddings
"numDimensions": 1536, # Set to your embedding dimension size
"similarity": "euclidean" # Similarity metric (e.g., euclidean, cosine)
},
{
"type": "filter",
"path": "roles" # Field for role-based filtering
}
]
},
name="embedding_index",
type="vectorSearch"
)
# Create the search index
result = collection.create_search_index(model=search_index_model)
print("New search index named " + result + " is building.")
# Wait for the index to be ready
print("Polling to check if the index is ready. This may take up to a minute.")
predicate = lambda index: index.get("queryable") is True
while True:
indices = list(collection.list_search_indexes(result))
if len(indices) and predicate(indices[0]):
break
time.sleep(5)
print(result + " is ready for querying.")
client.close()
Retrieve User Roles
In order to maintain secure access to the system, the system gets user’s roles from the UserAccess collection. These roles serve the purpose of filters when conducting the vector search.
def get_roles_by_user_id(user_id):
"""
Fetch the roles assigned to a user from the UserAccess collection.
"""
user = db["UserAccess"].find_one({"_id": user_id})
return user["roles"] if user else []
# Example usage
user_roles = get_roles_by_user_id("user123") # Replace with the actual user ID
print(f"Retrieved roles for user: {user_roles}")
Perform Vector Search with Filtering
After obtaining the roles, the system executes a vector search in the DocumentAccessRights collection. The returned documents are pruned to leave only the documents accessible based on user’s roles.
def vector_search_with_filter(query_vector, user_roles):
"""
Perform a vector search with metadata filtering.
"""
results = db["ContentCollection"].aggregate([
{
"$vectorSearch": {
"exact": False,
"filter": {"roles": {"$in": user_roles}},
"index": "embedding_index", # Replace with your vector index name
"limit": 10,
"numCandidates": 100,
"path": "embedding", # Field storing the embeddings
"queryVector": query_vector, # Input query vector
}
}
])
return list(results)
# Example usage
query_vector = [0.1, 0.2, 0.3] # Replace with your actual query vector
search_results = vector_search_with_filter(query_vector, user_roles)
print(f"Search results: {search_results}")
User role retrieval and vector search with filter option are the two-step work performed, which allows secure and scalable multi-tenancy access control in MongoDB Atlas. With this configuration, applications that require semantic search and role based access control can be satisfied because metadata filtering is combined with vector search functionalities.
Option 3: Utilizing Credal AI’s Permissions Service
Credal AI provides a comprehensive Permissions Service API that facilitates dynamic, resource-specific authorization checks. By integrating this service with MongoDB Atlas’s vector search capabilities, organizations can ensure that users access only the data they’re authorized to view, thereby maintaining strict data isolation and security.
Centralized Authorization Management defines and enforces access policies across various resources and users from a single platform. Perform immediate — real-time authorization checks to ensure users have the necessary permissions before accessing resources. Handle complex access control requirements efficiently, making it suitable for large-scale, multi-tenant environments.
How to implement it?
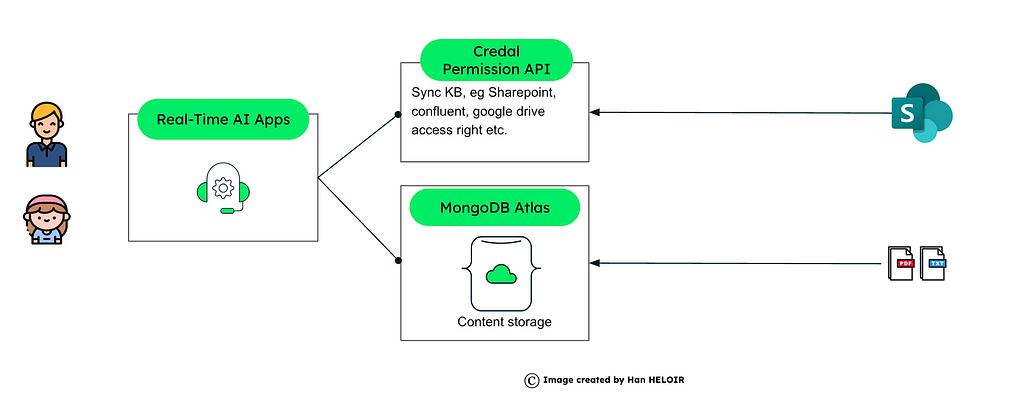
Define permissions in Credal AI:
We need to configure roles, users, and resources within the Credal AI Permissions Service and assign permissions to resources based on user roles.
curl -X POST https://api.credal.ai/v0/permissions/add \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"resourceIdentifier": {
"type": "external-resource-id",
"externalResourceId": "resource123",
"resourceType": "DOCUMENT"
},
"permissions": [
{
"role": "viewer",
"userEmail": "user@example.com"
}
]
}'
Perform Authorization Checks:
Before granting access to a resource, use Credal AI’s API to verify the user’s permissions.
import requests
def check_authorization(user_email, resource_id, api_key):
url = "https://api.credal.ai/v0/permissions/checkResourceAuthorizationForUser"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"resourceIdentifier": {
"type": "external-resource-id",
"externalResourceId": resource_id,
"resourceType": "DOCUMENT"
},
"userEmail": user_email
}
response = requests.post(url, headers=headers, json=data)
return response.json().get("authorized", False)
# Example usage
api_key = "<YOUR_API_KEY>"
is_authorized = check_authorization("user@example.com", "resource123", api_key)
if is_authorized:
print("Access Granted")
else:
print("Access Denied")
This approach offers developers complete control.
Integrate with MongoDB Atlas Vector Search:
Once we are set, we can perform vector searches to retrieve relevant documents. We can use Credal AI’s API to check if the user has access to each document retrieved.
from pymongo import MongoClient
import requests
# MongoDB Atlas Connection
client = MongoClient("mongodb+srv://<username>:<password>@cluster.mongodb.net/")
db = client["YourDatabase"]
collection = db["YourCollection"]
# Credal AI Authorization Check
def check_authorization(user_email, resource_id, api_key):
url = "https://api.credal.ai/v0/permissions/checkResourceAuthorizationForUser"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"resourceIdentifier": {
"type": "external-resource-id",
"externalResourceId": resource_id,
"resourceType": "DOCUMENT"
},
"userEmail": user_email
}
response = requests.post(url, headers=headers, json=data)
return response.json().get("authorized", False)
# Vector Search with Authorization
def vector_search_with_auth(query_vector, user_email, api_key):
results = collection.aggregate([
{
"$vectorSearch": {
"index": "vector_index",
"queryVector": query_vector,
"path": "embedding",
"limit": 10,
"numCandidates": 100
}
}
])
authorized_results = []
for result in results:
resource_id = result["_id"]
if check_authorization(user_email, resource_id, api_key):
authorized_results.append(result)
return authorized_results
# Example usage
query_vector = [0.1, 0.2, 0.3, ...] # Replace with your query vector
api_key = "<YOUR_API_KEY>"
user_email = "user@example.com"
authorized_docs = vector_search_with_auth(query_vector, user_email, api_key)
for doc in authorized_docs:
print(doc)
In addition to this approach, Credal provides as well the Copilot API and Permissioned Search API for seamless, high-performance querying. The Credal Copilot API generates precise, cited answers for specific user queries. The Permissioned Search API enables high-performance, dynamic search across document collections for exploring larger datasets.
Option 4: OpenFGA Open Souce Access Right Control
For every case that seeks to implement fine-grained access control dynamically, OpenFGA (Open Fine-Grained Authorization) is an additional option. OpenGL allows you to define relationships and policies between users, roles, and resources. This approach integrates seamlessly with MongoDB Atlas or other data storage to manage multi-tenant data access.
OpenFGA enables the definition of complex policies for dynamic tenant access. Policies can involve relationships like “user X can read document Y if they are part of tenant Z and have role R.”
You can define granular permissions for documents, collections, or other resources. This is ideal for highly customized and dynamic access control scenarios.
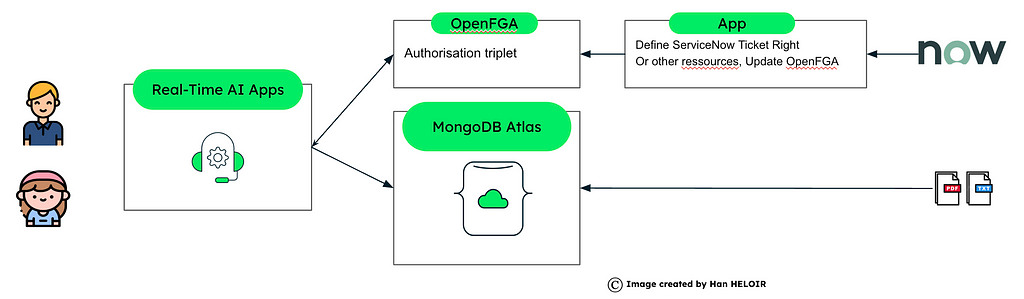
Define the Authorization Model in OpenFGA example
The authorization model defines the relationships between users, roles, and resources.
{
"authorization_model_id": "model123",
"type_definitions": {
"document": {
"relations": {
"reader": {
"this": {}
},
"editor": {
"this": {}
}
}
},
"user": {
"relations": {
"member": {
"this": {}
}
}
}
}
}
Relations:
- A “reader” can view the document.
- An “editor” can modify the document.
- Users can have relationships with specific documents or tenants.
How to implement it?
import asyncio
import requests
import json
import pymongo
from unstructured.partition.auto import partition
from openai import AzureOpenAI
class FGA_MDB_DEMO:
def __init__(self, azure_endpoint, api_version, api_key, mongo_uri, fga_api_url, fga_store_id, fga_api_token, authorization_model_id, db_name, collection_name):
self.az_client = AzureOpenAI(azure_endpoint=azure_endpoint, api_version=api_version, api_key=api_key)
self.mongo_client = pymongo.MongoClient(mongo_uri)
self.fga_api_url = fga_api_url
self.fga_store_id = fga_store_id
self.fga_api_token = fga_api_token
self.authorization_model_id = authorization_model_id
self.db_name = db_name
self.collection_name = collection_name
def generate_embeddings(self, text, model=""):
return self.az_client.embeddings.create(input = [text], model=model).data[0].embedding
def check_authorization(self, tuple_key):
url = f"{self.fga_api_url}/stores/{self.fga_store_id}/check"
headers = {
"Authorization": f"Bearer {self.fga_api_token}",
"content-type": "application/json",
}
data = {
"authorization_model_id": self.authorization_model_id,
"tuple_key": tuple_key
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()
def add_tuple(self, USER, RESOURCE):
url = f"{self.fga_api_url}/stores/{self.fga_store_id}/write"
headers = {
"Authorization": f"Bearer {self.fga_api_token}",
"content-type": "application/json",
}
data = {
"writes": {
"tuple_keys": [
{
"user": "user:"+USER,
"relation": "viewer",
"object": "doc:"+RESOURCE
}
]
},
"authorization_model_id": self.authorization_model_id
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()
def search_tool(self, text, USER_ID):
response = self.mongo_client[self.db_name][self.collection_name].aggregate([
{
"$vectorSearch": {
"index": "vector_index",
"queryVector": self.az_client.embeddings.create(model="text-embedding-ada-002",input=text).data[0].embedding,
"path": "embeddings",
"limit": 5,
"numCandidates": 30
}
}, {"$project":{"_id":0, "embeddings":0, "metadata":0}}
])
for doc in response:
tuple_key = {"user":"user:"+USER_ID,"relation":"viewer","object":"doc:"+doc["source"]}
response = self.check_authorization(tuple_key)
if response['allowed']:
print(f"Access Granted: User '{USER_ID}' has permission to read document '{doc['source']}'.")
else:
print(f"Access Denied: User '{USER_ID}' does not have permission to read document '{doc['source']}'.")
def partition_pdf(self, resource):
mdb_db = self.mongo_client[self.db_name]
mdb_collection = mdb_db[self.collection_name]
print("Clearing the db first...")
mdb_collection.delete_many({})
print("Database cleared.")
print("Starting PDF document partitioning...")
elements = partition(resource)
for element in elements:
mdb_collection.insert_one({
"text":str(element.text),
"embeddings":self.generate_embeddings(str(element.text), "text-embedding-ada-002"),
"metadata": {
"raw_element":element.to_dict(),
},
"source":resource
})
print("PDF partitioning and database insertion completed successfully.")
def fga_setup(self, user, resource):
response = self.add_tuple(user, resource)
print(f"FGA setup response: {response}")
async def main(self, user, resource):
print("Starting FGA setup...")
self.fga_setup(user, resource)
self.partition_pdf(resource)
print("Waiting for index to be updated. This may take a few seconds...")
await asyncio.sleep(15)
print("Starting search tool...")
self.search_tool("test",user)
self.search_tool("test",user+"-denyme")
print("Process completed successfully.")
if __name__ == "__main__":
fga_mdb_demo = FGA_MDB_DEMO(
azure_endpoint="",
api_version="2024-04-01-preview",
api_key="",
mongo_uri="mongodb+srv://<username>:<password>@cluster.mongodb.net/",
fga_api_url='http://localhost:8080',
fga_store_id='01J8VP1HYCHN459VT76DQG0W2R',
fga_api_token='',
authorization_model_id='01J8VP3BMPZNFJ480G5ZNF3H0C',
db_name="demo",
collection_name="mdb_fga"
)
asyncio.run(fga_mdb_demo.main("demo_user", "demo.pdf"))
This Python code implementation can be separated into 3 steps:
Partitioning and Embedding Generation:
The partition_pdf function splits a PDF into text chunks and generates embeddings for each chunk using Azure OpenAI.
Authorization Setup:
The add_tuple function defines relationships in OpenFGA, such as granting a user “viewer” access to a specific document.
Vector Search and Authorization Check:
The search_tool function performs a vector search using MongoDB Atlas and checks access permissions using OpenFGA.
Please refer to Fabian Valle’s notebook for more details on this option.
Conclusion
To summarize the whole discussion, it is essential to determine the level of multi-tenancy for any generative AI application since increasing it may enhance security, scalability, and user confidence. However, the combination of ensuring CRUD privileges for data is typically a challenging task. Businesses need to find the proper equilibrium between security and allowing for customization or user personalization. Systems can then be developed that would enable the safe sharing of information while still adapting and evolving in shared AI, depending on the desired level of security.
Before you go! 🦸🏻♀️
- If you found value in this article and wish to show your support, please ‘like’ this LinkedIn post. You can also find the free friend link in the LinkedIn post. Your engagement will help extend the reach of this article, your support acts as a great motivator for me. ✍🏻🦾❤️
- Clap my article 50 times, that will really really help me out and boost this article to others.👏
- Follow me on Medium , LinkedIn and subscribe to get my latest article.
Overcoming Security Challenges in Protecting Shared Generative AI Environments was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/My7BZsh
via IFTTT


