
Preparing PDFs for RAGs.
I created a graph storage from dozens of annual reports (with tables)

Converting PDFs to text was possible but has never been easier.
I recently created a graph data store to be used in an RAG. In other words, we built a GraphRAG.
How to Build a Knowledge Graph in Minutes (And Make It Enterprise-Ready)
Graph RAGs are a fantastic alternative to other RAG apps like widely used vector store-backed RAGs. They bring reasoning to the table. For example, with semantic similarity search (the technique used in vector stores to retrieve information), you could ask who the CFO of XYZ, Inc. was last year. Because XYZ, Inc.’s last year’s annual report would explicitly mention its CFO. But think of a question like this: Which two directors of XYZ, inc. have studied in the same school? The retrieval process won’t be able to fetch the relevant information without mentioning a school name. But graph RAG could do it.
However, the key issue here is how we construct the graph for retrieval. I’ve addressed this issue in a separate post recently. Thinking another step backward, how do we even prepare the annual reports in a way that makes it easier to create the graphs?
That’s the focus of this article.
The first engineering step of all our work is converting data from PDFs to text. However, annual reports are complex documents. There won’t be just text. There’ll be charts, tables, etc. Each provides a vital piece of information about the company.
So, let’s start from there.
How to convert PDFs to rich text
Most Python programmers would have used PDF readers at some point — at least to follow along with a tutorial. The most popular one was PyPDF2.
Most of these libraries do get the job done. But the helpfulness of the information was not great.
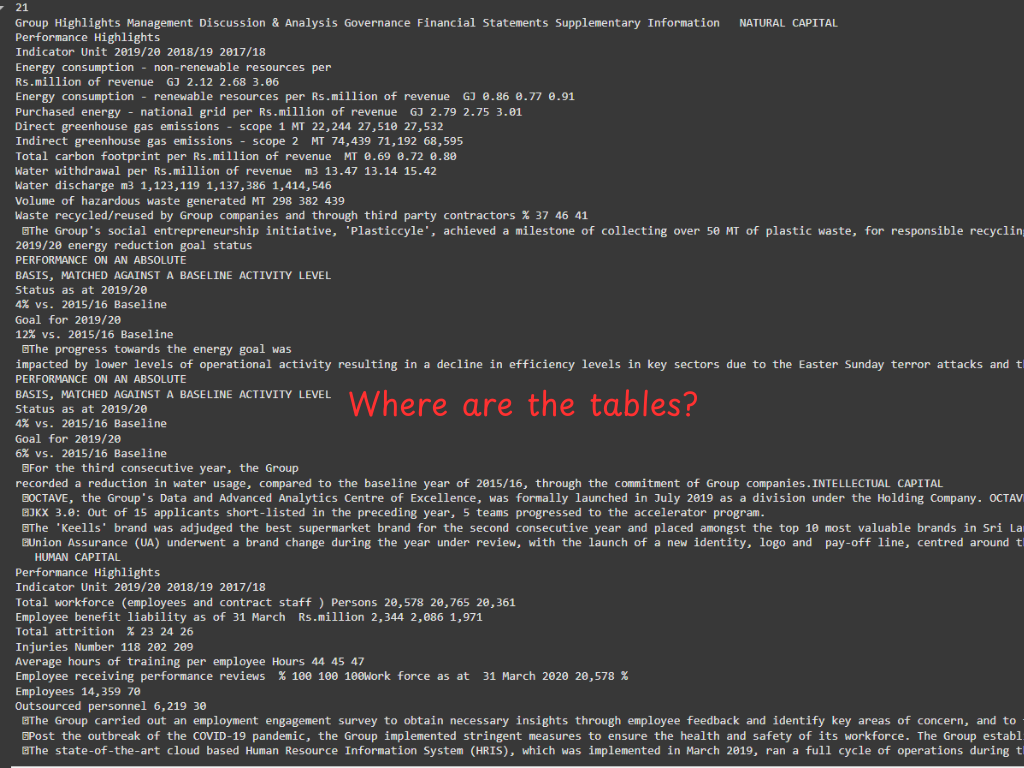
The PyPDF2 library, which I have known about for years, extracts all your PDF content as text without any formatting. After extraction, you have no idea which is the title and which is a list.
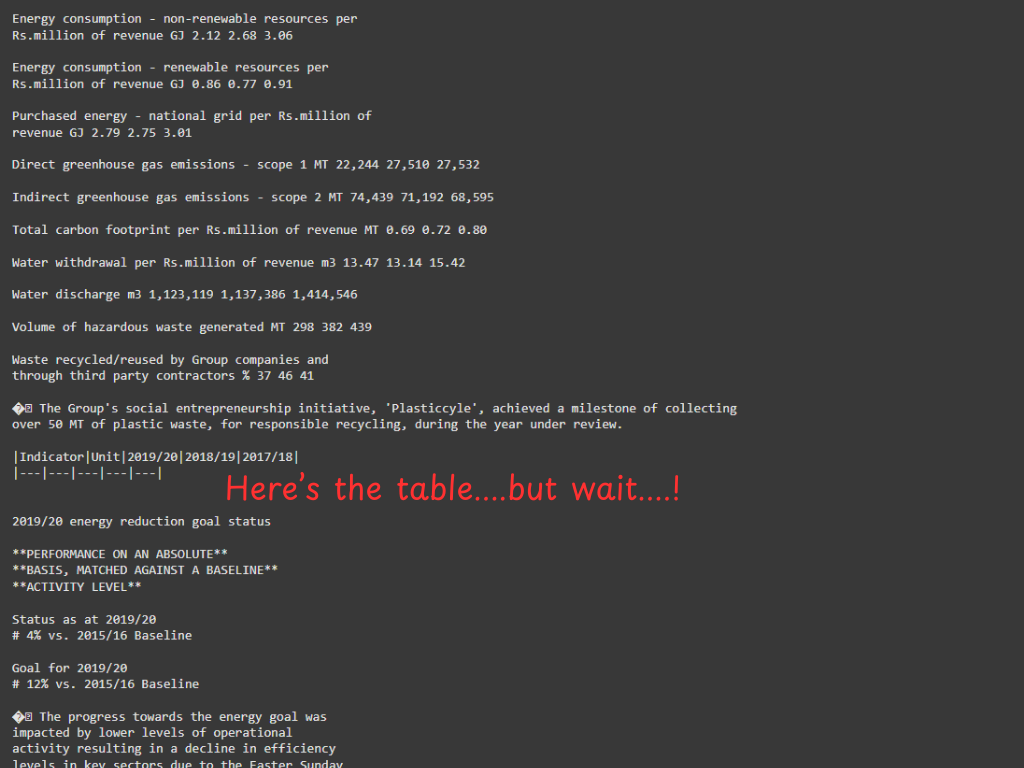
Then there was PyMuPDF4LLM. This package converts the PDFs directly to markdown. Markdown also has a lot of crucial information on the structure of the text. Frameworks like Langchain support markdown. They use the extra information in the text formatting to better chunk and store the data in data stores. This, in turn, makes fetching relevant data more easier.
The issue with PyMuPDF4LLM was that it didn’t do well with tables. The extracted tables were not anywhere near the original. (Don’t ditch PyMuPDF4LLM yet. It still played an incredible role in our final solution)
Lastly, we tried a couple of other modern tools. One is Docling, a library developed and open-sourced by IBM Deep Search, and the other is the Marker, an equally fantastic library.
Here are the outputs of the same PDF page converted by the four packages we’ve discussed.
PyPDF2:
PyMuPDF4LLM:
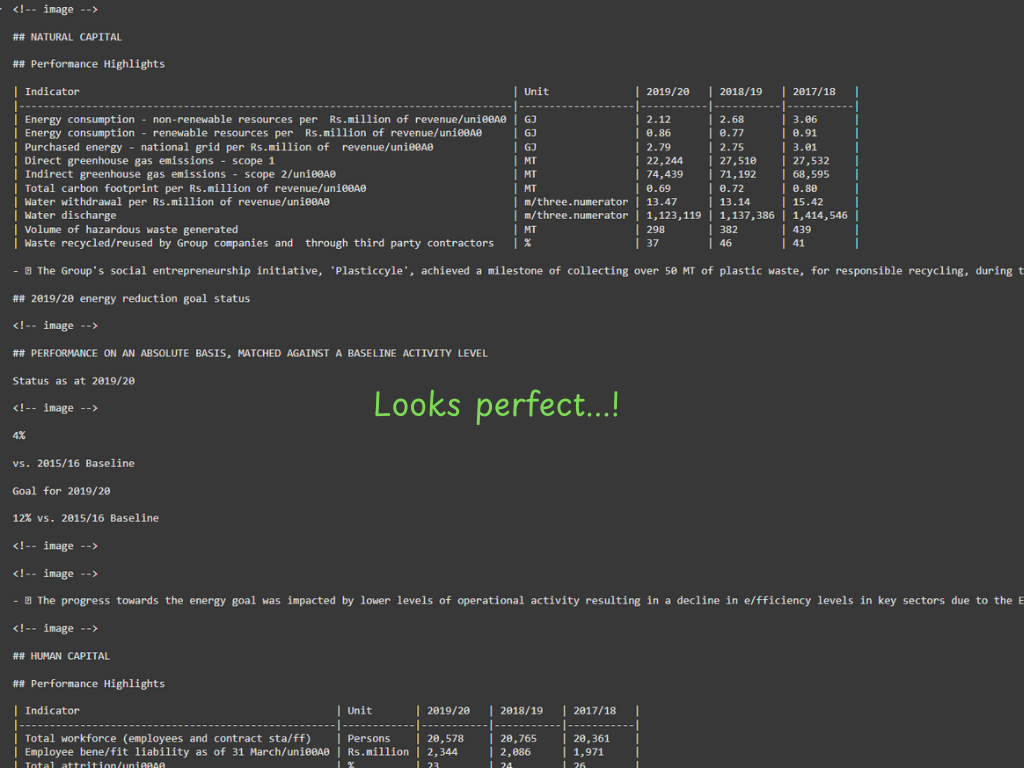
Dockling:
Marker:
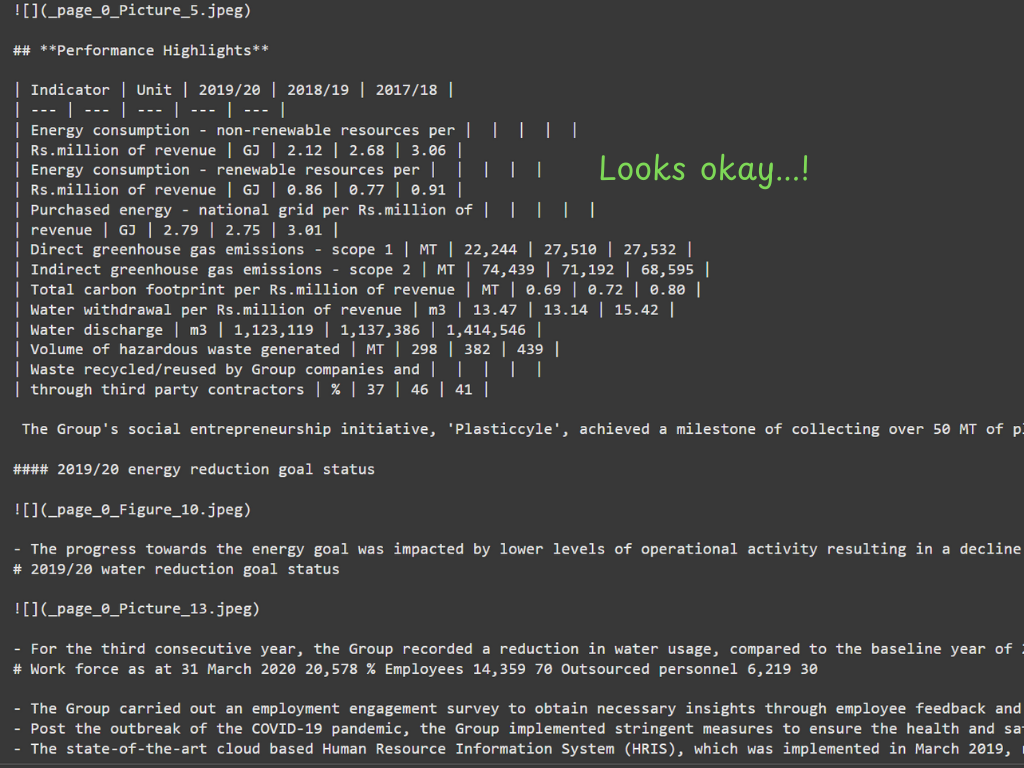
The Dockling version is more neat and has more structural information than the other two. It has extracted the tables with all the relevant information. It has left placeholders for images and preserved the hierarchical heading structure. All this information helps create chunks, graph db, better retrieval, and, eventually, a better RAG system.
What didn’t work well?
Marker and docking are both promising. However, I’m not very impressed if we take the time to convert PDFs to markdown.
To test this correctly, I partitioned a segment of an annual report that includes a mix of text, tables, and images. I then created several copies of this with different page counts.
I then ran the conversion with each tool for these different-sized PDF files and measured the time they took. Here’s the final result.
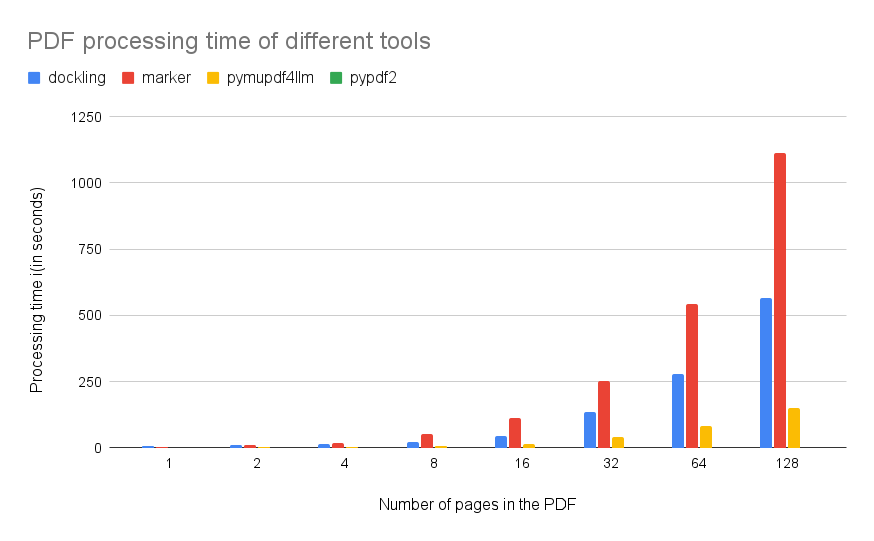
The result clearly shows that Dockling and PyPDF2 are way too slow compared to the other two options despite their impressive abilities to convert tables.
Dockling processes a single PDF page in roughly 4 seconds, while Marker takes about double that time.
What did I do?
How to pick the best PDF to markdown tool
Our project had dozens of annual reports. Thankfully, they aren’t hundreds.
If each annual report is approximately 300 pages long and there are 50 reports using docking, we need 17 hours (300 pages per report x 50 reports x 4 seconds per page / 3600 seconds per hour).
Therefore, we could afford the time.
But we’re still in the prototyping phase. We need to think about scaling up the project. What if this project scales to all the S&P500 companies and their 30-year historical reports?
Unless we distribute the load and do it in parallel, it will take 208 days, which is precisely what we did.
We created a service that handles conversions in the cloud and updates the Graph DB. This can run in parallel and scale up nicely.
If speed is your concern, PyPDF2 is the best — that is if you can’t run Dockling in parallel processes.
Final thoughts
PDF to markdown tools have gotten better. But converting tables on PDF to markdown tables wasn’t very good still.
We’ve compared four free and open-source tools for converting PDFs to Markdown. Then, we chunked the markdowns and converted them to graphs in an RAG app.
Of the tools we compared, Dockling produced outstanding results. The downside, though, is its performance. It takes much longer than the widely used PyPDF2.
Therefore, we switched to a cloud service that scales up nicely and does the conversion in parallel.
Thanks for reading, friend! Besides Medium, I’m on LinkedIn and X, too!
Preparing PDFs for RAGs. was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/6WYzJlX
via IFTTT


