
The Good, the Bad, An Ugly Memory for a Neural Network
|ARTIFICIAL INTELLIGENCE|MEMORY|NEURAL NETWORK|LEARNING|
The Good, the Bad, and the Ugly: Memory for a Neural Network
Memory can play tricks; to learn best it is not always good to memorize

No man has a good enough memory to be a successful liar. — Abraham Lincoln
Memory is more indelible than ink. — Anita Loos
Memorize bad, generalization good. This is considered as a dogma of artificial intelligence. But why? What is wrong with memorization?
Intuitively a student who memorizes the whole book might still fail a test if the exercises are different from those in the book. If memorizing does not mean learning, sometimes a little memory can also be beneficial. For example, there is no point in learning complex rules to learn a list of names of historical figures. You have to know how to find the right balance. Something similar is happening with neural networks. This article discusses the complex love/hate relationship between neural networks and memory.
Artificial intelligence is transforming our world, shaping how we live and work. Understanding how it works and its implications has never been more crucial. If you’re looking for simple, clear explanations of complex AI topics, you’re in the right place. Hit Follow or subscribe for free to stay updated with my latest stories and insights.
A complex relationship between memory and learning
In general, neural networks and memorization have a complicated relationship. Neural networks tend to learn shortcuts or simple rules that are good for most of the data. Examples that fail to fit into these rules are considered exceptions by the model. These shortcuts can be a way to speed up training and quickly optimize loss, though, they often have unintended effects. For some authors [1], this is why neural networks are capable of extraordinary performance and spectacular failures at the same time:
One central observation is that many failure cases are not independent phenomena, but are instead connected in the sense that DNNs follow unintended “shortcut” strategies. While superficially successful, these strategies typically fail under slightly different circumstances. — source

In short, neural networks try to learn simple features at the expense of complex ones, even when the latter have greater predictive power (making the networks nonrobust). This also makes neural networks fail to produce a reliable confidence estimate and often arrive at suboptimal generalization [3].
Some of it is not even their fault. Training techniques such as gradient descent, regularization, large learning rate, and small batch size favor less complex models [4]. This is because complex models usually mean overfitting (i.e., the model memorizes patterns in the training data that are not useful for generalization). Less complex models should learn general rules that go beyond the training data. At the same time, reducing complexity favors learning heuristics. Heuristics, even if they are wrong, are good for most data (they are simple features or rules that the model can use for most data), and thus are favored in training.
The neural network generally has enough parameters to memorize the entire dataset [5]. On the one hand, it might memorize the dataset, on the other hand, the training process pushes it to simple solutions. The result is that the network learns simple solutions valid for most of the dataset and memorizes the exceptions.
Why is this dangerous?
Looking at the stars in the night it is easy to conclude that they are the ones orbiting the earth. An earth-centric model could explain almost all celestial bodies, with a few notable exceptions. The Ptolemaic model used hemicycles to explain the exceptions and the rest was explained by a simple rule.
Neural networks do the same: they look for a simple rule, and once found the rest becomes an exception. When these simple rules are spurious correlations this becomes a serious problem. For example, many of the neural networks designed for diagnosis fail because they learn about spurious correlations and use them for predictions [6]:
The neural network that famously had reached a level of accuracy comparable to human dermatologists at diagnosing malignant skin lesions. However, a closer examination of the model’s saliency methods revealed that the single most influential thing this model was looking for in a picture of someone’s skin was the presence of a ruler. — source
The presence of the ruler means that the dermatologist has already identified a cancerous lesion and therefore the model is useless.
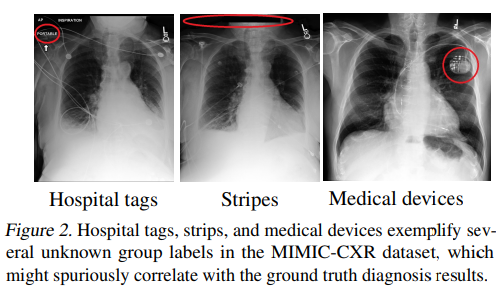
However, it is not always so easy to diagnose when a neural network has learned spurious correlations. In this case, we may have a false sense of reliability of the neural network. Therefore, it is critical to understand whether a model that has achieved near-perfect accuracy has learned generalizable patterns or uses spurious correlation and memorization.
So there are several questions:
- How to monitor the model’s generalization abilities? How to identify spurious correlations?
- When do these spurious correlations impact training?
- How can we correct this behavior?
The Savant Syndrome: Is Pattern Recognition Equivalent to Intelligence?
The quest for spurious correlation
A model’s ability to generalize is evaluated on a held-out set. Typically, the test set is a part of the dataset that the model does not see during training. So it is critical to avoid any data leakage or this evaluation will not be useful.
Spurious correlation refers to relationships between variables that appear to be statistically significant in the data but are not genuinely causal or reflective of a true underlying relationship. These patterns are generally present only in the training set but not in new or unseen data. This especially occurs if the training set is biased or does not represent the true distribution of the data
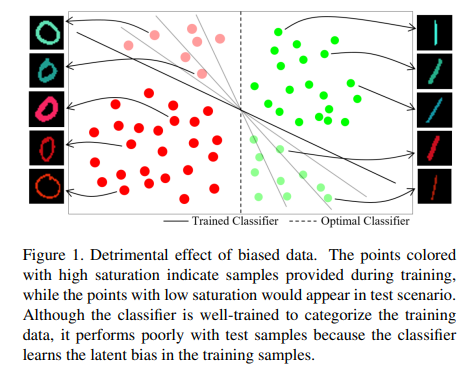
In general, it is assumed that during the initial training phase, the models learn these spurious correlations and memorize the examples. Only in the second stage does true generalization occur.
Grokking: Learning Is Generalization and Not Memorization
Therefore different studies have tried to exploit this fact to create automatic systems to identify spurious correlations. These approaches then look for patterns that occur learned early on or that are too simple to solve a complex problem [9–10]:
Based on this observation, we are skeptical of very simple solutions to complex problems and believe they will have poor o.o.d. generalization. — source
Because shortcuts are simple and easily learned, small patterns can be used to identify them. Other methods try to correct the loss function to identify and eliminate these correlations [11].
The impact of spurious correlation
Spurious correlations reduce a model’s ability to generalize. In itself this is bad, but it is usually diagnosable because the model will perform sub-optimally. In the presence, of spurious correlation,n a model first learns patterns that are useful for most examples. Once it achieves near-perfect accuracy on the majority examples, it begins to learn the minority examples [2]. In the classification case, this means that the model learns a decision boundary that is not optimal but is still predictive.
If the model has enough parameters or in another situation where memorization is possible, the model will learn the minority examples by heart. This will cause the model to focus on learning the examples and no longer try to learn true core features.
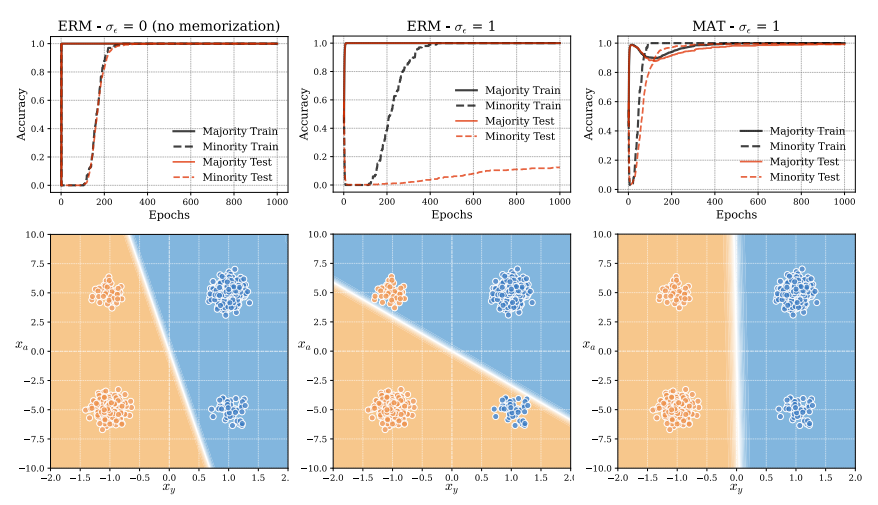
Neural networks can exploit spurious features and memorize exceptions to achieve zero training loss, thereby avoiding learning more generalizable patterns. However, an interesting and somewhat controversial question arises: Is memorization always bad? — source
Not necessarily. The model may lead to memorization, but it may not affect generalization. It all depends on the nature of the data and the dynamics of the training. In general, we can have three cases [2]:
- Good memorization. The model learns the true function underlying the data but also memorizes some residual noise in the training data. This type of memorization is benign because it does not compromise generalization. This phenomenon is also referred to as benign overfitting, where the model overfits the training data but still manages to generalize to unseen data.
- Bad memorization. The model relies more on example-specific features than on true function; this reduces the learning of generalizable patterns and suboptimal performance.
- Ugly memorization. The model goes into overfitting, learning a nonlinear and complex function that does not, however, serve to generalize.
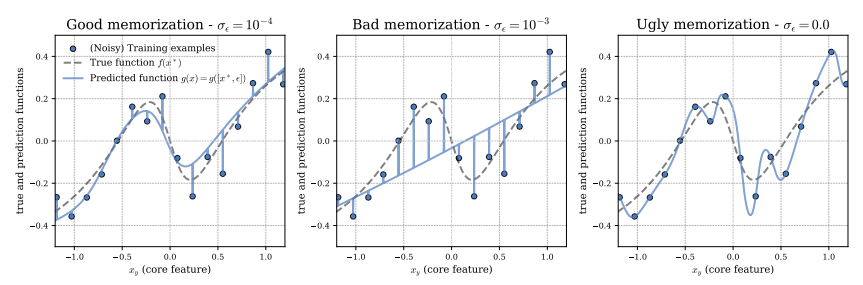
Thus, memorization reduces the network's generalization capabilities. The examples that are stored by the network are either exceptions or outliers. This in itself can lead to reduced performance (more or less severe), but it is generally not enough for catastrophic drops. When the model learns spurious correlations (patterns that do not reflect the true underlying function of the data) and memorizes them, this is a recipe for disaster. The model relies on spurious correlations for predictions and memorization for the rest.
- Open the Artificial Brain: Sparse Autoencoders for LLM Inspection
- Through the Uncanny Mirror: Do LLMs Remember Like the Human Mind?
How can we solve this problem?
Clearly, it is not easy to identify memorization phenomena during training. memorization can be identified when the model is tested on the test set. Based on this assumption in [2] they proposed Memorization-Aware Training (MAT) to address the problem of memorization in neural networks.
MAT seeks to identify memorization behaviors and use them to guide the training process. To do this it uses predictions on held-out data (data that are kept aside to make these predictions). This approach encourages the model to modify its output by adjusting the logits (the model’s raw predictions) to be less sensitive to memorized data points. Then we use the validation set (or another data set that is not used for training) to identify whether there is any storage.
If the model shows a low error on the training set but has a high error on this held-out set, the model is probably memorizing more than learning generalizable patterns. If memorization occurs, MAT discourages this phenomenon by adding a regularization term to the loss function (regularization prevents the model from fitting too close to the data and thus tends to memorize it).
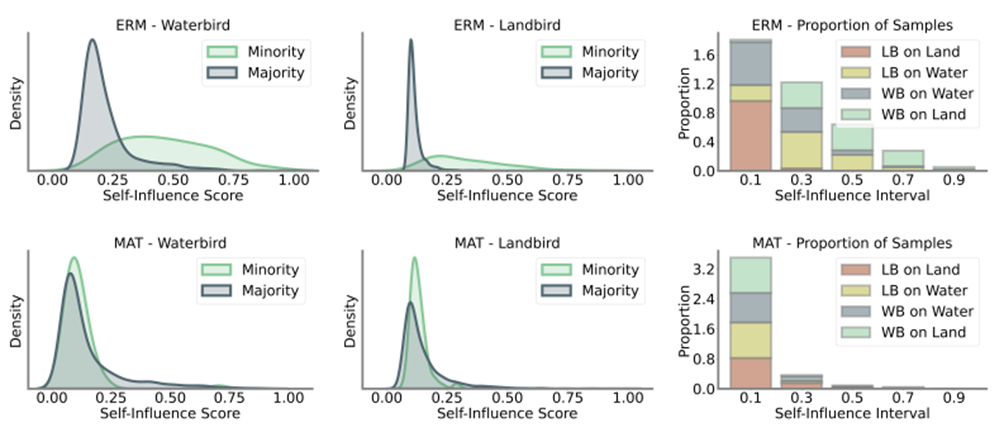
The authors [2] define a self-influence score as a measure used to identify which data points the model has memorized during training. This provides insight into the extent a prediction for a data point is influenced by the same data point. Intuitively, if the prediction for an example is influenced by itself, it means that the model has memorized it rather than predicted it using general rules.
Mathematically, this self-influence score is calculated by how much a model’s loss function changes when the data point is perturbed or removed. If the sef-score is high, the model is sensitive to that data point and might be overfitting or memorizing it. In contrast, a low score suggests that the model learns general rules and is not overly specific to any one example. The authors show that for minority classes the model trained with classical gradient descent shows a high self-influence score and thus memorization. This behavior is corrected when using the MAT algorithm
Parting thoughts
Learning is different from memorizing. Real learning is understanding some general rules and learning how to apply them to solve a problem. Any student learns some formulas by heart before an exam. In itself, this is not ideal, but this does not mean that a student will fail an exam. He may, however, do exercises that he cannot answer since he will apply these formulas without really understanding.
For neural networks, it is the same, if the model learns generalizable patterns and memorizes only a few examples its performance will be mildly affected. On the other hand, the model might learn spurious correlations and store exceptions that do not fit these patterns. Spurious correlations are easier to learn because they represent simple solutions to complex problems. Neural networks try to optimize loss as quickly as possible, and heuristics help in this aim. Having enough parameters, neural networks can memorize the rest of the examples and achieve a perfect loss on the training data. After that, they will fail spectacularly on unseen data.
Identifying which examples are stored and which learned patterns are spurious correlations during training is not an easy task. Being able to identify memorization phenomena during training allows this behavior to be corrected. Since this phenomenon can be identified when testing the model on a test set, we can use a held-out set. In [2] they do exactly that, they use a held-out set to identify storage phenomena and correct the direction of training using regularization.
Neural networks have a tendency to memorize. The more parameters they have, the greater the risk that they memorize examples. Large language models (LLMs) have a huge of parameters and can hold a huge amount of data in memory. The relationship between memory, spurious correlation, and LLMs is not yet fully understood. There seems to be a balance between storing training data and learning generalizable patterns [13–15]. This remains an intriguing prospect for future study.
What do you think? Have you ever observed storing or spurious correlation? Let me know in the comments
If you have found this interesting:
You can look for my other articles, and you can also connect or reach me on LinkedIn. Check this repository containing weekly updated ML & AI news. I am open to collaborations and projects and you can reach me on LinkedIn. You can also subscribe for free to get notified when I publish a new story.
Get an email whenever Salvatore Raieli publishes.
Here is the link to my GitHub repository, where I am collecting code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
- A Memory for All Transformers: Sharing to Perform Better
- From Solution to Problem: The Reverse Path to Smarter AI
- You’re Not a Writer, ChatGPT — But You Sound Like One.
- The Cybernetic Neuroscientist: Smarter Than Experts?
Reference
Here is the list of the principal references I consulted to write this article, only the first name for an article is cited.
- Geirhos, 2020, Shortcut Learning in Deep Neural Networks, link
- Bayat, 2024, The Pitfalls of Memorization: When Memorization Hurts Generalization, link
- Shah, 2020, The Pitfalls of Simplicity Bias in Neural Networks, link
- Dherin, 2022, Why neural networks find simple solutions: the many regularizers of geometric complexity, link
- Zhang, 2016, Understanding deep learning requires rethinking generalization, link
- Roberts, 2021, Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans, link
- Kim, 2019, Learning Not to Learn: Training Deep Neural Networks with Biased Data, link
- Li, 2019, REPAIR: Removing Representation Bias by Dataset Resampling, link
- Dagaev, 2021, A Too-Good-to-be-True Prior to Reduce Shortcut Reliance, link
- Nam, 2020, Learning from Failure: Training Debiased Classifier from Biased Classifier, link
- Liu, 2023, Avoiding spurious correlations via logit correction, link
- Ye, 2024, Spurious Correlations in Machine Learning: A Survey, link
- Carlini, 2022, Quantifying Memorization Across Neural Language Models, link
- Schwarzschild, 2024, Rethinking LLM Memorization through the Lens of Adversarial Compression, link
- Wang, 2024, Generalization v.s. Memorization: Tracing Language Models’ Capabilities Back to Pretraining Data, link
The Good, the Bad, An Ugly Memory for a Neural Network was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/HRXf28l
via IFTTT


