
Top 3 Questions to Ask in Near Real-Time Data Solutions
Questions that guide architectural decisions to balance functional requirements like most frequent queries with non-functional requirements such as latency and scalability.
Introduction
Would you agree that our life is surrounded by technology nowadays? Technology has changed our lifestyle in all kinds of ways in the past decade. Behind the scene, data is the core to almost every technology. In our everyday life, for example, e-commerce platforms make personalized product recommendations by tracking our user behavior, and IoT systems like thermostats in our house collect data to smartly adjust temperature settings. This means a massive amount of data needs to be collected and processed constantly. How do we handle such large amounts of data in a real-time or near real-time manner? One key challenge is to design efficient and scalable data solutions.
Let’s explore a few common scenarios before we dive into their challenges:
- Log Analytics: Monitoring application logs, such as web request HTTP status codes, system metrics like CPU usage, and application error events. Some example data queries can be “What are the top 10 error codes logged in the past 24 hours”, “What are the CPU usages across all servers over the past week”.
- Time-Series Analytics: Processing time-stamped data for insights, such as Internet of Things (IoT) sensor readings. An example query can be “What are the temperature readings in the warehouse X fridge #2 over the past 24 hours”.
- Social Media and Sentiment Analysis: Analyzing social media data, such as tweets or comments, to understand sentiment and trends. A concrete query can be “What are the top 3 trending hashtags in the past hour”.
The above scenarios all require near real-time data solutions, which means streaming data ingestion, low latency query response, in addition to high scalability in order to handle the growing volume of data.
Achieving these requirements is not a small ask. It requires balancing functional requirements, like the ability to query specific data, with non-functional requirements, such as low latency, high scalability, and availability. Any wrong design decisions can lead to bottlenecks, unnecessary costs, or even system failures down the road. Who would want a 2am phone call while being on on-call duty… This is why asking the right questions during the initial design phase becomes essential.
In this blog post, I am addressing the Top 3 Questions that I personally think should be systematically looked at. My goal is by the end of this blog, you will be better equipped to design a near real-time data solution that meets both functional and non-functional needs.
The 3 Questions to Ask
Before we dive into the details, let’s outline the top 3 questions at the high-level.
- What storage mechanism best suits our workload?
- How do we make the queries efficient?
- How do we handle the growing data volume?
Another question that did not make the top 3, but is a great candidate: How will you integrate visualization and analytics into your overall design?
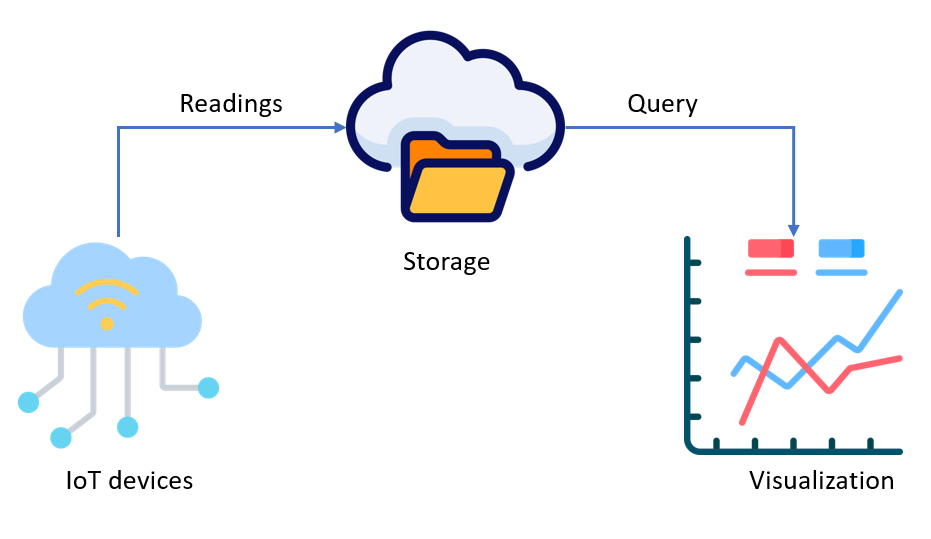
These are very open questions. Let’s explore a concrete example to make these questions more concrete. IoT solutions can be an ideal candidate for demonstration purpose, because the business logic is relatively straightforward and the solution must handle vast amount of data in real-time.
IoT Data Solutions: A Real-World Use Case
In an Internet of Things (IoT) data system, many devices constantly transmit data to a centralized storage. The system must handle high ingestion rate, and also handle time-series queries efficiently, regardless of the growing number of devices or growing volume of data, i.e., high scalability. These might sound daunting, but the business logic is relatively straightforward. For demonstration purpose, let’s review the data modeling strategy in a simplified manner.
Data Modeling
At the heart of an IoT solution is a simple data model. Typically it consists of at least three fields:
- Device ID: A unique identifier for each IoT device, such as a thermometer or motion sensor.
- Timestamp: The exact time when a reading is recorded.
- Value: The reading itself, such as a temperature reading or humidity percentage.
A common query is to retrieve readings for a specific device for a specific time period. The equivalent query using SQL syntax is:
SELECT DeviceId, Timestamp, Value
FROM IoTReadings
WHERE DeviceId = 'abc'
AND Timestamp > DATEADD(hour, -1, GETDATE());
Storage mechanism
The first question we want to ask is where to store our data. While comparing and picking the best data storage mechanism, we will naturally also think about our IoT data access patterns (heavy writes, spiky reads) and how the storage option helps us handle query performance.
Choose the Right Data Store
For IoT use cases, we need a data store optimized for heavy writes and time-series analytics. On the market, some prime options include:
- SQL database, such as Azure SQL or Amazon Relational Database Service (RDS) for structured data and transaction support
- NoSQL database, such as Azure Cosmos DB or Amazon DynamoDB for easy out-of-the-box horizontal scalability and global distribution
- Columnar data store, such as Azure Data Explorer or Amazon Redshift for high-performance time-series analysis
Before we decide which is a best fit, let’s review each option pretending we had no other options available and see how we would have made it work (a typical case when we deal with legacy applications).
Storage Option 1 — SQL database
Given the required fields (Device Id, Timestamp, Value), we can start with the following data model:
CREATE TABLE IoTReadings (
DeviceId NVARCHAR(50) NOT NULL,
Timestamp DATETIME2 NOT NULL,
Value FLOAT NOT NULL,
PRIMARY KEY (DeviceId, Timestamp) -- Composite key for efficient querying
);
Key note — Composite key
The composite key is essentially a clustered composite index. A composite index on (DeviceId, Timestamp) enables the database to efficiently filter results based on both DeviceId and Timestamp together, and it is critical for optimizing the query above to “retrieve all readings for a specific device for the past hour”. Let’s understand how the clustered index optimize the query!
When the composite index is created, the composite index organizes data by both DeviceId and Timestamp. Internally, it creates a sorted structure (e.g., a B-tree in relational databases) where: the first key (DeviceId) is the primary grouping, and within each group of DeviceId, the rows are sorted by Timestamp. This allows the query to quickly get to the primary group and quickly find the timestamps within the range (past hour, now) because timestamp is already sorted.
Here is a step by step breakdown when we have a composite index on (DeviceId, Timestamp):
- The database uses the index to directly locate the subset of rows where DeviceId = ‘abc’.
- Because the index also sorts data by Timestamp within the above subset of rows, the query engine can quickly filter rows that meet the Timestamp >= past hour condition. Think of binary search!
On the contrary, if no composite index exists, the database must search the entire table for rows where DeviceId = ‘abc’, and for all matching rows, scan through all their corresponding timestamps to filter those in the past hour. This results in a full table scan. Even if indexing is created on DeviceId, the timestamp is not sorted, the query would require a scan of all readings where DeviceId = ‘abc’.
A side question to you: does the order of columns in a composite index matter? Take a 10 seconds pause and think about it briefly!
The answer is yes, the order of columns in a composite index matters because it determines how the indexed data is structured and how efficiently queries can be executed. A composite index on (DeviceId, Timestamp) is not the same as (Timestamp, DeviceId). The column listed first in the index (the leading column) determines how the data is grouped, and the second column determines how the data is sorted within the group.
A composite index on (DeviceId, Timestamp) is optimized for queries that filter by DeviceId first and optionally by Timestamp second, like the example query we have above. The database first narrows down rows by DeviceId. It then efficiently scans the Timestamp values within the group of rows where DeviceId = 'abc'. A composite index on (Timestamp, DeviceId) is optimized for queries that filter by Timestamp first, and optionally by DeviceId. In our case, we filter by DeviceId first. If we don’t know which one to prioritize, the rule of thumb should be to prioritize the column with higher cardinality (i.e., more unique values). In our case, we know we want to filter by DeviceId, so (DeviceId, Timestamp) is better.
Another follow up question: why clustered instead of non-clustered Index?
The primary difference between clustered and non-clustered is how data is physically stored.
A clustered index determines the physical order of the rows in the table, and each table can have only one clustered index because there should be one physical order of the rows. For example, if DeviceId is a clustered index, the rows in the table are stored in the order of DeviceId.
A non-clustered index is a separate structure that stores a sorted list of keys and a pointer (like a row ID or primary key) to the actual rows in the table. This allows the query engine to look up by a key -> a pointer -> actual row of data. Non-clustered indexes do not affect the physical order of the rows in the table. A table can have multiple non-clustered indexes for different query needs.
For our use case, we choose clustered composite index for the following primary reasons:
- Our query patterns favor it. Most of our queries filter by DeviceId and Timestamp. A clustered index would make these queries faster because the rows are physically stored in sorted order by DeviceId and then by Timestamp. For our queries with Timestamp range conditions (e.g., “past hour” or “last week”), the clustered index ensures rows are stored sequentially by timestamp too, making range query efficient.
- The composite key also uniquely identifies each row. In our use case, DeviceId + Timestamp is the primary way to uniquely identify rows, making it the clustered index is a natural choice. This eliminates the need for a separate primary key or clustered index. A device should NOT have two readings at the same timestamp.
- Large data volume and sequential write patterns. For timestamped IoT readings from devices, the table has a large number of rows and insertions happen sequentially by timestamp, a clustered index on DeviceId + Timestamp is efficient because new rows are appended in order.
Storage Option 2 — NoSQL database
Compared to the SQL database above, a NoSQL database operates differently when it comes to storing data, scaling, and indexing. That means designing a NoSQL data solution optimized for IoT data may require different considerations. There are many NoSQL offerings like AWS DynamoDB, Azure Cosmos DB, Apache Cassandra, etc.. In the following section, when database specific concept is required, we will use Azure Cosmos DB as an example and walk through the exercise. However, the high-level idea should apply to other NoSQL databases as well.
Data Modeling
NoSQL databases can store data in a document-oriented format. For the data schema, we can store data in JSON-like documents. A single document for our IoT readings may look like the document below:
{
"id": "abc-2024-12-18T12:34:56Z",
"DeviceId": "abc",
"Timestamp": "2024-12-18T12:34:56Z",
"Value": 23.5
}
We want to keep the document structure flat, so that accessing data properties won’t be nested. We also want to store each reading as a separate document, instead of storing multiple readings like an array in a single document because there can be unbounded amount of readings. This ensures scalability for large datasets.
Partitioning Strategy
NoSQL databases like Apache Cassandra and Azure Cosmos DB support partitioning right out-of-the-box. This means data is spread across different logical partitions (and also physical nodes) based on the partition key, which achieves horizontal scalability. Choosing the partition key is critical here. A proper partition key should have high cardinality in order to evenly spread data across different partitions, which ensures we can store lots of data as long as more physical nodes can be added. Another very important factor is that the partition key should be part of all (or almost all) common queries in order to access data directly from a specific partition. Cross partition queries should be avoided if possible, because they require reading data from multiple partitions and the results have to be joined together, resulting larger CPU usage and latency.
For our use case, we can use DeviceId as the partition key because:
- Queries often filter on DeviceId
- More importantly, using DeviceId ensures that all readings from the same device are stored in the same logical partition, minimizing cross-partition queries.
Indexing and Query Optimization
In our IoT solution, our top queries filter by a combination of fields (DeviceId + Timestamp). A composite index can improve performance similar to SQL database. Without them, the database may need to scan through more data than necessary. See more details on composite index in Microsoft documentation on Composite Indexes, or AWS documentation on secondary index. A composite index ensures that the combination of DeviceId and Timestamp is indexed together, enabling efficient range queries. For example, it can be created by indexing policy like below using Azure Cosmos DB for demonstration purpose:
{
"indexingPolicy": {
"compositeIndexes": [
[
{"path": "/DeviceId", "order": "ascending"},
{"path": "/Timestamp", "order": "ascending"}
]
]
}
}
With DeviceId being the partition key and the composite index on DeviceId + Timestamp, we now have two benefits:
- Our top query can automatically be served by the correct partition, given a device id.
- The composite index on (DeviceId, Timestamp) optimizes the range scan on Timestamp for records from a specific device id.
Follow up question: what about Clustered vs. Non-Clustered Index
Well, NoSQL database does not have the same concept of clustered or non-clustered indexes as SQL database does. However, the two concepts roughly translate.
- Clustered Index Analogy: In NoSQL database, the physical storage of data is determined by the partition key. Using DeviceId as the partition key is equivalent to having clustered index on DeviceId because it determines how data is physically distributed / stored on database nodes.
- Non-Clustered Index Analogy: A composite index policy in NoSQL is similar to a non-clustered index in SQL. They provide an additional level of indexing without affecting the partitioning or physical storage order. Consider them as secondary indexes. AWS has a in-depth document on Secondary indexes in DynamoDB.
It is worth mentioning that a great feature supported by many NoSQL databases is the Time-to-Live (TTL) policy. It supports automatically delete old readings if they are no longer needed. For example, TTL policy to delete readings after 604800 seconds (7 days). For more information, see Microsoft Time to Live (TTL) in Azure Cosmos DB or AWS Using time to live (TTL) in DynamoDB.
{
"ttl": 604800
}
Storage Option 3 — Column data store
Column data store is a data store that store each column separately on disk. In a typical relational database, a row may contain multiple columns and data blocks store each row sequentially. In contrast, in a column data store, each data block may store a single column for many rows. See more details on how column data store works on AWS document Columnar storage or Azure document Columnar data stores.
Column data store optimized for analytic query performance, because in column-wise storage, a data block can store the values of a single column, which reduces the amount of data to load from disk when only a column is needed, and reduces the disk I/O.
There are many analytic data stores that are offered and leverages the columnar storage. One example is Azure Data Explorer (ADX). It is a fully managed analytics service optimized for querying large volumes of time-series data. In this blog, we will use ADX as an example to demonstrate how column data store may be well-suited for IoT scenarios. For more details on what is Azure Data Explorer, see Microsoft documentation What is Azure Data Explorer.
Data Modeling
For our use case, the IoT data for DeviceId, Timestamp, and Value can be stored in a table with a schema that using Kusto Query Language (KQL) looks like below. KQL is a query language on top of SQL that abstracts the complexity of analytic queries, especially for aggregations.
.create table IoTReadings (
DeviceId: string,
Timestamp: datetime,
Value: real
)
As mentioned above, Azure Data Explorer (ADX) uses columnar storage format as its primary data store. This storage format is highly efficient for analytical queries because only relevant columns are scanned for a query. It also allows compression algorithms to be more effective on columns with similar data types. In our case, the table has columns DeviceId, Timestamp, and Value, these columns are stored separately on disk.
Once data is ingested into Azure Data Explorer, it is immutable. This is very similar to append-only log that powers streaming platforms like Apache Kafka. This design ensures consistent performance for read-heavy workloads and simplifies data integrity. Under the hood, ADX uses Azure Blob Storage for storing raw data (cold storage).
Querying Data
Again, we will use Azure Data Explorer (ADX) as an example column data store for demonstration purpose. Other services have similar functionalities. Queries in ADX are written in Kusto Query Language (KQL), which can be considered a subset of SQL and is highly optimized for analytics. For our common read query to retrieve readings within the past hour for a device, KQL may look like:
IoTReadings
| where DeviceId == "abc"
| where Timestamp >= ago(1h)
| project DeviceId, Timestamp, Value
It is worth mentioning that the Kusto Query Language (KQL) is optimized to write query for analytics such as aggregation, filtering, moving averages, anomaly detection, etc.. In addition to the above query to retrieve data from the past hour, KQL makes it easy to compute aggregates (e.g., Average Reading per Minute). This groups data into 1-minute intervals and calculates the average value:
IoTReadings
| where DeviceId == "thermometer_123"
| where Timestamp >= ago(1h)
| summarize AvgValue=avg(Value) by bin(Timestamp, 1m)
Storage capacity considerations
Now that we have discussed the first two questions (storage mechanism and query optimization), let’s look at how we can handle the growing data volume and make sure our system is scalable to host the amount of data that we expect.
For our use case above, we have 3 columns and we can assume data sizes are:
- DeviceId: 36 bytes (UUID, or typical VARCHAR(36)).
- Timestamp: 8 bytes (e.g., DATETIME).
- Value: 4 bytes (e.g., FLOAT).
- Total: 36 + 8 + 4 = 48 bytes per record
On top of the base table storage, another important factor is the overhead of indexing. Because indexes store the index itself and the pointer to row identifiers, indexes require additional storage beyond the base table. For a composite B-tree index on (DeviceId, Timestamp), each index entry would contain: DeviceId(36 bytes) + Timestamp(8 bytes) = 44 bytes, plus the row pointer (assuming 8 bytes) = 52 bytes per entry.
For back of the envelope estimation, for a table with 1 billion rows:
- Raw data size: 48 bytes x 1 billion = 48 GBs
- Composite index size = 52 bytes x 1 billion = 52 GBs, which approximately doubles the table storage size from 48 GBs to 100 GBs.
The composite index on (DeviceId, Timestamp) will significantly improve query performance but requires additional storage. This is trading space for speed.
Now let’s look at overall data size. Assuming we have 10TB of base data, and 20% growth per year i.e., 2TB per year, which storage option above fits better in terms of storage capacity?
- SQL databases: SQL databases can handle terabytes of data, but because it does not support sharding out of the box, it may run into bottlenecks and require special attention to remain performant. For our IoT use case, it is possible to improve a SQL database by leveraging column-store index, which change the SQL database from row-store to column-store, and improves the storage efficiency by compression. This requires knowledge on both SQL and column store. For more information on how to use column store index in SQL database, see Columnstore indexes: Overview. Scaling can be a big challenge for SQL databases. Using Azure SQL as an example, while Azure SQL can scale vertically, handling 5TB+ growing data could require horizontal partitioning or scaling out, which is not automatic and requires additional attention. At the time of this article, Azure SQL has a storage limit at TB magnitude, and even the business critical tier has storage limit of 16 TB, per the documentation on Max instance storage size (reserved). 16 TB can easily be a limiting factor if our database is at already at 10TB scale.
- NoSQL databases: In theory, NoSQL databases should support unlimited storage with its automatic partitioning system. For example, each partition can store up to 20GB (for Cosmos DB), and the system automatically scales out by adding more partitions as data grows. For 10TB of data, this translates to 500 partitions. See more details in Azure Cosmos DB service quotas. Another factor to consider is cost. Cosmos DB may have higher costs, particularly for high-throughput ingestion and queries, because such high ingestion workloads require significant RU provisioning and may increase costs rapidly.
- Column data stores: Using Azure Data Explorer (ADX) as an example, under the hood, ADX persists data in Azure Blob storage, which theoretically does not have a physical limit on the amount of data that can be stored. ADX can have 1,000 instances per cluster. Assuming each instance may have SSD of 4TB, each cluster can handle 4PB of data (1000 x 4TB). With the compression ratio being 10X, effectively each cluster can handle 40PB of data. Technically, this is hot cache in ADX, which is the recent data kept in memory. Cold data is stored in blob storage and the cost is a lot cheaper. See more details in Azure Data Explorer limits. This means ADX has the capacity to support the growing volume of data and also the storage cost in ADX is relatively less expensive.
Based on the comparison, I think column data stores should be the best fit from the perspective of storage capacity, storage cost, and query performance for historical and real-time data.
Bonus question: Data Visualization
Column data stores provide built-in support to integrate with visualization tools like Grafana (which I personally think is one of the best off-the-shelf visualization platform on the market). For example, Azure Data Explorer supports analytics through Kusto Query Language (KQL) and visualization integration with external tools like Power BI and Grafana, see Visualize data from Azure Data Explorer in Grafana. AWS Redshift can integrate with Grafana using a plugin, see AWS Using the Amazon Redshift data source.
Summary
A column data store is an ideal choice for the discussed IoT use case because of its capability to handle a large volume of time-series data. Columnar storage ensures optimal performance for querying both real-time and historical data. Additionally, column data store is cost-effective in terms of storage cost. It also easily integrates with real-time visualization tools like Grafana, enabling businesses to extract actionable insights efficiently.
This is a long article!!! Thank you for staying with me and reading! Please give yourself a tap on the shoulder!!
References
- Indexing policies in Azure Cosmos DB
- Improving data access with secondary indexes in DynamoDB
- Time to Live (TTL) in Azure Cosmos DB
- Using time to live (TTL) in AWS DynamoDB
- Azure Cosmos DB — Database for the AI Era
- AWS document Columnar storage
- Azure document Columnar data stores
- What is Azure Data Explorer
- Kusto Query Language (KQL) overview
- Columnstore indexes: Overview
- Max instance storage size (reserved).
- Azure Data Explorer limits.
- Azure Cosmos DB service quotas.
- Use Azure Data Explorer data in Power BI.
- Visualize data from Azure Data Explorer in Grafana.
- AWS Using the Amazon Redshift data source.
Top 3 Questions to Ask in Near Real-Time Data Solutions was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/h4gpmqT
via IFTTT


