
Roadmap to Becoming a Data Scientist, Part 2: Software Engineering
Coding your road to Data Science: mastering key development skills
Introduction
Data science is undoubtedly one of the most fascinating fields today. Following significant breakthroughs in machine learning about a decade ago, data science has surged in popularity within the tech community. Each year, we witness increasingly powerful tools that once seemed unimaginable. Innovations such as the Transformer architecture, ChatGPT, the Retrieval-Augmented Generation (RAG) framework, and state-of-the-art computer vision models — including GANs — have had a profound impact on our world.
However, with the abundance of tools and the ongoing hype surrounding AI, it can be overwhelming — especially for beginners — to determine which skills to prioritize when aiming for a career in data science. Moreover, this field is highly demanding, requiring substantial dedication and perseverance.
As we understood from part 1, the main data science areas can be divided into three large categories: maths, software engineering and machine learning. In this article, we will focus on software engineering skills that learners need to master to become a data scientist.
Roadmap to Becoming a Data Scientist, Part 1: Maths
This article will focus solely on the software skills necessary to start a career in Data Science. Whether pursuing this path is a worthwhile choice based on your background and other factors will be discussed in a separate article.
Software engineering — key areas
Software engineering is a broad field that focuses on various stages of developing digital applications. The following diagram summarizes the most important ones.
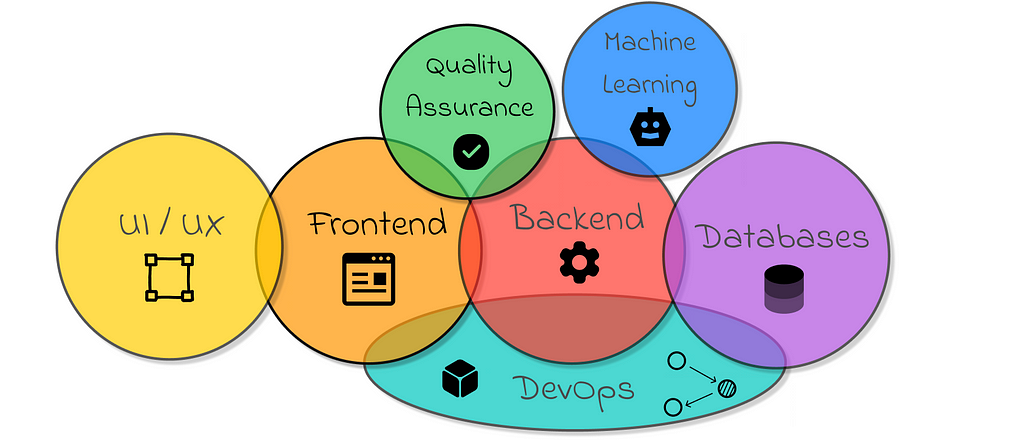
To construct an end product, which is often a predictive model, machine learning engineers need backend development skills to create a service that enables the use of their model or to collaborate efficiently with other backend engineers.
Moreover, skilled backend engineers possess the necessary expertise to enable their applications to interact with databases and to facilitate automatic deployment using DevOps pipelines.
Of course, it is possible to rely on other engineers in the team to delegate tasks, but it is much better to become independent by developing cross-functional expertise.
Even if there are specialized engineers on the team, having a basic knowledge of other domains is essential for communicating with them more effectively.
In reality, many companies today, especially start-ups, expect data scientists to contribute across different stages of an application’s lifecycle. This can even extend to data scientists working on backend and DevOps tasks, or even frontend development, when it is necessary to quickly create an interface to test a developed model.

With all these aspects in mind, we will now explore the essential competencies and skills that data scientists should ideally possess in the modern era.
# 01. Python
Why Python?
There are many programming languages, and no single one can be considered the best, as each serves its unique purpose and can be evaluated from several distinct perspectives. However, when it comes to data science, Python stands out as a clear winner.
Python offers an abundance of data analysis tools and user-friendly machine learning libraries, enabling efficient development of data science projects. While other popular languages like JavaScript or Java provide some functionality out of the box, Python offers a much richer selection of frameworks. Furthermore, Python’s simple syntax makes it easier and faster to create complex models and pipelines compared to using other languages.
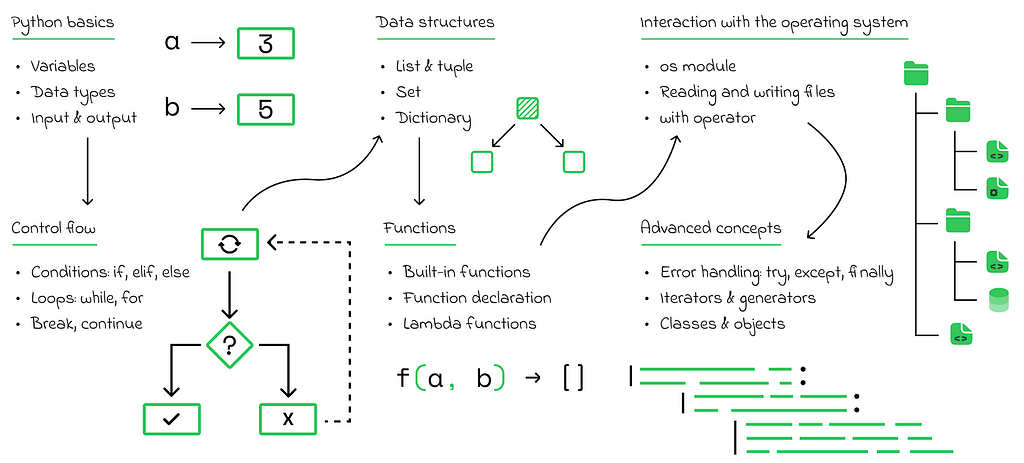
The Python roadmap for beginners does not contain anything particularly unique, and, aside from certain Python-specific concepts, it would be very similar to the roadmap for any other programming language.
# 02. Algorithms and data structures
Data is like fuel; it is what essentially drives data science. Given that, there are numerous ways to process and handle data. But why should we care about them? Treating data inefficiently is like using the wrong type of fuel for a car. While the final objective can still be achieved with improper tools, it can come at significant costs, such as high computational overhead or excessive memory usage. Consequently, the entire system may fail to scale effectively.
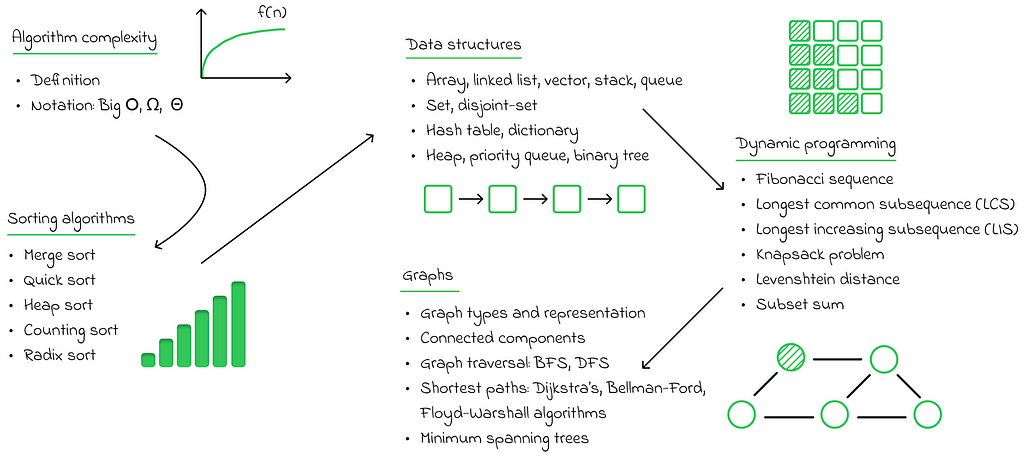
Algorithms and data structures is all about using correct tools in different circumstances. More specifically, data structures define ways to store data and perform standard operations on it while algorithms focus more on diverse manners to treat it for solving concrete problems.
In this area, there are several important topics to study. First and foremost is the Big O notation, which is widely used to estimate the overall complexity of algorithms. Using time as a metric for measuring algorithm performance is not ideal since the same algorithm can behave differently in various environments. For example, it may run quickly on a powerful computer but slowly on a computer with fewer CPU cores. Additionally, execution time also depends on the input data parameters.
For these reasons, the Big O notation was developed. It measures algorithm complexity as a function of the input parameters, considering performance in a theoretical limit. The advantage of this approach is that each algorithm has a single level of complexity, regardless of the external conditions under which it is executed.
Secondly, there are sorting algorithms, which play a fundamental role as they are frequently applied in practice and often serve as building blocks for many other algorithms. I would suggest that knowledge of the five most popular sorting algorithms is a good starting point. Personally, I would strongly recommend learning about merge sort, as it introduces the important “divide and conquer” paradigm, which is widely used in many other algorithms. Additionally, quicksort is worth studying, as it is known to be one of the most efficient sorting algorithms in practical applications.
The next step consists of learning classical data structures. Doing so will make it much easier to select the most efficient data structures for everyday problems or even design your own, based on the valuable knowledge you have gained.
In my experience, the best way to deeply understand data structures is to manually implement them yourself without relying on any external tools or libraries.
Dynamic programming is a powerful technique that involves solving a problem by recursively breaking it down into smaller subproblems. By storing the results of these solved subproblems, the algorithm can reuse them to find the solution to the original problem using recursive relationships between the subproblems. In my opinion, dynamic programming is one of the most challenging topics in algorithms, but it also provides extremely efficient solutions to problems that would otherwise require iterating through all possible solutions, often resulting in exponential or even factorial complexity.
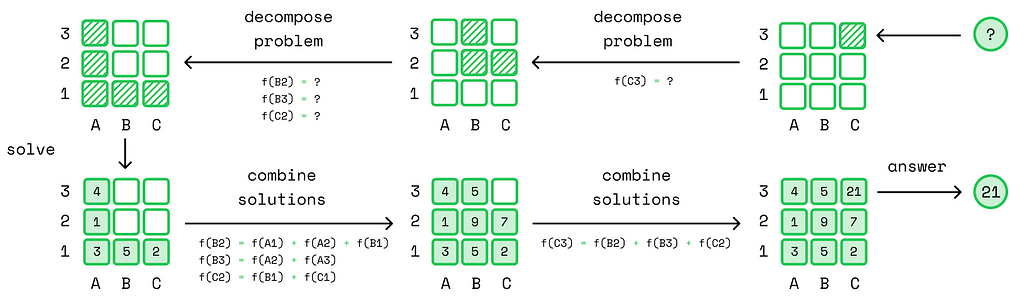
The final chapter in the algorithms section that I recommend beginners focus on is graphs. I have already highlighted the importance of graphs in part 1 of this series when discussing discrete mathematics. However, when it comes to algorithms, I want to emphasize their importance from an implementation perspective. While understanding the fundamental concepts of graphs is a crucial aspect of discrete mathematics, applying them effectively in real-world applications is a completely different challenge, one that comes with its own set of complexities and pitfalls.
# 03. Object-oriented programming
There are various paradigms for writing code. The two most commonly used paradigms today are procedural and object-oriented programming. Simply put, the procedural paradigm involves using functions as the main building blocks to organize code. While this approach was highly popular in the past, it has become less prevalent as more convenient and versatile paradigms have emerged.
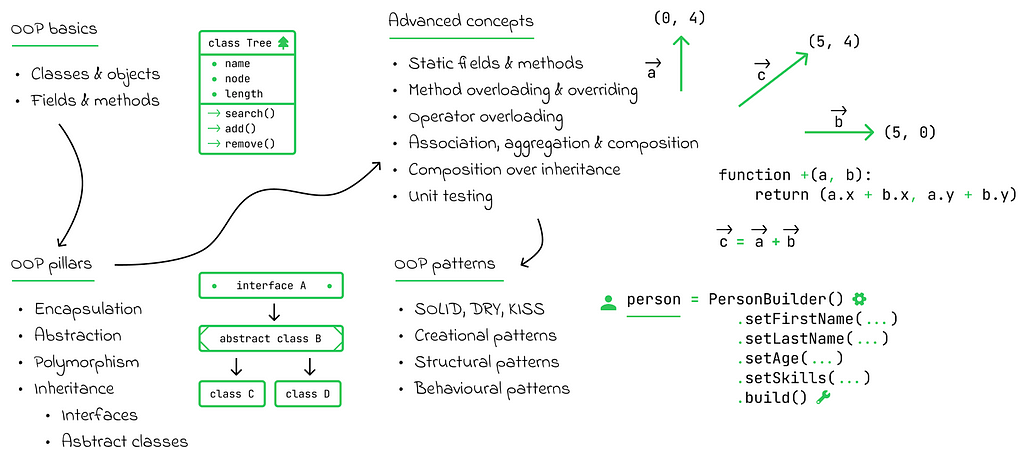
In contrast, the object-oriented paradigm takes a step further. It involves representing code entities as objects that can interact with one another or have various relationships. These objects are defined through classes, which serve as general templates and may contain a combination of basic fields and / or other objects. Additionally, objects can exhibit behavior through methods (or functions) implemented within the classes.
One of the advantages of object-oriented programming (OOP) is its natural correspondence between objects in code and how those objects are perceived by humans in real life. Additionally, it is easy to reuse classes and objects, making the code more maintainable.
OOP is built on three crucial pillars: inheritance, polymorphism, and encapsulation. While we will not delve deeply into these terms here, they can be summarized as providing additional functionality to further reuse existing code within classes while ensuring its safe and consistent usage.
# 04. Databases
To be used efficiently, big data is stored in databases. Databases themselves automatically provide several functional layers, which may include security configurations, transaction management, read and write optimization, administrative settings, and many other features.
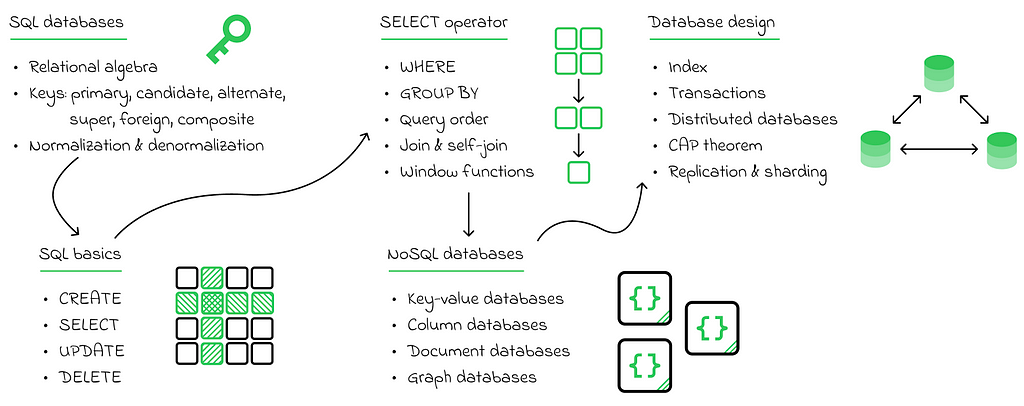
For data scientists, the most common use cases involve are database creation, reading data from them, and writing data to them. Before exploring specific technologies, it is important to distinguish between two types of databases: relational (SQL) and non-relational (NoSQL).
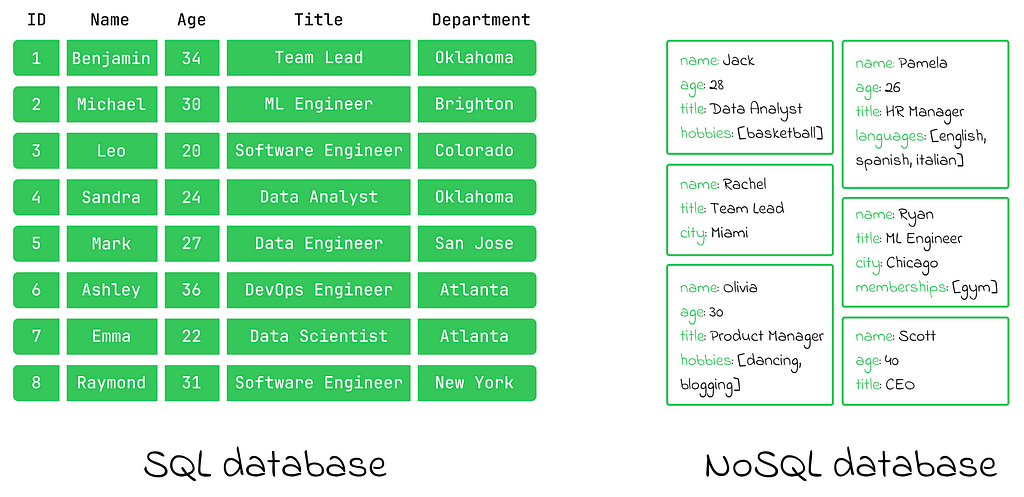
In simple terms, relational databases organize data strictly in a tabular format, similar to how humans typically organize information in the real world. On the other hand, non-relational databases are less rigid and impose fewer constraints on data organization. As a general rule, both SQL and NoSQL formats have their own advantages and disadvantages.
For beginners, I believe it is essential to focus heavily on the SQL language. SQL is the standard language used for managing almost all relational databases. Specifically, a data scientist is expected to know how to perform the CRUD operations: create, read, update, and delete data in tables. While the CREATE, UPDATE, and DELETE commands are relatively straightforward to use in SQL, the SELECT command likely plays a much more critical role. SELECT is widely used in practice and offers numerous ways to retrieve the necessary data efficiently.
It does not matter much for learners which relational database they use to master SQL, as they all have a lot in common. However, the most popular options are MySQL, PostgreSQL, and Microsoft SQL Server. When it comes to non-relational databases, I would advise beginners to experiment a little with one or two of them (e.g., MongoDB, Neo4j, Redis, etc.) to understand their fundamental differences compared to relational databases.
# 05. Web development
Web development is not directly related to data science, but it is still a very useful skill to have. While being able to construct a smart predictive model is valuable, presenting it through a visually appealing interface is a big bonus. This is especially important in start-ups, where a single machine learning engineer may be expected to handle cross-platform tasks and develop the model at different stages of its lifecycle.
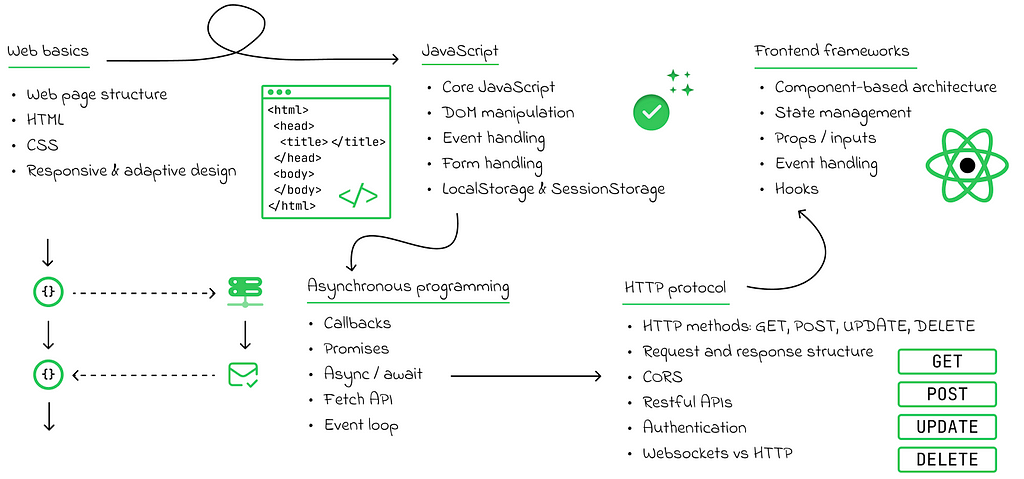
Moreover, by understanding the structure of an HTML page and how the web works in general, you can perform web scraping by automatically creating scripts that parse information from web pages. This information can then be used, for example, to train models.
Finally, solid web knowledge enables you to make external API calls to other services. This is especially important in the modern era with powerful LLMs like ChatGPT, Mistral, or Llama.
In general, obtaining a basic understanding of web development is a relatively achievable goal. To get started, you should learn:
- HTML, which is used to construct the main structure of web pages.
- CSS, for making the interface more stylish and responsive.
- JavaScript, to add dynamic interactions and animate websites.
- HTTP protocol and how to make API requests using JavaScript.
- One of the classic frontend frameworks (React, Vue, or Angular) to accelerate the development process.
With this knowledge, a data scientist should feel confident in performing basic web-related tasks at work.
# 06. DevOps
DevOps is another branch of software engineering that focuses on development optimization. Generally, DevOps engineers create tools, pipelines, and environments with the goal of automating routine tasks for software engineers. This allows developers to focus more on creating necessary product features and less on deployment.
Nevertheless, there are some important DevOps tools that data scientists should be aware of which are discussed below.
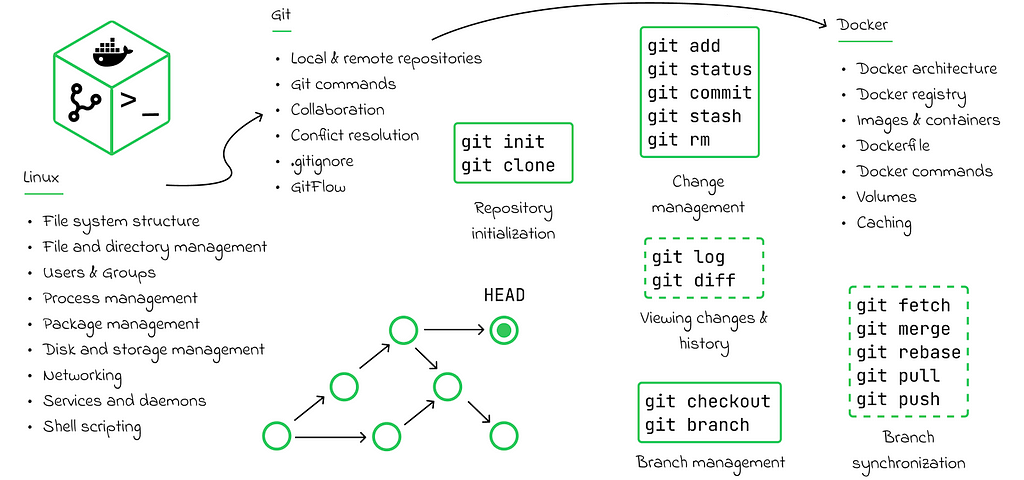
In the vast majority of enterprises, Linux is used as the main operating system for application development and deployment. For this reason, it is common for developers to use the Linux command line in their daily routines. Examples of such tasks include navigating through a directory structure, changing file permissions, managing processes, executing scripts, and sending or receiving data from remote servers. All of these tasks are performed using Bash.
Bash is a scripting language used in Linux. It has a lower-level syntax compared to other programming languages (like Python) and may not be as convenient to use, but it still provides a lot of useful functionality for managing operating system tasks and state. In most cases, for data scientists, knowing basic Bash commands is sufficient to perform the tasks listed in the previous paragraph.
By the way, Git is an essential tool to master. It allows for version control of the entire codebase. By using commits, a developer can easily roll back to a previous version of the code if something goes wrong with the current one. Additionally, Git is a collaboration tool that enables developers to work on multiple features of a project simultaneously using branches, and ultimately merge all the changes together.
When learning Git, it is also beneficial to get hands-on experience with a cloud version control system (VCS). The most popular ones are GitHub, Bitbucket, and GitLab. Personally, I would recommend using GitHub, as it is the most widely used. With a cloud VCS, developers can publish their code to a central repository, making collaboration easier. They can also create issues, use Kanban boards, write comments, and organize pull requests to merge changes.
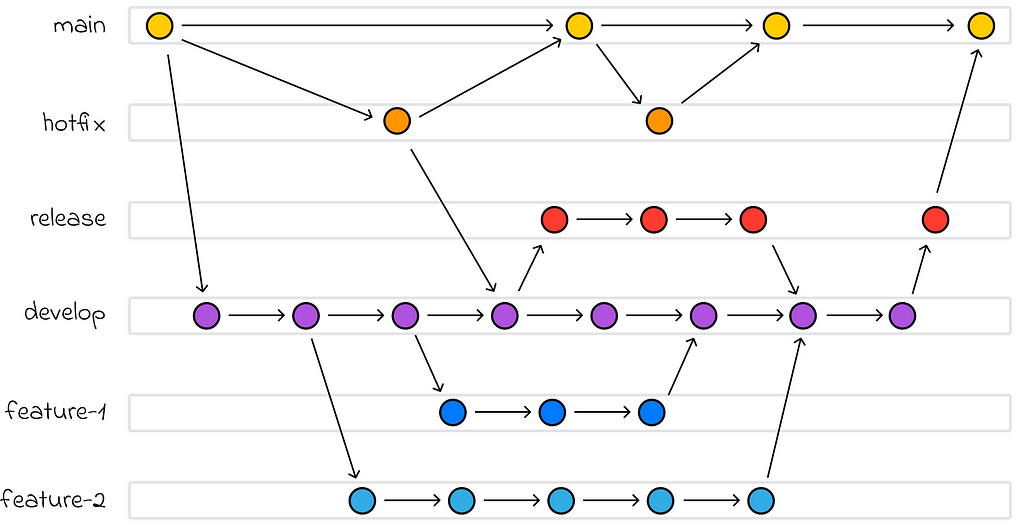
For more effective collaboration, it is also important to be familiar with the most common workflows when using Git. One of the most popular workflows is GitFlow, which defines several types of branches and the rules for how they should be managed.
Finally, another important tool is Docker, which is used for application containerization. Every application, when deployed, requires a unique set of dependencies that may demand specific versions or properties of the operating system where the application runs. To avoid compatibility issues, Docker comes into play.
By being compatible with various operating systems, Docker isolates the application in a separate environment and acts as an adapter between the system and the application, allowing all necessary dependencies to be downloaded. As a result, the same application can run within the Docker environment on different operating systems.
# Extra. Data formats
While many other roadmaps might not mention data formats, I believe it is important for beginners to be aware of the different ways data or other configuration files can be represented. The most common formats are displayed below:

Conclusion
In this article, we have identified the crucial engineering skills that aspiring data scientists need to master first. In general, data science is a very broad field and requires a diverse skill set from engineers. By gaining a solid foundation in engineering, machine learning development becomes much more accessible.
In my experience, learners should focus not only on understanding theoretical programming concepts but also on gaining hands-on practice. One of the best ways to hone programming expertise is to complete pet projects that combine recently learned skills.
In the next article, we will discuss the necessary machine learning knowledge for data scientists, which, in its turn, already requires a strong knowledge in both mathematics and development.

All images are by the author unless noted otherwise.
Roadmap to Becoming a Data Scientist, Part 2: Software Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/upBc7wq
via IFTTT


